 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSED-SFT: Selectively Encouraging Diversity in Supervised Fine-Tuning
Feb 07, 2026Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has emerged as the standard post-training paradigm for large language models (LLMs). However, the conventional SFT process, driven by Cross-Entropy (CE) loss, often induces mode collapse, where models over-concentrate on specific response patterns. This lack of distributional diversity severely restricts the exploration efficiency required for subsequent RL. While recent studies have attempted to improve SFT by replacing the CE loss, aiming to preserve diversity or refine the update policy, they fail to adequately balance diversity and accuracy, thereby yielding suboptimal performance after RL. To address the mode collapse problem, we propose SED-SFT, which adaptively encourages diversity based on the token exploration space. This framework introduces a selective entropy regularization term with a selective masking mechanism into the optimization objective. Extensive experiments across eight mathematical benchmarks demonstrate that SED-SFT significantly enhances generation diversity with a negligible computational overhead increase compared with CE loss, yielding average improvements of 2.06 and 1.20 points in subsequent RL performance over standard CE-based baselines on Llama-3.2-3B-Instruct and Qwen2.5-Math-7B-Instruct, respectively. The code is publicly available at https://github.com/pppa2019/SED-SFT
Beyond Binary Gender: Evaluating Gender-Inclusive Machine Translation with Ambiguous Attitude Words
Jul 23, 2024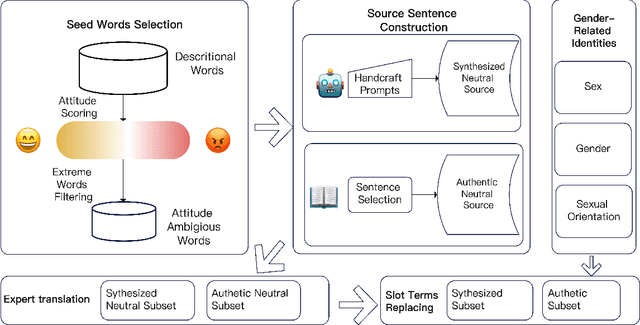

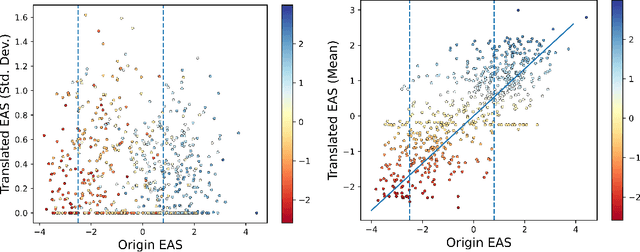

Gender bias has been a focal point in the study of bias in machine translation and language models. Existing machine translation gender bias evaluations are primarily focused on male and female genders, limiting the scope of the evaluation. To assess gender bias accurately, these studies often rely on calculating the accuracy of gender pronouns or the masculine and feminine attributes of grammatical gender via the stereotypes triggered by occupations or sentiment words ({\em i.e.}, clear positive or negative attitude), which cannot extend to non-binary groups. This study presents a benchmark AmbGIMT (Gender-Inclusive Machine Translation with Ambiguous attitude words), which assesses gender bias beyond binary gender. Meanwhile, we propose a novel process to evaluate gender bias based on the Emotional Attitude Score (EAS), which is used to quantify ambiguous attitude words. In evaluating three recent and effective open-source LLMs and one powerful multilingual translation-specific model, our main observations are: (1) The translation performance within non-binary gender contexts is markedly inferior in terms of translation quality and exhibits more negative attitudes than binary-gender contexts. (2) The analysis experiments indicate that incorporating constraint context in prompts for gender identity terms can substantially reduce translation bias, while the bias remains evident despite the presence of the constraints. The code is publicly available at \url{https://github.com/pppa2019/ambGIMT}.
Comments as Natural Logic Pivots: Improve Code Generation via Comment Perspective
Apr 11, 2024Code generation aims to understand the problem description and generate corresponding code snippets, where existing works generally decompose such complex tasks into intermediate steps by prompting strategies, such as Chain-of-Thought and its variants. While these studies have achieved some success, their effectiveness is highly dependent on the capabilities of advanced Large Language Models (LLMs) such as GPT-4, particularly in terms of API calls, which significantly limits their practical applicability. Consequently, how to enhance the code generation capabilities of small and medium-scale code LLMs without significantly increasing training costs is an appealing challenge. In this paper, we suggest that code comments are the natural logic pivot between natural language and code language and propose using comments to boost the code generation ability of code LLMs. Concretely, we propose MANGO (comMents As Natural loGic pivOts), including a comment contrastive training strategy and a corresponding logical comment decoding strategy. Experiments are performed on HumanEval and MBPP, utilizing StarCoder and WizardCoder as backbone models, and encompassing model parameter sizes between 3B and 7B. The results indicate that MANGO significantly improves the code pass rate based on the strong baselines. Meanwhile, the robustness of the logical comment decoding strategy is notably higher than the Chain-of-thoughts prompting. The code is publicly available at \url{https://github.com/pppa2019/Mango}.
Improving Translation Faithfulness of Large Language Models via Augmenting Instructions
Aug 24, 2023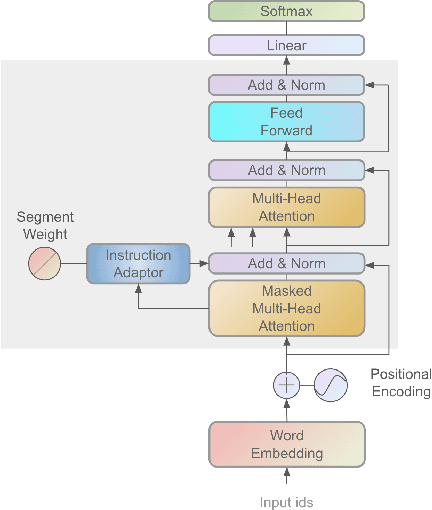


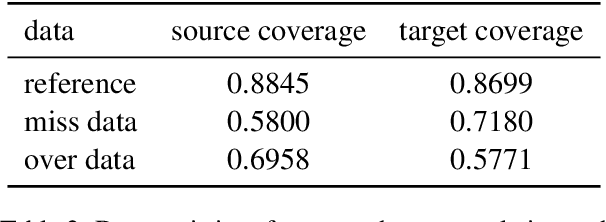
Large Language Models (LLMs) present strong general capabilities, and a current compelling challenge is stimulating their specialized capabilities, such as machine translation, through low-cost instruction tuning. The standard instruction-following data is sequentially organized as the concatenation of an instruction, an input, and a response. As the attention mechanism of LLMs has limitations on local focus, LLMs tend to focus more on the words or sentences nearby at each position. This leads to a high risk of instruction forgetting during decoding. To alleviate the above issues, We propose SWIE (Segment-Weighted Instruction Embedding) and an instruction-following dataset OVERMISS. SWIE improves the model instruction understanding by adding a global instruction representation on the following input and response representations. OVERMISS improves model faithfulness by comparing over-translation and miss-translation results with the correct translation. We apply our methods to two main-stream open-source LLMs, BLOOM and LLaMA. The experimental results demonstrate significant improvements in translation performance with SWIE based on BLOOMZ-3b, particularly in zero-shot and long text translations due to reduced instruction forgetting risk. Additionally, OVERMISS outperforms the baseline in translation performance (e.g. an increase in BLEU scores from 0.69 to 3.12 and an average improvement of 0.48 percentage comet scores for LLaMA-7b) with further enhancements seen in models combining OVERMISS and SWIE (e.g. the BLUE scores increase up to 0.56 from English to German across three different backbones), and both exhibit improvements in the faithfulness metric based on word alignment.
MSRL: Distributed Reinforcement Learning with Dataflow Fragments
Oct 03, 2022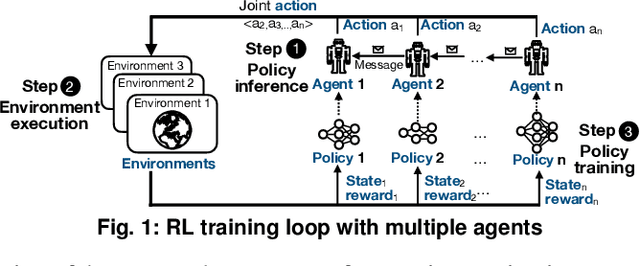
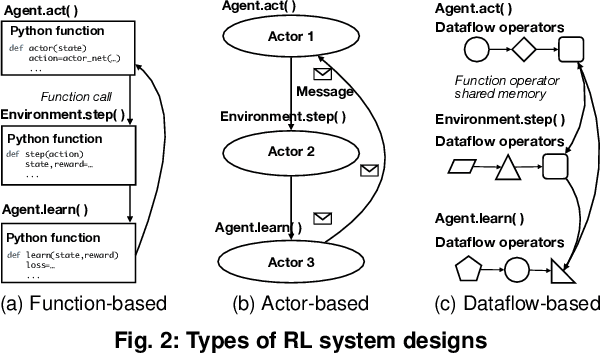
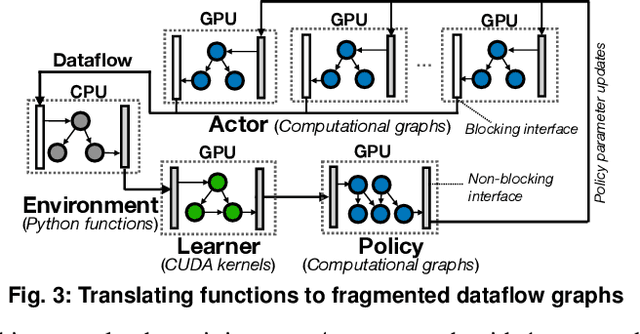
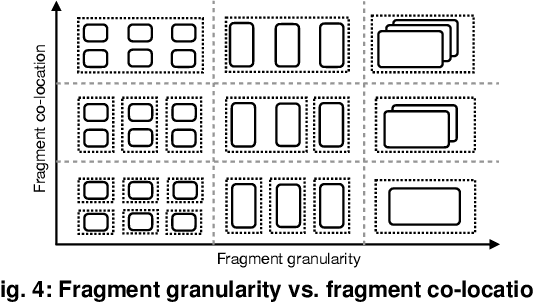
Reinforcement learning~(RL) trains many agents, which is resource-intensive and must scale to large GPU clusters. Different RL training algorithms offer different opportunities for distributing and parallelising the computation. Yet, current distributed RL systems tie the definition of RL algorithms to their distributed execution: they hard-code particular distribution strategies and only accelerate specific parts of the computation (e.g. policy network updates) on GPU workers. Fundamentally, current systems lack abstractions that decouple RL algorithms from their execution. We describe MindSpore Reinforcement Learning (MSRL), a distributed RL training system that supports distribution policies that govern how RL training computation is parallelised and distributed on cluster resources, without requiring changes to the algorithm implementation. MSRL introduces the new abstraction of a fragmented dataflow graph, which maps Python functions from an RL algorithm's training loop to parallel computational fragments. Fragments are executed on different devices by translating them to low-level dataflow representations, e.g. computational graphs as supported by deep learning engines, CUDA implementations or multi-threaded CPU processes. We show that MSRL subsumes the distribution strategies of existing systems, while scaling RL training to 64 GPUs.
Deep Level Set for Box-supervised Instance Segmentation in Aerial Images
Dec 07, 2021

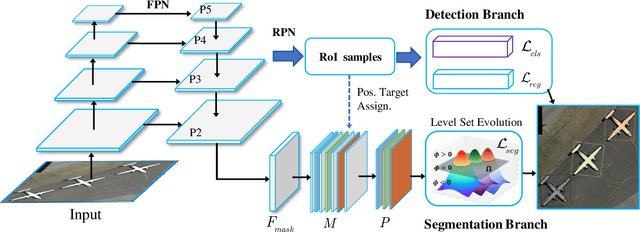

Box-supervised instance segmentation has recently attracted lots of research efforts while little attention is received in aerial image domain. In contrast to the general object collections, aerial objects have large intra-class variances and inter-class similarity with complex background. Moreover, there are many tiny objects in the high-resolution satellite images. This makes the recent pairwise affinity modeling method inevitably to involve the noisy supervision with the inferior results. To tackle these problems, we propose a novel aerial instance segmentation approach, which drives the network to learn a series of level set functions for the aerial objects with only box annotations in an end-to-end fashion. Instead of learning the pairwise affinity, the level set method with the carefully designed energy functions treats the object segmentation as curve evolution, which is able to accurately recover the object's boundaries and prevent the interference from the indistinguishable background and similar objects. The experimental results demonstrate that the proposed approach outperforms the state-of-the-art box-supervised instance segmentation methods. The source code is available at https://github.com/LiWentomng/boxlevelset.