 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning TFIDF Enhanced Joint Embedding for Recipe-Image Cross-Modal Retrieval Service
Paper and Code
Aug 02, 2021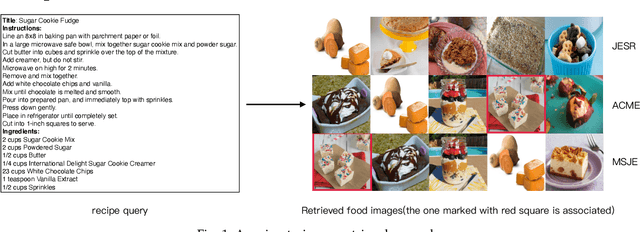

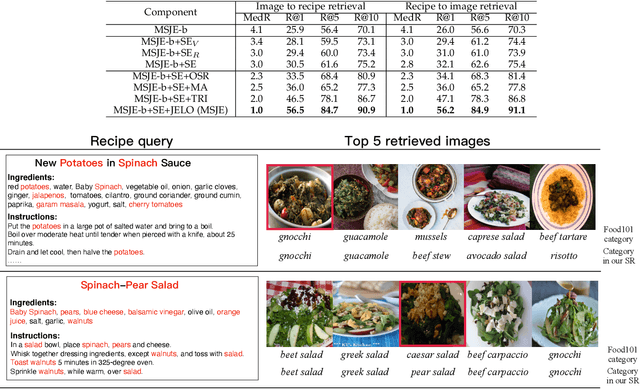
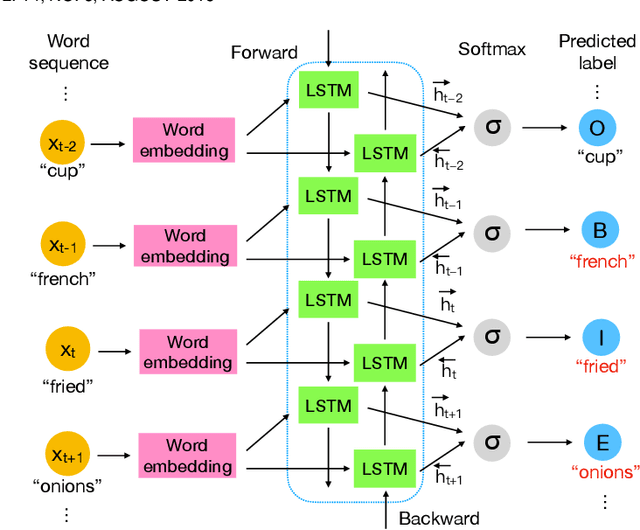
It is widely acknowledged that learning joint embeddings of recipes with images is challenging due to the diverse composition and deformation of ingredients in cooking procedures. We present a Multi-modal Semantics enhanced Joint Embedding approach (MSJE) for learning a common feature space between the two modalities (text and image), with the ultimate goal of providing high-performance cross-modal retrieval services. Our MSJE approach has three unique features. First, we extract the TFIDF feature from the title, ingredients and cooking instructions of recipes. By determining the significance of word sequences through combining LSTM learned features with their TFIDF features, we encode a recipe into a TFIDF weighted vector for capturing significant key terms and how such key terms are used in the corresponding cooking instructions. Second, we combine the recipe TFIDF feature with the recipe sequence feature extracted through two-stage LSTM networks, which is effective in capturing the unique relationship between a recipe and its associated image(s). Third, we further incorporate TFIDF enhanced category semantics to improve the mapping of image modality and to regulate the similarity loss function during the iterative learning of cross-modal joint embedding. Experiments on the benchmark dataset Recipe1M show the proposed approach outperforms the state-of-the-art approaches.