 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillRevise: Improving LLM-Authored Agent Skills via Trace-Conditioned Skill Revision
May 31, 2026Agent skills are procedural artifacts that enable LLM agents to execute workflows, verify constraints, and recover from failures. Existing self-evolving methods refine skills using accumulated trajectories. However, they struggle in cold-start settings, where only an initial, imperfect skill is available. Consequently, skill construction defaults to expert authoring or one-shot LLM generation. Expert-authored skills are costly and may not align with how LLM agents actually execute tasks, while one-shot generated skills can be syntactically well formed yet behaviorally weak. To bridge this gap, we propose SkillRevise, an execution-grounded framework designed to iteratively refine these initial skills. SkillRevise diagnoses skill defects from execution evidence, retrieves relevant repair principles from a general memory, and applies execution-anchored edits. By re-executing candidates and measuring empirical utility, it systematically retains the optimal skill version. Evaluated across three benchmarks and five LLMs, SkillRevise substantially outperforms one-shot baselines, improving the base agent's success rate on SkillsBench from 36.05% to 61.63%. Furthermore, the revised skills exhibit strong cross-model transferability, capturing generalized procedural knowledge over model-specific artifacts.
PatchWorld: Gradient-Free Optimization of Executable World Models
May 29, 2026Text-agent environments are typically modeled as partially observable Markov decision processes (POMDPs), assuming that the simulator's latent state and transition dynamics are hidden from the agent. Yet little work has examined whether executable code can be induced to serve as a world model for prediction and planning under partial observability. We introduce PatchWorld, a gradient-free framework that turns offline trajectories into executable Python world models through counterexample-guided code repair. Instead of predicting the next observation with a black-box model, PatchWorld induces symbolic belief-state programs whose action updates can be inspected, replayed, and locally patched. Across seven AgentGym environments, PatchWorld-Simple achieves the highest code-based planning score among evaluated methods, reaching 76.4\% macro success in live one-step lookahead while invoking no LLM calls inside the world-model prediction module itself. We further find that a human-specified residual-memory bias improves surface observation fidelity but weakens decision utility. This exposes a tradeoff in executable world models, since improving observation fidelity can come at the expense of action-discriminative dynamics, and vice versa. Code is available at https://github.com/HKBU-KnowComp/PatchWorld.
KGPFN: Unlocking the Potential of Knowledge Graph Foundation Model via In-Context Learning
May 14, 2026Knowledge graph (KG) foundation models aim to generalize across graphs with unseen entities and relations by learning transferable relational structure. However, most existing methods primarily emphasize relation-level universality, while in-context learning, the other pillar of foundation models remains under-explored for KG reasoning. In KGs, context is inherently structured and heterogeneous: effective prediction requires conditioning on the local context around the query entities as well as the global context that summarizes how a relation behaves across many instances. We propose KGPFN, a KG foundation model using Prior-data Fitted Network that unifies transferable relational regularities with inference-time in-context learning from structured context. KGPFN first learns relation representations via message passing on relation graphs to capture cross-graph relational invariances. For query-specific reasoning, it encodes local neighborhoods using a multi-layer NBFNet as local context. To enable ICL at global scale, it constructs relation-specific global context by retrieving a large set of instances of the query relation together with their local neighborhoods, and aggregates them within a Prior-Data Fitted Network framework that combines feature-level and sample-level attention. Through multi-graph pretraining on diverse KGs, KGPFN learns when to instantiate reusable patterns and when to override them using contextual evidence. Experiments on 57 KG benchmarks demonstrate that KGPFN achieves strong adaptation to previously unseen graphs through in-context learning alone, consistently outperforming competitive fine-tuned KG foundation models. Our code is available at https://github.com/HKUST-KnowComp/KGPFN.
MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
May 14, 2026Memory is essential for large vision-language models (LVLMs) to handle long, multimodal interactions, with two method directions providing this capability: long-context LVLMs and memory-augmented agents. However, no existing benchmark conducts a systematic comparison of the two on questions that genuinely require multimodal evidence. To close this gap, we introduce MEMLENS, a comprehensive benchmark for memory in multimodal multi-session conversations, comprising 789 questions across five memory abilities (information extraction, multi-session reasoning, temporal reasoning, knowledge update, and answer refusal) at four standard context lengths (32K-256K tokens) under a cross-modal token-counting scheme. An image-ablation study confirms that solving MEMLENS requires visual evidence: removing evidence images drops two frontier LVLMs below 2% accuracy on the 80.4% of questions whose evidence includes images. Evaluating 27 LVLMs and 7 memory-augmented agents, we find that long-context LVLMs achieve high short-context accuracy through direct visual grounding but degrade as conversations grow, whereas memory agents are length-stable but lose visual fidelity under storage-time compression. Multi-session reasoning caps most systems below 30%, and neither approach alone solves the task. These results motivate hybrid architectures that combine long-context attention with structured multimodal retrieval. Our code is available at https://github.com/xrenaf/MEMLENS.
DeepRefine: Agent-Compiled Knowledge Refinement via Reinforcement Learning
May 11, 2026Agent-compiled knowledge bases provide persistent external knowledge for large language model (LLM) agents in open-ended, knowledge-intensive downstream tasks. Yet their quality is systematically limited by \emph{incompleteness}, \emph{incorrectness}, and \emph{redundancy}, manifested as missing evidence or cross-document links, low-confidence or imprecise claims, and ambiguous or coreference resolution issues. Such defects compound under iterative use, degrading retrieval fidelity and downstream task performance. We present \textbf{DeepRefine}, a general LLM-based reasoning model for \emph{agent-compiled knowledge refinement} that improves the quality of any pre-constructed knowledge bases with user queries to make it more suitable for the downstream tasks. DeepRefine performs multi-turn interactions with the knowledge base and conducts abductive diagnosis over interaction history, localizes likely defects, and executes targeted refinement actions for incremental knowledge base updates. To optimize refinement policies of DeepRefine without gold references, we introduce a Gain-Beyond-Draft (GBD) reward and train the reasoning process end-to-end via reinforcement learning. Extensive experiments demonstrate consistent downstream gains over strong baselines.
NGDB-Zoo: Towards Efficient and Scalable Neural Graph Databases Training
Feb 25, 2026Neural Graph Databases (NGDBs) facilitate complex logical reasoning over incomplete knowledge structures, yet their training efficiency and expressivity are constrained by rigid query-level batching and structure-exclusive embeddings. We present NGDB-Zoo, a unified framework that resolves these bottlenecks by synergizing operator-level training with semantic augmentation. By decoupling logical operators from query topologies, NGDB-Zoo transforms the training loop into a dynamically scheduled data-flow execution, enabling multi-stream parallelism and achieving a $1.8\times$ - $6.8\times$ throughput compared to baselines. Furthermore, we formalize a decoupled architecture to integrate high-dimensional semantic priors from Pre-trained Text Encoders (PTEs) without triggering I/O stalls or memory overflows. Extensive evaluations on six benchmarks, including massive graphs like ogbl-wikikg2 and ATLAS-Wiki, demonstrate that NGDB-Zoo maintains high GPU utilization across diverse logical patterns and significantly mitigates representation friction in hybrid neuro-symbolic reasoning.
SpatialCrafter: Unleashing the Imagination of Video Diffusion Models for Scene Reconstruction from Limited Observations
May 17, 2025Novel view synthesis (NVS) boosts immersive experiences in computer vision and graphics. Existing techniques, though progressed, rely on dense multi-view observations, restricting their application. This work takes on the challenge of reconstructing photorealistic 3D scenes from sparse or single-view inputs. We introduce SpatialCrafter, a framework that leverages the rich knowledge in video diffusion models to generate plausible additional observations, thereby alleviating reconstruction ambiguity. Through a trainable camera encoder and an epipolar attention mechanism for explicit geometric constraints, we achieve precise camera control and 3D consistency, further reinforced by a unified scale estimation strategy to handle scale discrepancies across datasets. Furthermore, by integrating monocular depth priors with semantic features in the video latent space, our framework directly regresses 3D Gaussian primitives and efficiently processes long-sequence features using a hybrid network structure. Extensive experiments show our method enhances sparse view reconstruction and restores the realistic appearance of 3D scenes.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025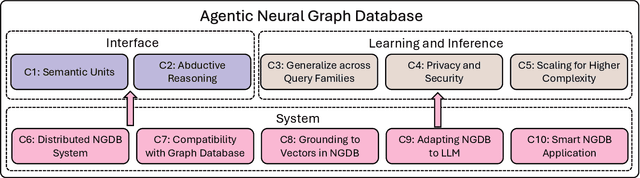
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Quantization Meets Reasoning: Exploring LLM Low-Bit Quantization Degradation for Mathematical Reasoning
Jan 06, 2025
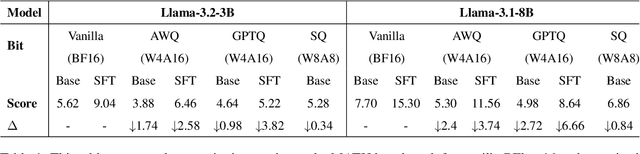


Large language models have achieved significant advancements in complex mathematical reasoning benchmarks, such as MATH. However, their substantial computational requirements present challenges for practical deployment. Model quantization has emerged as an effective strategy to reduce memory usage and computational costs by employing lower precision and bit-width representations. In this study, we systematically evaluate the impact of quantization on mathematical reasoning tasks. We introduce a multidimensional evaluation framework that qualitatively assesses specific capability dimensions and conduct quantitative analyses on the step-by-step outputs of various quantization methods. Our results demonstrate that quantization differentially affects numerical computation and reasoning planning abilities, identifying key areas where quantized models experience performance degradation.
Morpho-Aware Global Attention for Image Matting
Nov 15, 2024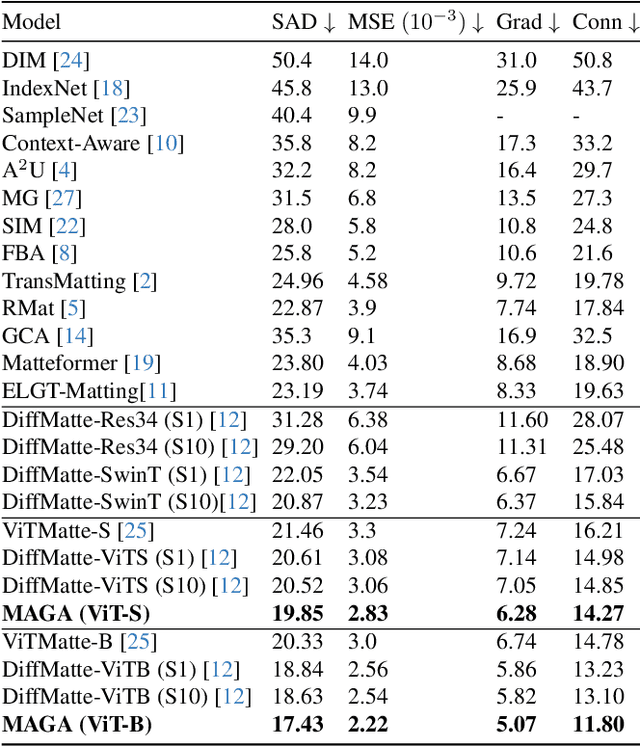
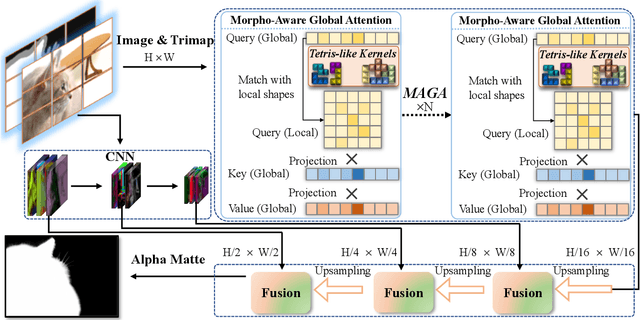
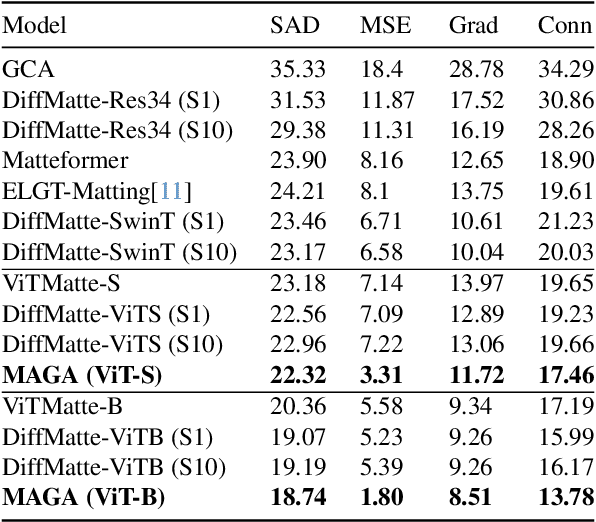
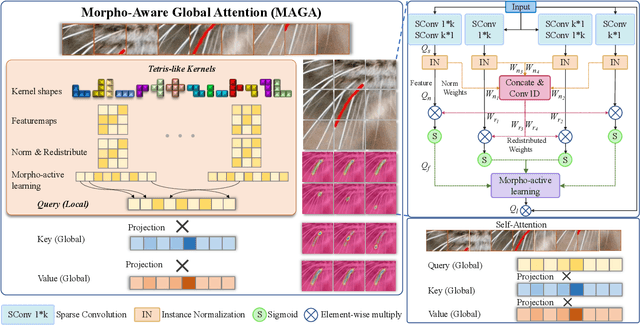
Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) face inherent challenges in image matting, particularly in preserving fine structural details. ViTs, with their global receptive field enabled by the self-attention mechanism, often lose local details such as hair strands. Conversely, CNNs, constrained by their local receptive field, rely on deeper layers to approximate global context but struggle to retain fine structures at greater depths. To overcome these limitations, we propose a novel Morpho-Aware Global Attention (MAGA) mechanism, designed to effectively capture the morphology of fine structures. MAGA employs Tetris-like convolutional patterns to align the local shapes of fine structures, ensuring optimal local correspondence while maintaining sensitivity to morphological details. The extracted local morphology information is used as query embeddings, which are projected onto global key embeddings to emphasize local details in a broader context. Subsequently, by projecting onto value embeddings, MAGA seamlessly integrates these emphasized morphological details into a unified global structure. This approach enables MAGA to simultaneously focus on local morphology and unify these details into a coherent whole, effectively preserving fine structures. Extensive experiments show that our MAGA-based ViT achieves significant performance gains, outperforming state-of-the-art methods across two benchmarks with average improvements of 4.3% in SAD and 39.5% in MSE.