 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
Dec 24, 2025The "one-shot" technique represents a distinct and sophisticated aesthetic in filmmaking. However, its practical realization is often hindered by prohibitive costs and complex real-world constraints. Although emerging video generation models offer a virtual alternative, existing approaches typically rely on naive clip concatenation, which frequently fails to maintain visual smoothness and temporal coherence. In this paper, we introduce DreaMontage, a comprehensive framework designed for arbitrary frame-guided generation, capable of synthesizing seamless, expressive, and long-duration one-shot videos from diverse user-provided inputs. To achieve this, we address the challenge through three primary dimensions. (i) We integrate a lightweight intermediate-conditioning mechanism into the DiT architecture. By employing an Adaptive Tuning strategy that effectively leverages base training data, we unlock robust arbitrary-frame control capabilities. (ii) To enhance visual fidelity and cinematic expressiveness, we curate a high-quality dataset and implement a Visual Expression SFT stage. In addressing critical issues such as subject motion rationality and transition smoothness, we apply a Tailored DPO scheme, which significantly improves the success rate and usability of the generated content. (iii) To facilitate the production of extended sequences, we design a Segment-wise Auto-Regressive (SAR) inference strategy that operates in a memory-efficient manner. Extensive experiments demonstrate that our approach achieves visually striking and seamlessly coherent one-shot effects while maintaining computational efficiency, empowering users to transform fragmented visual materials into vivid, cohesive one-shot cinematic experiences.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
AR-Diffusion: Asynchronous Video Generation with Auto-Regressive Diffusion
Mar 10, 2025The task of video generation requires synthesizing visually realistic and temporally coherent video frames. Existing methods primarily use asynchronous auto-regressive models or synchronous diffusion models to address this challenge. However, asynchronous auto-regressive models often suffer from inconsistencies between training and inference, leading to issues such as error accumulation, while synchronous diffusion models are limited by their reliance on rigid sequence length. To address these issues, we introduce Auto-Regressive Diffusion (AR-Diffusion), a novel model that combines the strengths of auto-regressive and diffusion models for flexible, asynchronous video generation. Specifically, our approach leverages diffusion to gradually corrupt video frames in both training and inference, reducing the discrepancy between these phases. Inspired by auto-regressive generation, we incorporate a non-decreasing constraint on the corruption timesteps of individual frames, ensuring that earlier frames remain clearer than subsequent ones. This setup, together with temporal causal attention, enables flexible generation of videos with varying lengths while preserving temporal coherence. In addition, we design two specialized timestep schedulers: the FoPP scheduler for balanced timestep sampling during training, and the AD scheduler for flexible timestep differences during inference, supporting both synchronous and asynchronous generation. Extensive experiments demonstrate the superiority of our proposed method, which achieves competitive and state-of-the-art results across four challenging benchmarks.
Weight-Inherited Distillation for Task-Agnostic BERT Compression
May 16, 2023Knowledge Distillation (KD) is a predominant approach for BERT compression. Previous KD-based methods focus on designing extra alignment losses for the student model to mimic the behavior of the teacher model. These methods transfer the knowledge in an indirect way. In this paper, we propose a novel Weight-Inherited Distillation (WID), which directly transfers knowledge from the teacher. WID does not require any additional alignment loss and trains a compact student by inheriting the weights, showing a new perspective of knowledge distillation. Specifically, we design the row compactors and column compactors as mappings and then compress the weights via structural re-parameterization. Experimental results on the GLUE and SQuAD benchmarks show that WID outperforms previous state-of-the-art KD-based baselines. Further analysis indicates that WID can also learn the attention patterns from the teacher model without any alignment loss on attention distributions.
Rethinking Knowledge Distillation via Cross-Entropy
Aug 22, 2022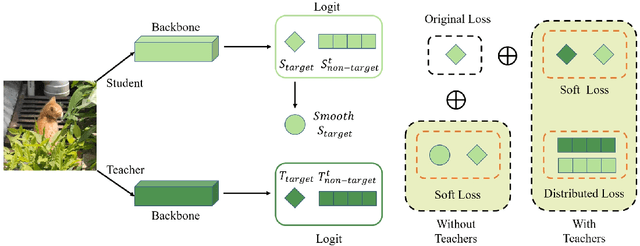
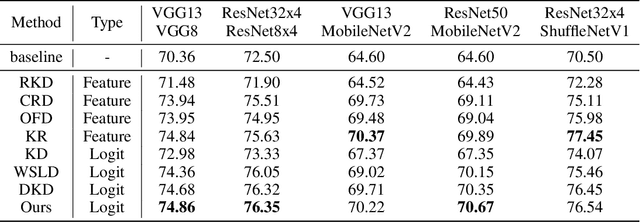
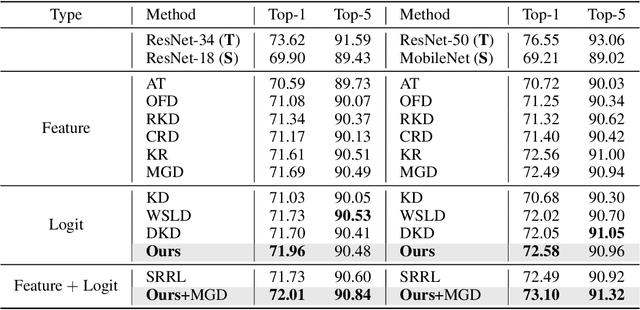
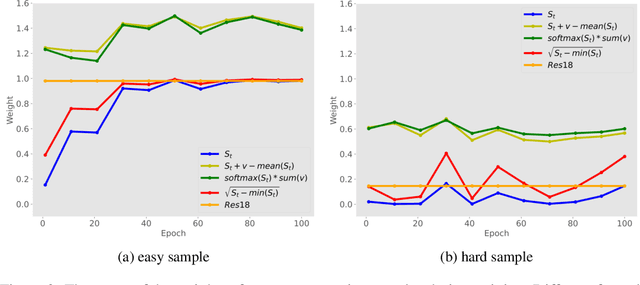
Knowledge Distillation (KD) has developed extensively and boosted various tasks. The classical KD method adds the KD loss to the original cross-entropy (CE) loss. We try to decompose the KD loss to explore its relation with the CE loss. Surprisingly, we find it can be regarded as a combination of the CE loss and an extra loss which has the identical form as the CE loss. However, we notice the extra loss forces the student's relative probability to learn the teacher's absolute probability. Moreover, the sum of the two probabilities is different, making it hard to optimize. To address this issue, we revise the formulation and propose a distributed loss. In addition, we utilize teachers' target output as the soft target, proposing the soft loss. Combining the soft loss and the distributed loss, we propose a new KD loss (NKD). Furthermore, we smooth students' target output to treat it as the soft target for training without teachers and propose a teacher-free new KD loss (tf-NKD). Our method achieves state-of-the-art performance on CIFAR-100 and ImageNet. For example, with ResNet-34 as the teacher, we boost the ImageNet Top-1 accuracy of ResNet18 from 69.90% to 71.96%. In training without teachers, MobileNet, ResNet-18 and SwinTransformer-Tiny achieve 70.04%, 70.76%, and 81.48%, which are 0.83%, 0.86%, and 0.30% higher than the baseline, respectively. The code is available at https://github.com/yzd-v/cls_KD.
Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network
Apr 22, 2022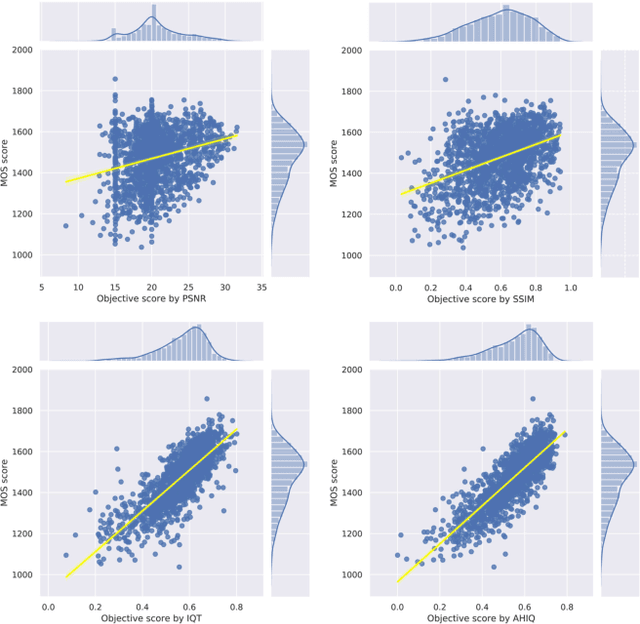

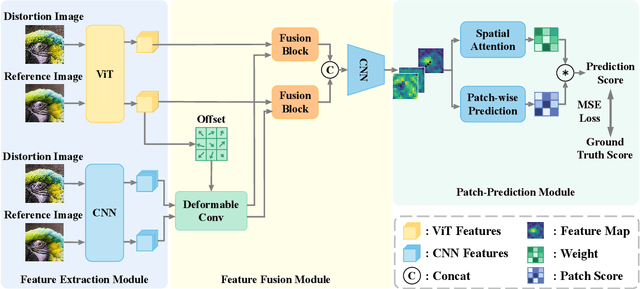
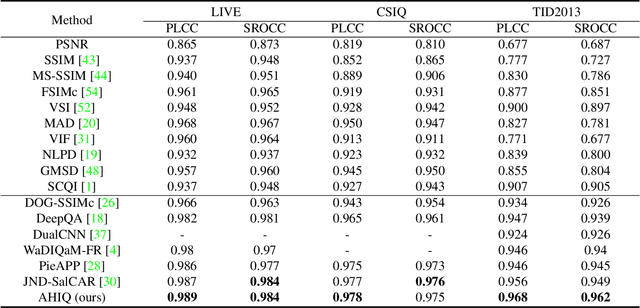
Image quality assessment (IQA) algorithm aims to quantify the human perception of image quality. Unfortunately, there is a performance drop when assessing the distortion images generated by generative adversarial network (GAN) with seemingly realistic texture. In this work, we conjecture that this maladaptation lies in the backbone of IQA models, where patch-level prediction methods use independent image patches as input to calculate their scores separately, but lack spatial relationship modeling among image patches. Therefore, we propose an Attention-based Hybrid Image Quality Assessment Network (AHIQ) to deal with the challenge and get better performance on the GAN-based IQA task. Firstly, we adopt a two-branch architecture, including a vision transformer (ViT) branch and a convolutional neural network (CNN) branch for feature extraction. The hybrid architecture combines interaction information among image patches captured by ViT and local texture details from CNN. To make the features from shallow CNN more focused on the visually salient region, a deformable convolution is applied with the help of semantic information from the ViT branch. Finally, we use a patch-wise score prediction module to obtain the final score. The experiments show that our model outperforms the state-of-the-art methods on four standard IQA datasets and AHIQ ranked first on the Full Reference (FR) track of the NTIRE 2022 Perceptual Image Quality Assessment Challenge.
MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment
Apr 21, 2022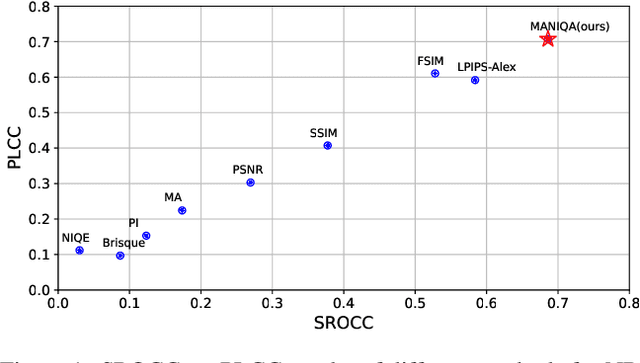
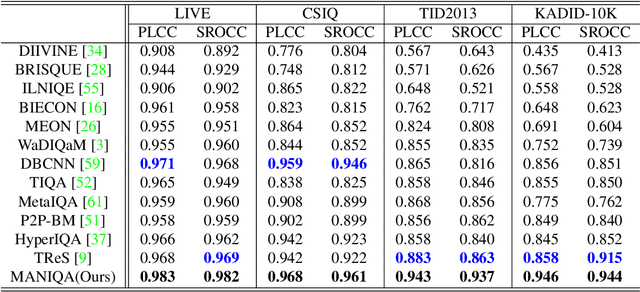
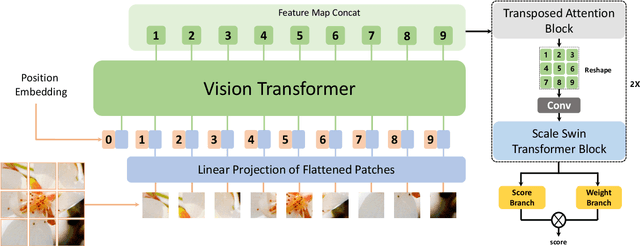
No-Reference Image Quality Assessment (NR-IQA) aims to assess the perceptual quality of images in accordance with human subjective perception. Unfortunately, existing NR-IQA methods are far from meeting the needs of predicting accurate quality scores on GAN-based distortion images. To this end, we propose Multi-dimension Attention Network for no-reference Image Quality Assessment (MANIQA) to improve the performance on GAN-based distortion. We firstly extract features via ViT, then to strengthen global and local interactions, we propose the Transposed Attention Block (TAB) and the Scale Swin Transformer Block (SSTB). These two modules apply attention mechanisms across the channel and spatial dimension, respectively. In this multi-dimensional manner, the modules cooperatively increase the interaction among different regions of images globally and locally. Finally, a dual branch structure for patch-weighted quality prediction is applied to predict the final score depending on the weight of each patch's score. Experimental results demonstrate that MANIQA outperforms state-of-the-art methods on four standard datasets (LIVE, TID2013, CSIQ, and KADID-10K) by a large margin. Besides, our method ranked first place in the final testing phase of the NTIRE 2022 Perceptual Image Quality Assessment Challenge Track 2: No-Reference. Codes and models are available at https://github.com/IIGROUP/MANIQA.