 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection
Jan 14, 2026Supervised fine-tuning (SFT) is a fundamental post-training strategy to align Large Language Models (LLMs) with human intent. However, traditional SFT often ignores the one-to-many nature of language by forcing alignment with a single reference answer, leading to the model overfitting to non-core expressions. Although our empirical analysis suggests that introducing multiple reference answers can mitigate this issue, the prohibitive data and computational costs necessitate a strategic shift: prioritizing the mitigation of single-reference overfitting over the costly pursuit of answer diversity. To achieve this, we reveal the intrinsic connection between token probability and semantic importance: high-probability tokens carry the core logical framework, while low-probability tokens are mostly replaceable expressions. Based on this insight, we propose ProFit, which selectively masks low-probability tokens to prevent surface-level overfitting. Extensive experiments confirm that ProFit consistently outperforms traditional SFT baselines on general reasoning and mathematical benchmarks.
Shadow-FT: Tuning Instruct via Base
May 19, 2025Large language models (LLMs) consistently benefit from further fine-tuning on various tasks. However, we observe that directly tuning the INSTRUCT (i.e., instruction tuned) models often leads to marginal improvements and even performance degeneration. Notably, paired BASE models, the foundation for these INSTRUCT variants, contain highly similar weight values (i.e., less than 2% on average for Llama 3.1 8B). Therefore, we propose a novel Shadow-FT framework to tune the INSTRUCT models by leveraging the corresponding BASE models. The key insight is to fine-tune the BASE model, and then directly graft the learned weight updates to the INSTRUCT model. Our proposed Shadow-FT introduces no additional parameters, is easy to implement, and significantly improves performance. We conduct extensive experiments on tuning mainstream LLMs, such as Qwen 3 and Llama 3 series, and evaluate them across 19 benchmarks covering coding, reasoning, and mathematical tasks. Experimental results demonstrate that Shadow-FT consistently outperforms conventional full-parameter and parameter-efficient tuning approaches. Further analyses indicate that Shadow-FT can be applied to multimodal large language models (MLLMs) and combined with direct preference optimization (DPO). Codes and weights are available at \href{https://github.com/wutaiqiang/Shadow-FT}{Github}.
InfiJanice: Joint Analysis and In-situ Correction Engine for Quantization-Induced Math Degradation in Large Language Models
May 16, 2025



Large Language Models (LLMs) have demonstrated impressive performance on complex reasoning benchmarks such as GSM8K, MATH, and AIME. However, the substantial computational demands of these tasks pose significant challenges for real-world deployment. Model quantization has emerged as a promising approach to reduce memory footprint and inference latency by representing weights and activations with lower bit-widths. In this work, we conduct a comprehensive study of mainstream quantization methods(e.g., AWQ, GPTQ, SmoothQuant) on the most popular open-sourced models (e.g., Qwen2.5, LLaMA3 series), and reveal that quantization can degrade mathematical reasoning accuracy by up to 69.81%. To better understand this degradation, we develop an automated assignment and judgment pipeline that qualitatively categorizes failures into four error types and quantitatively identifies the most impacted reasoning capabilities. Building on these findings, we employ an automated data-curation pipeline to construct a compact "Silver Bullet" datasets. Training a quantized model on as few as 332 carefully selected examples for just 3-5 minutes on a single GPU is enough to restore its reasoning accuracy to match that of the full-precision baseline.
Quantization Meets Reasoning: Exploring LLM Low-Bit Quantization Degradation for Mathematical Reasoning
Jan 06, 2025
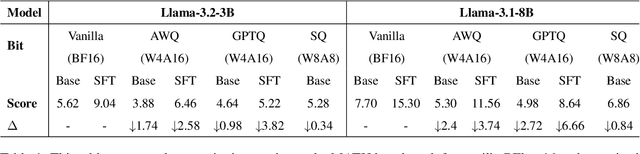


Large language models have achieved significant advancements in complex mathematical reasoning benchmarks, such as MATH. However, their substantial computational requirements present challenges for practical deployment. Model quantization has emerged as an effective strategy to reduce memory usage and computational costs by employing lower precision and bit-width representations. In this study, we systematically evaluate the impact of quantization on mathematical reasoning tasks. We introduce a multidimensional evaluation framework that qualitatively assesses specific capability dimensions and conduct quantitative analyses on the step-by-step outputs of various quantization methods. Our results demonstrate that quantization differentially affects numerical computation and reasoning planning abilities, identifying key areas where quantized models experience performance degradation.
LLM-Neo: Parameter Efficient Knowledge Distillation for Large Language Models
Nov 11, 2024In this paper, we propose a novel LLM-Neo framework that efficiently transfers knowledge from a large language model (LLM) teacher to a compact student. Initially, we revisit the knowledge distillation (KD) and low-rank adaption (LoRA), and argue that they share the same paradigm. Inspired by this observation, we explore the strategy that combines LoRA and KD to enhance the efficiency of knowledge transfer. We first summarize some guidelines for this design and further develop the LLM-Neo. Experimental results on compressing Llama 2 and Llama 3 show that LLM-Neo outperforms various baselines. Further analysis demonstrates the robustness of the proposed LLM-Neo on variants of LoRA. The trained models have been available at \href{https://huggingface.co/collections/yang31210999/llm-neo-66e3c882f5579b829ff57eba}{this repository}.
LoCa: Logit Calibration for Knowledge Distillation
Sep 07, 2024Knowledge Distillation (KD), aiming to train a better student model by mimicking the teacher model, plays an important role in model compression. One typical way is to align the output logits. However, we find a common issue named mis-instruction, that the student would be misled when the predictions based on teacher logits do not follow the labels. Meanwhile, there is other useful dark knowledge in the logits such as the class discriminability, which is vital for distillation. In this paper, we propose a simple yet effective Logit Calibration (LoCa) method, which calibrates the logits from the teacher model based on the ground-truth labels. The key insight is to correct the prediction (to address the mis-instruction issue) and maintain useful dark knowledge simultaneously. Our proposed LoCa does not require any additional parameters. Empirical results on image classification and text generation tasks demonstrate that LoCa can effectively improve the performance of baselines.