 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Fluid: Large Language Models as Generalizable Neural Solvers for Fluid Dynamics
Jan 29, 2026Deep learning has emerged as a promising paradigm for spatio-temporal modeling of fluid dynamics. However, existing approaches often suffer from limited generalization to unseen flow conditions and typically require retraining when applied to new scenarios. In this paper, we present LLM4Fluid, a spatio-temporal prediction framework that leverages Large Language Models (LLMs) as generalizable neural solvers for fluid dynamics. The framework first compresses high-dimensional flow fields into a compact latent space via reduced-order modeling enhanced with a physics-informed disentanglement mechanism, effectively mitigating spatial feature entanglement while preserving essential flow structures. A pretrained LLM then serves as a temporal processor, autoregressively predicting the dynamics of physical sequences with time series prompts. To bridge the modality gap between prompts and physical sequences, which can otherwise degrade prediction accuracy, we propose a dedicated modality alignment strategy that resolves representational mismatch and stabilizes long-term prediction. Extensive experiments across diverse flow scenarios demonstrate that LLM4Fluid functions as a robust and generalizable neural solver without retraining, achieving state-of-the-art accuracy while exhibiting powerful zero-shot and in-context learning capabilities. Code and datasets are publicly available at https://github.com/qisongxiao/LLM4Fluid.
FlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
PhyGDPO: Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
Dec 31, 2025Recent advances in text-to-video (T2V) generation have achieved good visual quality, yet synthesizing videos that faithfully follow physical laws remains an open challenge. Existing methods mainly based on graphics or prompt extension struggle to generalize beyond simple simulated environments or learn implicit physical reasoning. The scarcity of training data with rich physics interactions and phenomena is also a problem. In this paper, we first introduce a Physics-Augmented video data construction Pipeline, PhyAugPipe, that leverages a vision-language model (VLM) with chain-of-thought reasoning to collect a large-scale training dataset, PhyVidGen-135K. Then we formulate a principled Physics-aware Groupwise Direct Preference Optimization, PhyGDPO, framework that builds upon the groupwise Plackett-Luce probabilistic model to capture holistic preferences beyond pairwise comparisons. In PhyGDPO, we design a Physics-Guided Rewarding (PGR) scheme that embeds VLM-based physics rewards to steer optimization toward physical consistency. We also propose a LoRA-Switch Reference (LoRA-SR) scheme that eliminates memory-heavy reference duplication for efficient training. Experiments show that our method significantly outperforms state-of-the-art open-source methods on PhyGenBench and VideoPhy2. Please check our project page at https://caiyuanhao1998.github.io/project/PhyGDPO for more video results. Our code, models, and data will be released at https://github.com/caiyuanhao1998/Open-PhyGDPO
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Dec 12, 2025Multimodal learning has rapidly advanced visual understanding, largely via multimodal large language models (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.
Prompt-A-Video: Prompt Your Video Diffusion Model via Preference-Aligned LLM
Dec 19, 2024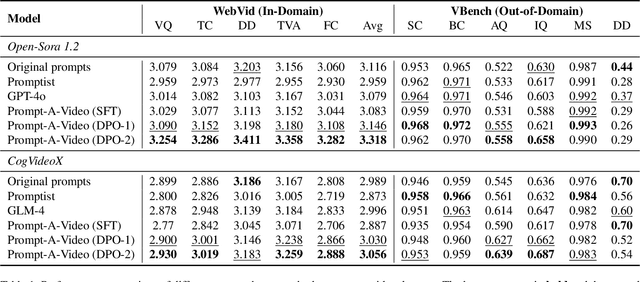

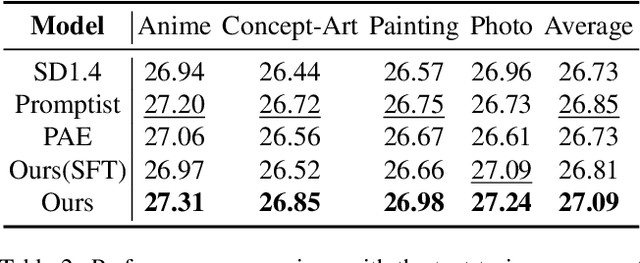

Text-to-video models have made remarkable advancements through optimization on high-quality text-video pairs, where the textual prompts play a pivotal role in determining quality of output videos. However, achieving the desired output often entails multiple revisions and iterative inference to refine user-provided prompts. Current automatic methods for refining prompts encounter challenges such as Modality-Inconsistency, Cost-Discrepancy, and Model-Unaware when applied to text-to-video diffusion models. To address these problem, we introduce an LLM-based prompt adaptation framework, termed as Prompt-A-Video, which excels in crafting Video-Centric, Labor-Free and Preference-Aligned prompts tailored to specific video diffusion model. Our approach involves a meticulously crafted two-stage optimization and alignment system. Initially, we conduct a reward-guided prompt evolution pipeline to automatically create optimal prompts pool and leverage them for supervised fine-tuning (SFT) of the LLM. Then multi-dimensional rewards are employed to generate pairwise data for the SFT model, followed by the direct preference optimization (DPO) algorithm to further facilitate preference alignment. Through extensive experimentation and comparative analyses, we validate the effectiveness of Prompt-A-Video across diverse generation models, highlighting its potential to push the boundaries of video generation.
OnlineVPO: Align Video Diffusion Model with Online Video-Centric Preference Optimization
Dec 19, 2024



In recent years, the field of text-to-video (T2V) generation has made significant strides. Despite this progress, there is still a gap between theoretical advancements and practical application, amplified by issues like degraded image quality and flickering artifacts. Recent advancements in enhancing the video diffusion model (VDM) through feedback learning have shown promising results. However, these methods still exhibit notable limitations, such as misaligned feedback and inferior scalability. To tackle these issues, we introduce OnlineVPO, a more efficient preference learning approach tailored specifically for video diffusion models. Our method features two novel designs, firstly, instead of directly using image-based reward feedback, we leverage the video quality assessment (VQA) model trained on synthetic data as the reward model to provide distribution and modality-aligned feedback on the video diffusion model. Additionally, we introduce an online DPO algorithm to address the off-policy optimization and scalability issue in existing video preference learning frameworks. By employing the video reward model to offer concise video feedback on the fly, OnlineVPO offers effective and efficient preference guidance. Extensive experiments on the open-source video-diffusion model demonstrate OnlineVPO as a simple yet effective and more importantly scalable preference learning algorithm for video diffusion models, offering valuable insights for future advancements in this domain.
IDA-VLM: Towards Movie Understanding via ID-Aware Large Vision-Language Model
Jul 10, 2024



The rapid advancement of Large Vision-Language models (LVLMs) has demonstrated a spectrum of emergent capabilities. Nevertheless, current models only focus on the visual content of a single scenario, while their ability to associate instances across different scenes has not yet been explored, which is essential for understanding complex visual content, such as movies with multiple characters and intricate plots. Towards movie understanding, a critical initial step for LVLMs is to unleash the potential of character identities memory and recognition across multiple visual scenarios. To achieve the goal, we propose visual instruction tuning with ID reference and develop an ID-Aware Large Vision-Language Model, IDA-VLM. Furthermore, our research introduces a novel benchmark MM-ID, to examine LVLMs on instance IDs memory and recognition across four dimensions: matching, location, question-answering, and captioning. Our findings highlight the limitations of existing LVLMs in recognizing and associating instance identities with ID reference. This paper paves the way for future artificial intelligence systems to possess multi-identity visual inputs, thereby facilitating the comprehension of complex visual narratives like movies.
ID-Aligner: Enhancing Identity-Preserving Text-to-Image Generation with Reward Feedback Learning
Apr 23, 2024



The rapid development of diffusion models has triggered diverse applications. Identity-preserving text-to-image generation (ID-T2I) particularly has received significant attention due to its wide range of application scenarios like AI portrait and advertising. While existing ID-T2I methods have demonstrated impressive results, several key challenges remain: (1) It is hard to maintain the identity characteristics of reference portraits accurately, (2) The generated images lack aesthetic appeal especially while enforcing identity retention, and (3) There is a limitation that cannot be compatible with LoRA-based and Adapter-based methods simultaneously. To address these issues, we present \textbf{ID-Aligner}, a general feedback learning framework to enhance ID-T2I performance. To resolve identity features lost, we introduce identity consistency reward fine-tuning to utilize the feedback from face detection and recognition models to improve generated identity preservation. Furthermore, we propose identity aesthetic reward fine-tuning leveraging rewards from human-annotated preference data and automatically constructed feedback on character structure generation to provide aesthetic tuning signals. Thanks to its universal feedback fine-tuning framework, our method can be readily applied to both LoRA and Adapter models, achieving consistent performance gains. Extensive experiments on SD1.5 and SDXL diffusion models validate the effectiveness of our approach. \textbf{Project Page: \url{https://idaligner.github.io/}}
Magic Clothing: Controllable Garment-Driven Image Synthesis
Apr 15, 2024



We propose Magic Clothing, a latent diffusion model (LDM)-based network architecture for an unexplored garment-driven image synthesis task. Aiming at generating customized characters wearing the target garments with diverse text prompts, the image controllability is the most critical issue, i.e., to preserve the garment details and maintain faithfulness to the text prompts. To this end, we introduce a garment extractor to capture the detailed garment features, and employ self-attention fusion to incorporate them into the pretrained LDMs, ensuring that the garment details remain unchanged on the target character. Then, we leverage the joint classifier-free guidance to balance the control of garment features and text prompts over the generated results. Meanwhile, the proposed garment extractor is a plug-in module applicable to various finetuned LDMs, and it can be combined with other extensions like ControlNet and IP-Adapter to enhance the diversity and controllability of the generated characters. Furthermore, we design Matched-Points-LPIPS (MP-LPIPS), a robust metric for evaluating the consistency of the target image to the source garment. Extensive experiments demonstrate that our Magic Clothing achieves state-of-the-art results under various conditional controls for garment-driven image synthesis. Our source code is available at https://github.com/ShineChen1024/MagicClothing.
OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on
Mar 07, 2024



We present OOTDiffusion, a novel network architecture for realistic and controllable image-based virtual try-on (VTON). We leverage the power of pretrained latent diffusion models, designing an outfitting UNet to learn the garment detail features. Without a redundant warping process, the garment features are precisely aligned with the target human body via the proposed outfitting fusion in the self-attention layers of the denoising UNet. In order to further enhance the controllability, we introduce outfitting dropout to the training process, which enables us to adjust the strength of the garment features through classifier-free guidance. Our comprehensive experiments on the VITON-HD and Dress Code datasets demonstrate that OOTDiffusion efficiently generates high-quality try-on results for arbitrary human and garment images, which outperforms other VTON methods in both realism and controllability, indicating an impressive breakthrough in virtual try-on. Our source code is available at https://github.com/levihsu/OOTDiffusion.