 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Preference: Aligning Diffusion Models to Fine-grained Criteria by Decoupling Attributes
Jan 07, 2026Post-training alignment of diffusion models relies on simplified signals, such as scalar rewards or binary preferences. This limits alignment with complex human expertise, which is hierarchical and fine-grained. To address this, we first construct a hierarchical, fine-grained evaluation criteria with domain experts, which decomposes image quality into multiple positive and negative attributes organized in a tree structure. Building on this, we propose a two-stage alignment framework. First, we inject domain knowledge to an auxiliary diffusion model via Supervised Fine-Tuning. Second, we introduce Complex Preference Optimization (CPO) that extends DPO to align the target diffusion to our non-binary, hierarchical criteria. Specifically, we reformulate the alignment problem to simultaneously maximize the probability of positive attributes while minimizing the probability of negative attributes with the auxiliary diffusion. We instantiate our approach in the domain of painting generation and conduct CPO training with an annotated dataset of painting with fine-grained attributes based on our criteria. Extensive experiments demonstrate that CPO significantly enhances generation quality and alignment with expertise, opening new avenues for fine-grained criteria alignment.
Breaking the Memory Wall: Exact Analytical Differentiation via Tiled Operator-Space Evolution
Dec 28, 2025Selective State Space Models (SSMs) achieve linear-time inference, yet their gradient-based sensitivity analysis remains bottlenecked by O(L) memory scaling during backpropagation. This memory constraint precludes genomic-scale modeling (L > 10^5) on consumer-grade hardware. We introduce Phase Gradient Flow (PGF), a framework that computes exact analytical derivatives by operating directly in the state-space manifold, bypassing the need to materialize the intermediate computational graph. By reframing SSM dynamics as Tiled Operator-Space Evolution (TOSE), our method delivers O(1) memory complexity relative to sequence length, yielding a 94% reduction in peak VRAM and a 23x increase in throughput compared to standard Autograd. Unlike parallel prefix scans that exhibit numerical divergence in stiff ODE regimes, PGF ensures stability through invariant error scaling, maintaining near-machine precision across extreme sequences. We demonstrate the utility of PGF on an impulse-response benchmark with 128,000-step sequences - a scale where conventional Autograd encounters prohibitive memory overhead, often leading to out-of-memory (OOM) failures in multi-layered models. Our work enables chromosome-scale sensitivity analysis on a single GPU, bridging the gap between theoretical infinite-context models and practical hardware limitations.
DreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
Dec 24, 2025The "one-shot" technique represents a distinct and sophisticated aesthetic in filmmaking. However, its practical realization is often hindered by prohibitive costs and complex real-world constraints. Although emerging video generation models offer a virtual alternative, existing approaches typically rely on naive clip concatenation, which frequently fails to maintain visual smoothness and temporal coherence. In this paper, we introduce DreaMontage, a comprehensive framework designed for arbitrary frame-guided generation, capable of synthesizing seamless, expressive, and long-duration one-shot videos from diverse user-provided inputs. To achieve this, we address the challenge through three primary dimensions. (i) We integrate a lightweight intermediate-conditioning mechanism into the DiT architecture. By employing an Adaptive Tuning strategy that effectively leverages base training data, we unlock robust arbitrary-frame control capabilities. (ii) To enhance visual fidelity and cinematic expressiveness, we curate a high-quality dataset and implement a Visual Expression SFT stage. In addressing critical issues such as subject motion rationality and transition smoothness, we apply a Tailored DPO scheme, which significantly improves the success rate and usability of the generated content. (iii) To facilitate the production of extended sequences, we design a Segment-wise Auto-Regressive (SAR) inference strategy that operates in a memory-efficient manner. Extensive experiments demonstrate that our approach achieves visually striking and seamlessly coherent one-shot effects while maintaining computational efficiency, empowering users to transform fragmented visual materials into vivid, cohesive one-shot cinematic experiences.
From Single to Societal: Analyzing Persona-Induced Bias in Multi-Agent Interactions
Nov 14, 2025



Large Language Model (LLM)-based multi-agent systems are increasingly used to simulate human interactions and solve collaborative tasks. A common practice is to assign agents with personas to encourage behavioral diversity. However, this raises a critical yet underexplored question: do personas introduce biases into multi-agent interactions? This paper presents a systematic investigation into persona-induced biases in multi-agent interactions, with a focus on social traits like trustworthiness (how an agent's opinion is received by others) and insistence (how strongly an agent advocates for its opinion). Through a series of controlled experiments in collaborative problem-solving and persuasion tasks, we reveal that (1) LLM-based agents exhibit biases in both trustworthiness and insistence, with personas from historically advantaged groups (e.g., men and White individuals) perceived as less trustworthy and demonstrating less insistence; and (2) agents exhibit significant in-group favoritism, showing a higher tendency to conform to others who share the same persona. These biases persist across various LLMs, group sizes, and numbers of interaction rounds, highlighting an urgent need for awareness and mitigation to ensure the fairness and reliability of multi-agent systems.
SAMPO:Scale-wise Autoregression with Motion PrOmpt for generative world models
Sep 19, 2025World models allow agents to simulate the consequences of actions in imagined environments for planning, control, and long-horizon decision-making. However, existing autoregressive world models struggle with visually coherent predictions due to disrupted spatial structure, inefficient decoding, and inadequate motion modeling. In response, we propose \textbf{S}cale-wise \textbf{A}utoregression with \textbf{M}otion \textbf{P}r\textbf{O}mpt (\textbf{SAMPO}), a hybrid framework that combines visual autoregressive modeling for intra-frame generation with causal modeling for next-frame generation. Specifically, SAMPO integrates temporal causal decoding with bidirectional spatial attention, which preserves spatial locality and supports parallel decoding within each scale. This design significantly enhances both temporal consistency and rollout efficiency. To further improve dynamic scene understanding, we devise an asymmetric multi-scale tokenizer that preserves spatial details in observed frames and extracts compact dynamic representations for future frames, optimizing both memory usage and model performance. Additionally, we introduce a trajectory-aware motion prompt module that injects spatiotemporal cues about object and robot trajectories, focusing attention on dynamic regions and improving temporal consistency and physical realism. Extensive experiments show that SAMPO achieves competitive performance in action-conditioned video prediction and model-based control, improving generation quality with 4.4$\times$ faster inference. We also evaluate SAMPO's zero-shot generalization and scaling behavior, demonstrating its ability to generalize to unseen tasks and benefit from larger model sizes.
MSGFusion: Multimodal Scene Graph-Guided Infrared and Visible Image Fusion
Sep 16, 2025



Infrared and visible image fusion has garnered considerable attention owing to the strong complementarity of these two modalities in complex, harsh environments. While deep learning-based fusion methods have made remarkable advances in feature extraction, alignment, fusion, and reconstruction, they still depend largely on low-level visual cues, such as texture and contrast, and struggle to capture the high-level semantic information embedded in images. Recent attempts to incorporate text as a source of semantic guidance have relied on unstructured descriptions that neither explicitly model entities, attributes, and relationships nor provide spatial localization, thereby limiting fine-grained fusion performance. To overcome these challenges, we introduce MSGFusion, a multimodal scene graph-guided fusion framework for infrared and visible imagery. By deeply coupling structured scene graphs derived from text and vision, MSGFusion explicitly represents entities, attributes, and spatial relations, and then synchronously refines high-level semantics and low-level details through successive modules for scene graph representation, hierarchical aggregation, and graph-driven fusion. Extensive experiments on multiple public benchmarks show that MSGFusion significantly outperforms state-of-the-art approaches, particularly in detail preservation and structural clarity, and delivers superior semantic consistency and generalizability in downstream tasks such as low-light object detection, semantic segmentation, and medical image fusion.
DualReg: Dual-Space Filtering and Reinforcement for Rigid Registration
Aug 23, 2025Rigid registration, aiming to estimate a rigid transformation to align source and target data, play a crucial role in applications such as SLAM and 3D reconstruction. However, noisy, partially overlapping data and the need for real-time processing pose major challenges for rigid registration. Considering that feature-based matching can handle large transformation differences but suffers from limited accuracy, while local geometry-based matching can achieve fine-grained local alignment but relies heavily on a good initial transformation, we propose a novel dual-space paradigm to fully leverage the strengths of both approaches. First, we introduce an efficient filtering mechanism that incorporates a computationally lightweight single-point RANSAC algorithm followed by a refinement module to eliminate unreliable feature-based correspondences. Subsequently, we treat filtered correspondences as anchor points, extract geometric proxies, and formulates an effective objective function with a tailored solver to estimate the transformation. Experiments verify our method's effectiveness, as shown by achieving up to a 32x CPU-time speedup over MAC on KITTI with comparable accuracy.
Exploring the Technical Knowledge Interaction of Global Digital Humanities: Three-decade Evidence from Bibliometric-based perspectives
Aug 11, 2025Digital Humanities (DH) is an interdisciplinary field that integrates computational methods with humanities scholarship to investigate innovative topics. Each academic discipline follows a unique developmental path shaped by the topics researchers investigate and the methods they employ. With the help of bibliometric analysis, most of previous studies have examined DH across multiple dimensions such as research hotspots, co-author networks, and institutional rankings. However, these studies have often been limited in their ability to provide deep insights into the current state of technological advancements and topic development in DH. As a result, their conclusions tend to remain superficial or lack interpretability in understanding how methods and topics interrelate in the field. To address this gap, this study introduced a new concept of Topic-Method Composition (TMC), which refers to a hybrid knowledge structure generated by the co-occurrence of specific research topics and the corresponding method. Especially by analyzing the interaction between TMCs, we can see more clearly the intersection and integration of digital technology and humanistic subjects in DH. Moreover, this study developed a TMC-based workflow combining bibliometric analysis, topic modeling, and network analysis to analyze the development characteristics and patterns of research disciplines. By applying this workflow to large-scale bibliometric data, it enables a detailed view of the knowledge structures, providing a tool adaptable to other fields.
Federated Multi-Objective Learning with Controlled Pareto Frontiers
Aug 07, 2025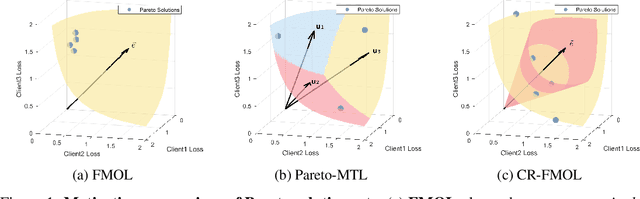


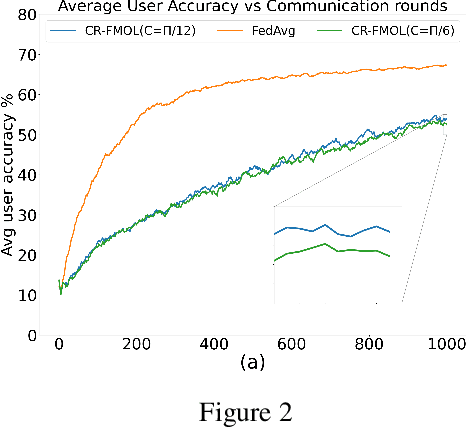
Federated learning (FL) is a widely adopted paradigm for privacy-preserving model training, but FedAvg optimise for the majority while under-serving minority clients. Existing methods such as federated multi-objective learning (FMOL) attempts to import multi-objective optimisation (MOO) into FL. However, it merely delivers task-wise Pareto-stationary points, leaving client fairness to chance. In this paper, we introduce Conically-Regularised FMOL (CR-FMOL), the first federated MOO framework that enforces client-wise Pareto optimality through a novel preference-cone constraint. After local federated multi-gradient descent averaging (FMGDA) / federated stochastic multi-gradient descent averaging (FSMGDA) steps, each client transmits its aggregated task-loss vector as an implicit preference; the server then solves a cone-constrained Pareto-MTL sub-problem centred at the uniform vector, producing a descent direction that is Pareto-stationary for every client within its cone. Experiments on non-IID benchmarks show that CR-FMOL enhances client fairness, and although the early-stage performance is slightly inferior to FedAvg, it is expected to achieve comparable accuracy given sufficient training rounds.
Object-Focus Actor for Data-efficient Robot Generalization Dexterous Manipulation
May 21, 2025Robot manipulation learning from human demonstrations offers a rapid means to acquire skills but often lacks generalization across diverse scenes and object placements. This limitation hinders real-world applications, particularly in complex tasks requiring dexterous manipulation. Vision-Language-Action (VLA) paradigm leverages large-scale data to enhance generalization. However, due to data scarcity, VLA's performance remains limited. In this work, we introduce Object-Focus Actor (OFA), a novel, data-efficient approach for generalized dexterous manipulation. OFA exploits the consistent end trajectories observed in dexterous manipulation tasks, allowing for efficient policy training. Our method employs a hierarchical pipeline: object perception and pose estimation, pre-manipulation pose arrival and OFA policy execution. This process ensures that the manipulation is focused and efficient, even in varied backgrounds and positional layout. Comprehensive real-world experiments across seven tasks demonstrate that OFA significantly outperforms baseline methods in both positional and background generalization tests. Notably, OFA achieves robust performance with only 10 demonstrations, highlighting its data efficiency.