 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Interaction Trajectories Effective for Training Terminal Agents?
Jun 02, 2026Stronger code agents are commonly assumed to be superior teachers for post-training, yet this assumption remains poorly disentangled from task difficulty, harness design, and student capacity. We investigate this pedagogical link using Terminal-Lego, a scalable pipeline that transforms multi-domain real-world issues into environment-verified agentic tasks. Surprisingly, standalone performance does not dictate teaching efficacy: while Claude Opus 4.6 achieves higher scores on Terminal-Bench 2.0, students fine-tuned on trajectories from DeepSeek-V3.2, a lower-scoring agent, exhibit significantly stronger generalization. We attribute this "pedagogical paradox" to Environment-Grounded Supervision (EGS): trajectories that explicitly expose inspect-act-verify behaviors through harness-visible interactions allow students to internalize robust problem-solving routines rather than fragile action sequences. Scaling analysis reveals exceptional data efficiency: with only 15.3k Terminal-Lego trajectories, for example, Qwen3-32B achieves a 24.3% score on Terminal-Bench 2.0, rivaling previous SOTA performance established with over 30x the data volume. Our results suggest that the frontier of agent post-training lies beyond mere outcome-matching, shifting the focus toward "Harness Engineering", where the systematic design of environment-grounded interaction structures serves as the primary catalyst for reproducible and generalizable agentic intelligence.
CodeComp: Structural KV Cache Compression for Agentic Coding
Apr 11, 2026Agentic code tasks such as fault localization and patch generation require processing long codebases under tight memory constraints, where the Key-Value (KV) cache becomes the primary inference bottleneck. Existing compression methods rely exclusively on attention signals to estimate token importance, systematically discarding structurally critical tokens such as call sites, branch conditions, and assignments that are essential for code understanding. We present CodeComp, a training-free KV cache compression framework that incorporates static program analysis into LLM inference via Code Property Graph priors extracted by Joern. Across bug localization and code generation benchmarks, CodeComp consistently outperforms attention-only compression baselines under equal memory budgets, recovering the majority of full-context accuracy under aggressive KV cache compression, while matching the patch generation quality of uncompressed full-context inference and integrating seamlessly into SGLang-based agentic coding pipelines without model modification.
SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving
Jan 07, 2026We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
DnLUT: Ultra-Efficient Color Image Denoising via Channel-Aware Lookup Tables
Mar 20, 2025While deep neural networks have revolutionized image denoising capabilities, their deployment on edge devices remains challenging due to substantial computational and memory requirements. To this end, we present DnLUT, an ultra-efficient lookup table-based framework that achieves high-quality color image denoising with minimal resource consumption. Our key innovation lies in two complementary components: a Pairwise Channel Mixer (PCM) that effectively captures inter-channel correlations and spatial dependencies in parallel, and a novel L-shaped convolution design that maximizes receptive field coverage while minimizing storage overhead. By converting these components into optimized lookup tables post-training, DnLUT achieves remarkable efficiency - requiring only 500KB storage and 0.1% energy consumption compared to its CNN contestant DnCNN, while delivering 20X faster inference. Extensive experiments demonstrate that DnLUT outperforms all existing LUT-based methods by over 1dB in PSNR, establishing a new state-of-the-art in resource-efficient color image denoising. The project is available at https://github.com/Stephen0808/DnLUT.
IDA-VLM: Towards Movie Understanding via ID-Aware Large Vision-Language Model
Jul 10, 2024



The rapid advancement of Large Vision-Language models (LVLMs) has demonstrated a spectrum of emergent capabilities. Nevertheless, current models only focus on the visual content of a single scenario, while their ability to associate instances across different scenes has not yet been explored, which is essential for understanding complex visual content, such as movies with multiple characters and intricate plots. Towards movie understanding, a critical initial step for LVLMs is to unleash the potential of character identities memory and recognition across multiple visual scenarios. To achieve the goal, we propose visual instruction tuning with ID reference and develop an ID-Aware Large Vision-Language Model, IDA-VLM. Furthermore, our research introduces a novel benchmark MM-ID, to examine LVLMs on instance IDs memory and recognition across four dimensions: matching, location, question-answering, and captioning. Our findings highlight the limitations of existing LVLMs in recognizing and associating instance identities with ID reference. This paper paves the way for future artificial intelligence systems to possess multi-identity visual inputs, thereby facilitating the comprehension of complex visual narratives like movies.
Rolling Shutter Correction with Intermediate Distortion Flow Estimation
Apr 09, 2024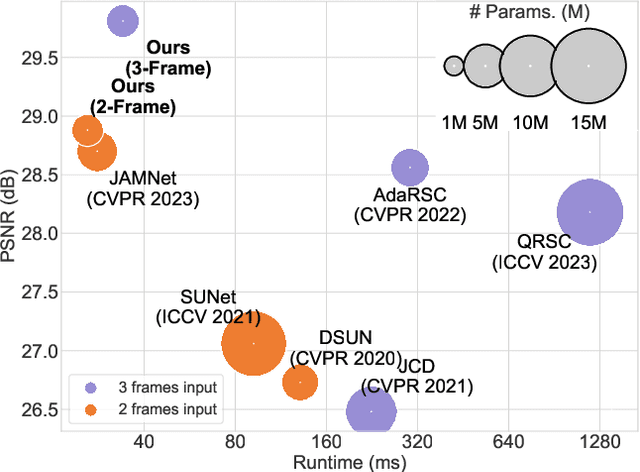
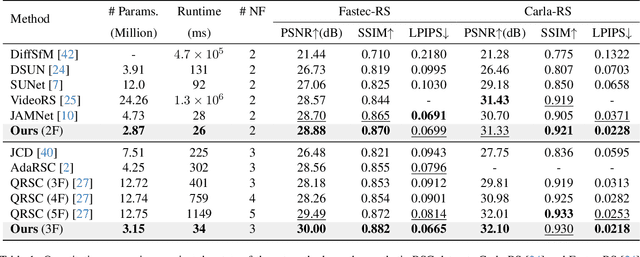
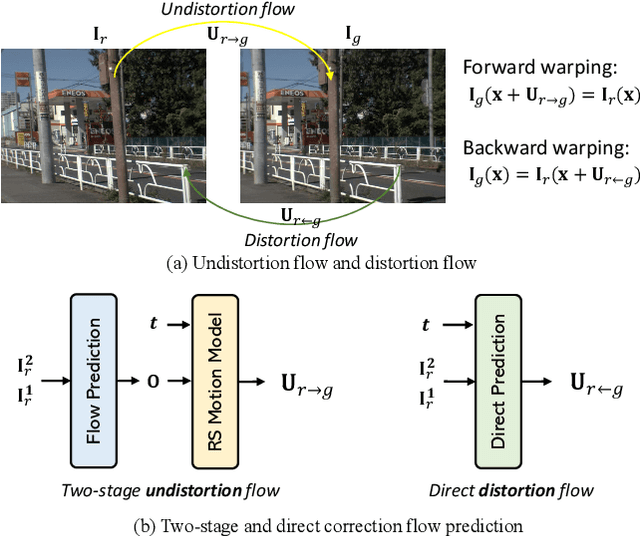
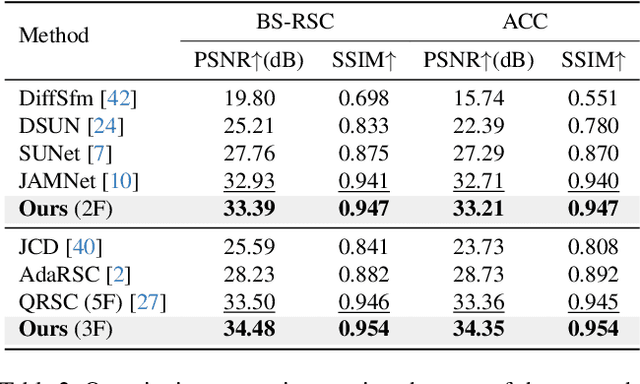
This paper proposes to correct the rolling shutter (RS) distorted images by estimating the distortion flow from the global shutter (GS) to RS directly. Existing methods usually perform correction using the undistortion flow from the RS to GS. They initially predict the flow from consecutive RS frames, subsequently rescaling it as the displacement fields from the RS frame to the underlying GS image using time-dependent scaling factors. Following this, RS-aware forward warping is employed to convert the RS image into its GS counterpart. Nevertheless, this strategy is prone to two shortcomings. First, the undistortion flow estimation is rendered inaccurate by merely linear scaling the flow, due to the complex non-linear motion nature. Second, RS-aware forward warping often results in unavoidable artifacts. To address these limitations, we introduce a new framework that directly estimates the distortion flow and rectifies the RS image with the backward warping operation. More specifically, we first propose a global correlation-based flow attention mechanism to estimate the initial distortion flow and GS feature jointly, which are then refined by the following coarse-to-fine decoder layers. Additionally, a multi-distortion flow prediction strategy is integrated to mitigate the issue of inaccurate flow estimation further. Experimental results validate the effectiveness of the proposed method, which outperforms state-of-the-art approaches on various benchmarks while maintaining high efficiency. The project is available at \url{https://github.com/ljzycmd/DFRSC}.
Taming Lookup Tables for Efficient Image Retouching
Mar 28, 2024The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.
Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network
Apr 22, 2022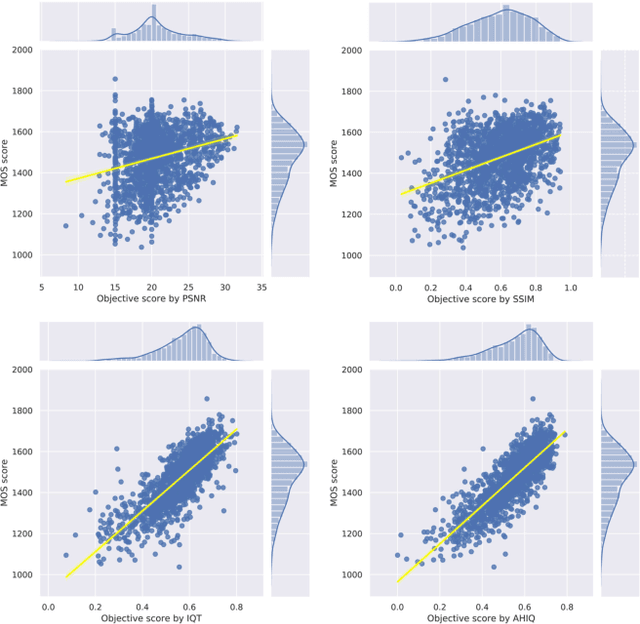

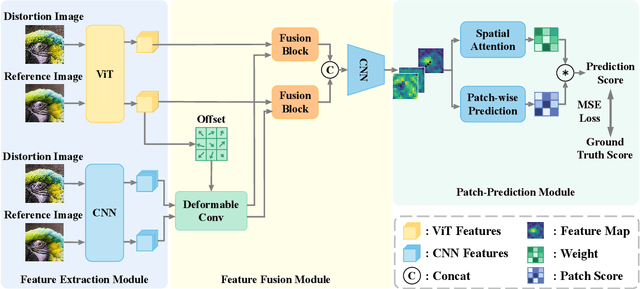
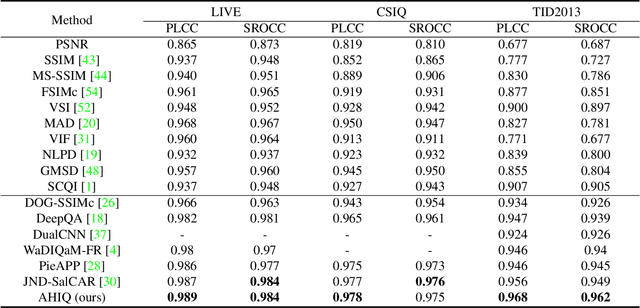
Image quality assessment (IQA) algorithm aims to quantify the human perception of image quality. Unfortunately, there is a performance drop when assessing the distortion images generated by generative adversarial network (GAN) with seemingly realistic texture. In this work, we conjecture that this maladaptation lies in the backbone of IQA models, where patch-level prediction methods use independent image patches as input to calculate their scores separately, but lack spatial relationship modeling among image patches. Therefore, we propose an Attention-based Hybrid Image Quality Assessment Network (AHIQ) to deal with the challenge and get better performance on the GAN-based IQA task. Firstly, we adopt a two-branch architecture, including a vision transformer (ViT) branch and a convolutional neural network (CNN) branch for feature extraction. The hybrid architecture combines interaction information among image patches captured by ViT and local texture details from CNN. To make the features from shallow CNN more focused on the visually salient region, a deformable convolution is applied with the help of semantic information from the ViT branch. Finally, we use a patch-wise score prediction module to obtain the final score. The experiments show that our model outperforms the state-of-the-art methods on four standard IQA datasets and AHIQ ranked first on the Full Reference (FR) track of the NTIRE 2022 Perceptual Image Quality Assessment Challenge.
MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment
Apr 21, 2022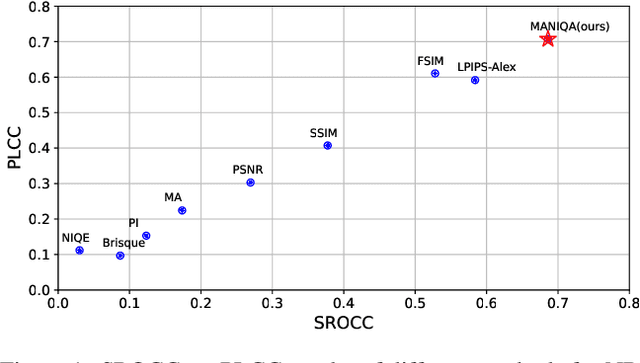
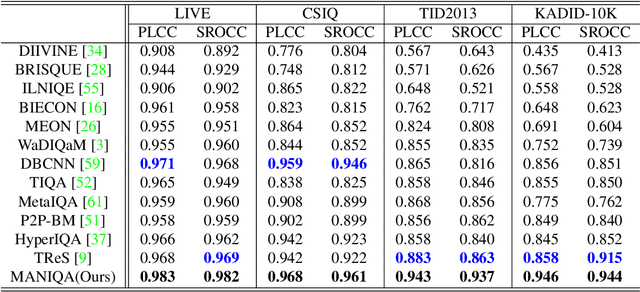
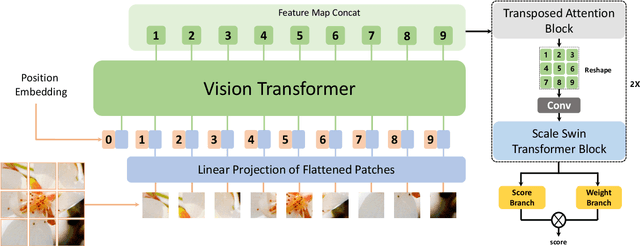
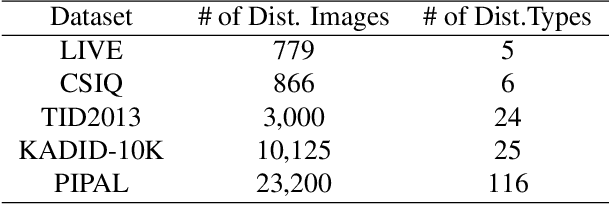
No-Reference Image Quality Assessment (NR-IQA) aims to assess the perceptual quality of images in accordance with human subjective perception. Unfortunately, existing NR-IQA methods are far from meeting the needs of predicting accurate quality scores on GAN-based distortion images. To this end, we propose Multi-dimension Attention Network for no-reference Image Quality Assessment (MANIQA) to improve the performance on GAN-based distortion. We firstly extract features via ViT, then to strengthen global and local interactions, we propose the Transposed Attention Block (TAB) and the Scale Swin Transformer Block (SSTB). These two modules apply attention mechanisms across the channel and spatial dimension, respectively. In this multi-dimensional manner, the modules cooperatively increase the interaction among different regions of images globally and locally. Finally, a dual branch structure for patch-weighted quality prediction is applied to predict the final score depending on the weight of each patch's score. Experimental results demonstrate that MANIQA outperforms state-of-the-art methods on four standard datasets (LIVE, TID2013, CSIQ, and KADID-10K) by a large margin. Besides, our method ranked first place in the final testing phase of the NTIRE 2022 Perceptual Image Quality Assessment Challenge Track 2: No-Reference. Codes and models are available at https://github.com/IIGROUP/MANIQA.