 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Dataset for Molecular Structure-Language Description via a Rule-Regularized Method
Feb 02, 2026Molecular function is largely determined by structure. Accurately aligning molecular structure with natural language is therefore essential for enabling large language models (LLMs) to reason about downstream chemical tasks. However, the substantial cost of human annotation makes it infeasible to construct large-scale, high-quality datasets of structure-grounded descriptions. In this work, we propose a fully automated annotation framework for generating precise molecular structure descriptions at scale. Our approach builds upon and extends a rule-based chemical nomenclature parser to interpret IUPAC names and construct enriched, structured XML metadata that explicitly encodes molecular structure. This metadata is then used to guide LLMs in producing accurate natural-language descriptions. Using this framework, we curate a large-scale dataset of approximately $163$k molecule-description pairs. A rigorous validation protocol combining LLM-based and expert human evaluation on a subset of $2,000$ molecules demonstrates a high description precision of $98.6\%$. The resulting dataset provides a reliable foundation for future molecule-language alignment, and the proposed annotation method is readily extensible to larger datasets and broader chemical tasks that rely on structural descriptions.
ASTIF: Adaptive Semantic-Temporal Integration for Cryptocurrency Price Forecasting
Dec 21, 2025Financial time series forecasting is fundamentally an information fusion challenge, yet most existing models rely on static architectures that struggle to integrate heterogeneous knowledge sources or adjust to rapid regime shifts. Conventional approaches, relying exclusively on historical price sequences, often neglect the semantic drivers of volatility such as policy uncertainty and market narratives. To address these limitations, we propose the ASTIF (Adaptive Semantic-Temporal Integration for Cryptocurrency Price Forecasting), a hybrid intelligent system that adapts its forecasting strategy in real time through confidence-based meta-learning. The framework integrates three complementary components. A dual-channel Small Language Model using MirrorPrompt extracts semantic market cues alongside numerical trends. A hybrid LSTM Random Forest model captures sequential temporal dependencies. A confidence-aware meta-learner functions as an adaptive inference layer, modulating each predictor's contribution based on its real-time uncertainty. Experimental evaluation on a diverse dataset of AI-focused cryptocurrencies and major technology stocks from 2020 to 2024 shows that ASTIF outperforms leading deep learning and Transformer baselines (e.g., Informer, TFT). The ablation studies further confirm the critical role of the adaptive meta-learning mechanism, which successfully mitigates risk by shifting reliance between semantic and temporal channels during market turbulence. The research contributes a scalable, knowledge-based solution for fusing quantitative and qualitative data in non-stationary environments.
Keep the Lights On, Keep the Lengths in Check: Plug-In Adversarial Detection for Time-Series LLMs in Energy Forecasting
Dec 13, 2025Accurate time-series forecasting is increasingly critical for planning and operations in low-carbon power systems. Emerging time-series large language models (TS-LLMs) now deliver this capability at scale, requiring no task-specific retraining, and are quickly becoming essential components within the Internet-of-Energy (IoE) ecosystem. However, their real-world deployment is complicated by a critical vulnerability: adversarial examples (AEs). Detecting these AEs is challenging because (i) adversarial perturbations are optimized across the entire input sequence and exploit global temporal dependencies, which renders local detection methods ineffective, and (ii) unlike traditional forecasting models with fixed input dimensions, TS-LLMs accept sequences of variable length, increasing variability that complicates detection. To address these challenges, we propose a plug-in detection framework that capitalizes on the TS-LLM's own variable-length input capability. Our method uses sampling-induced divergence as a detection signal. Given an input sequence, we generate multiple shortened variants and detect AEs by measuring the consistency of their forecasts: Benign sequences tend to produce stable predictions under sampling, whereas adversarial sequences show low forecast similarity, because perturbations optimized for a full-length sequence do not transfer reliably to shorter, differently-structured subsamples. We evaluate our approach on three representative TS-LLMs (TimeGPT, TimesFM, and TimeLLM) across three energy datasets: ETTh2 (Electricity Transformer Temperature), NI (Hourly Energy Consumption), and Consumption (Hourly Electricity Consumption and Production). Empirical results confirm strong and robust detection performance across both black-box and white-box attack scenarios, highlighting its practicality as a reliable safeguard for TS-LLM forecasting in real-world energy systems.
Rebellion: Noise-Robust Reasoning Training for Audio Reasoning Models
Nov 12, 2025Instilling reasoning capabilities in large models (LMs) using reasoning training (RT) significantly improves LMs' performances. Thus Audio Reasoning Models (ARMs), i.e., audio LMs that can reason, are becoming increasingly popular. However, no work has studied the safety of ARMs against jailbreak attacks that aim to elicit harmful responses from target models. To this end, first, we show that standard RT with appropriate safety reasoning data can protect ARMs from vanilla audio jailbreaks, but cannot protect them against our proposed simple yet effective jailbreaks. We show that this is because of the significant representation drift between vanilla and advanced jailbreaks which forces the target ARMs to emit harmful responses. Based on this observation, we propose Rebellion, a robust RT that trains ARMs to be robust to the worst-case representation drift. All our results are on Qwen2-Audio; they demonstrate that Rebellion: 1) can protect against advanced audio jailbreaks without compromising performance on benign tasks, and 2) significantly improves accuracy-safety trade-off over standard RT method.
FedHFT: Efficient Federated Finetuning with Heterogeneous Edge Clients
Oct 15, 2025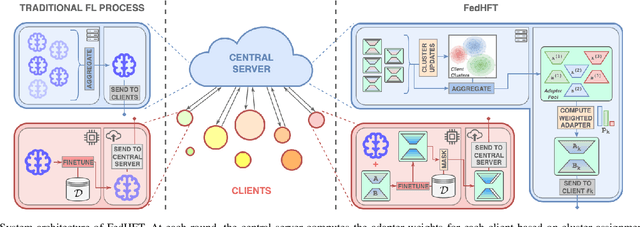
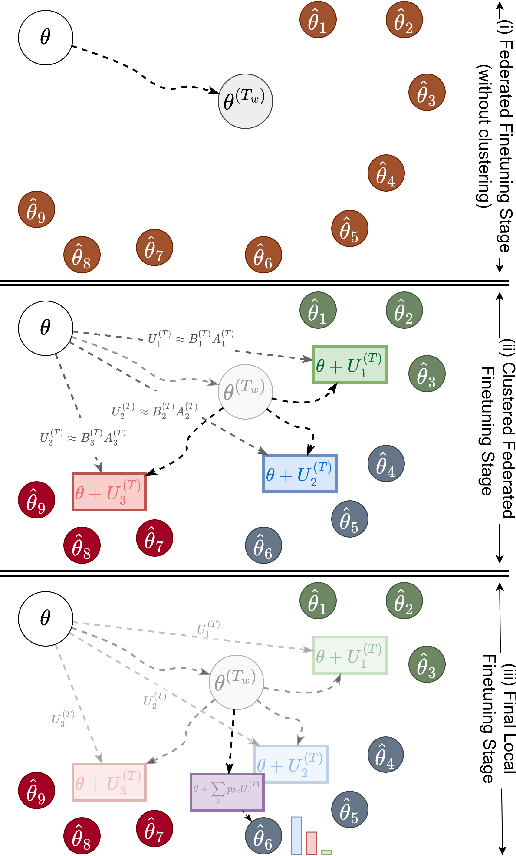
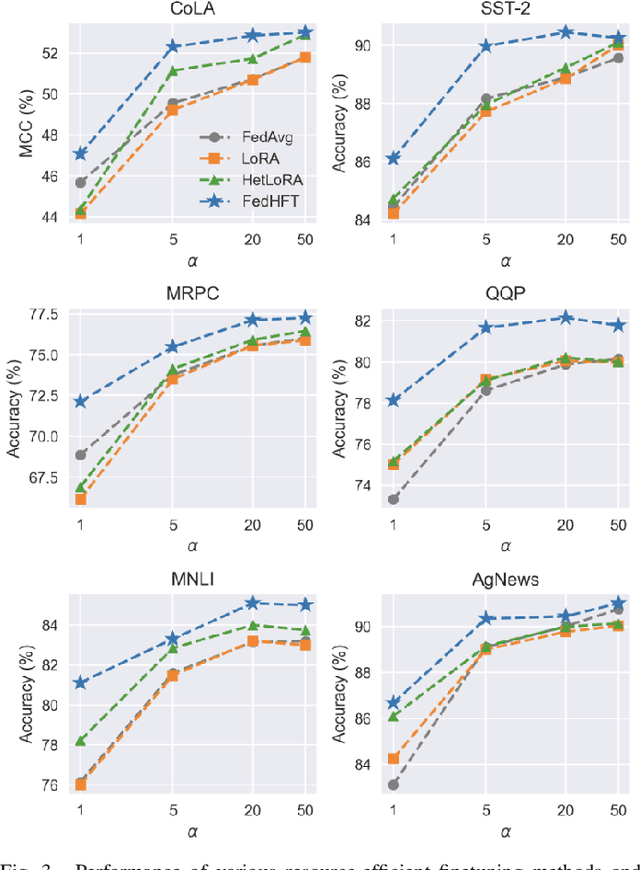
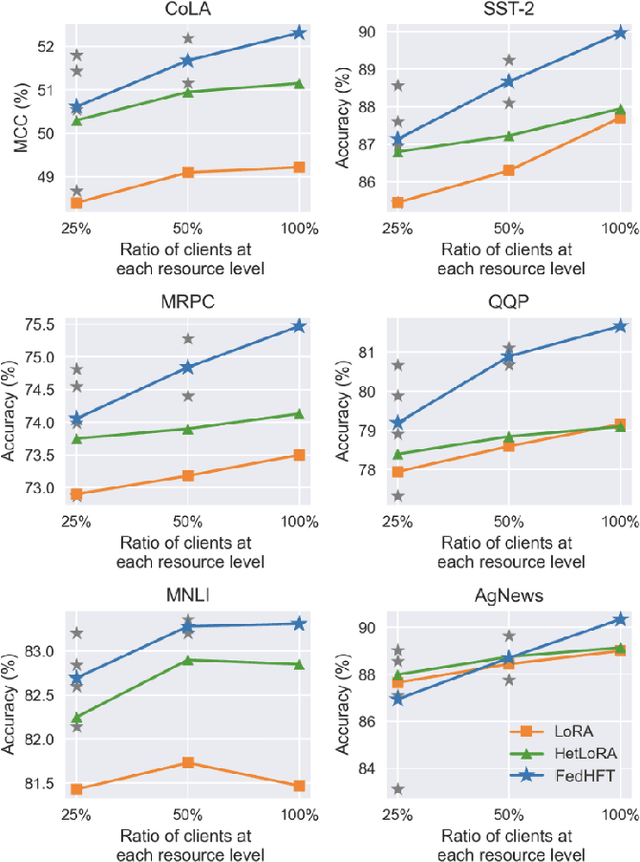
Fine-tuning pre-trained large language models (LLMs) has become a common practice for personalized natural language understanding (NLU) applications on downstream tasks and domain-specific datasets. However, there are two main challenges: (i) limited and/or heterogeneous data for fine-tuning due to proprietary data confidentiality or privacy requirements, and (ii) varying computation resources available across participating clients such as edge devices. This paper presents FedHFT - an efficient and personalized federated fine-tuning framework to address both challenges. First, we introduce a mixture of masked adapters to handle resource heterogeneity across participating clients, enabling high-performance collaborative fine-tuning of pre-trained language model(s) across multiple clients in a distributed setting, while keeping proprietary data local. Second, we introduce a bi-level optimization approach to handle non-iid data distribution based on masked personalization and client clustering. Extensive experiments demonstrate significant performance and efficiency improvements over various natural language understanding tasks under data and resource heterogeneity compared to representative heterogeneous federated learning methods.
When Graph Contrastive Learning Backfires: Spectral Vulnerability and Defense in Recommendation
Jul 10, 2025Graph Contrastive Learning (GCL) has demonstrated substantial promise in enhancing the robustness and generalization of recommender systems, particularly by enabling models to leverage large-scale unlabeled data for improved representation learning. However, in this paper, we reveal an unexpected vulnerability: the integration of GCL inadvertently increases the susceptibility of a recommender to targeted promotion attacks. Through both theoretical investigation and empirical validation, we identify the root cause as the spectral smoothing effect induced by contrastive optimization, which disperses item embeddings across the representation space and unintentionally enhances the exposure of target items. Building on this insight, we introduce CLeaR, a bi-level optimization attack method that deliberately amplifies spectral smoothness, enabling a systematic investigation of the susceptibility of GCL-based recommendation models to targeted promotion attacks. Our findings highlight the urgent need for robust countermeasures; in response, we further propose SIM, a spectral irregularity mitigation framework designed to accurately detect and suppress targeted items without compromising model performance. Extensive experiments on multiple benchmark datasets demonstrate that, compared to existing targeted promotion attacks, GCL-based recommendation models exhibit greater susceptibility when evaluated with CLeaR, while SIM effectively mitigates these vulnerabilities.
Language-Vision Planner and Executor for Text-to-Visual Reasoning
Jun 09, 2025The advancement in large language models (LLMs) and large vision models has fueled the rapid progress in multi-modal visual-text reasoning capabilities. However, existing vision-language models (VLMs) to date suffer from generalization performance. Inspired by recent development in LLMs for visual reasoning, this paper presents VLAgent, an AI system that can create a step-by-step visual reasoning plan with an easy-to-understand script and execute each step of the plan in real time by integrating planning script with execution verifications via an automated process supported by VLAgent. In the task planning phase, VLAgent fine-tunes an LLM through in-context learning to generate a step-by-step planner for each user-submitted text-visual reasoning task. During the plan execution phase, VLAgent progressively refines the composition of neuro-symbolic executable modules to generate high-confidence reasoning results. VLAgent has three unique design characteristics: First, we improve the quality of plan generation through in-context learning, improving logic reasoning by reducing erroneous logic steps, incorrect programs, and LLM hallucinations. Second, we design a syntax-semantics parser to identify and correct additional logic errors of the LLM-generated planning script prior to launching the plan executor. Finally, we employ the ensemble method to improve the generalization performance of our step-executor. Extensive experiments with four visual reasoning benchmarks (GQA, MME, NLVR2, VQAv2) show that VLAgent achieves significant performance enhancement for multimodal text-visual reasoning applications, compared to the exiting representative VLMs and LLM based visual composition approaches like ViperGPT and VisProg, thanks to the novel optimization modules of VLAgent back-engine (SS-Parser, Plan Repairer, Output Verifiers). Code and data will be made available upon paper acceptance.
Residual Cross-Attention Transformer-Based Multi-User CSI Feedback with Deep Joint Source-Channel Coding
May 26, 2025This letter proposes a deep-learning (DL)-based multi-user channel state information (CSI) feedback framework for massive multiple-input multiple-output systems, where the deep joint source-channel coding (DJSCC) is utilized to improve the CSI reconstruction accuracy. Specifically, we design a multi-user joint CSI feedback framework, whereby the CSI correlation of nearby users is utilized to reduce the feedback overhead. Under the framework, we propose a new residual cross-attention transformer architecture, which is deployed at the base station to further improve the CSI feedback performance. Moreover, to tackle the "cliff-effect" of conventional bit-level CSI feedback approaches, we integrated DJSCC into the multi-user CSI feedback, together with utilizing a two-stage training scheme to adapt to varying uplink noise levels. Experimental results demonstrate the superiority of our methods in CSI feedback performance, with low network complexity and better scalability.
MolLangBench: A Comprehensive Benchmark for Language-Prompted Molecular Structure Recognition, Editing, and Generation
May 21, 2025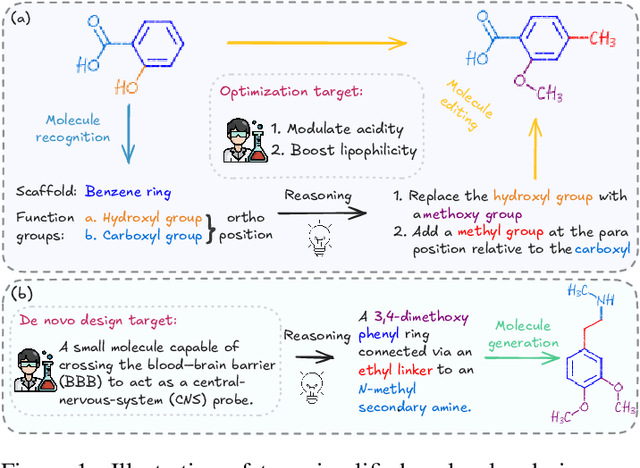
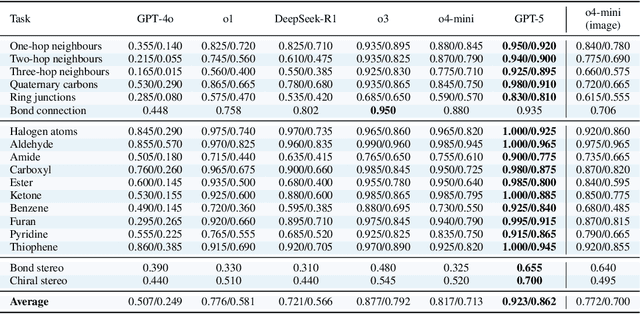
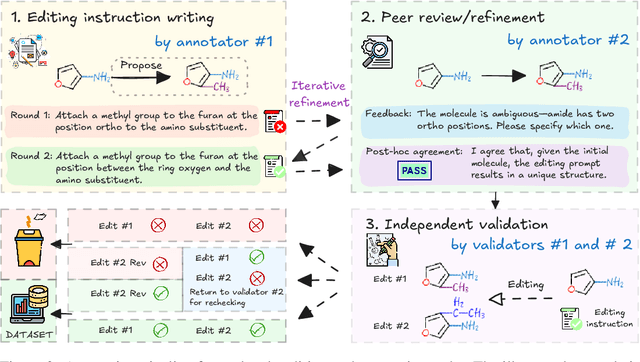

Precise recognition, editing, and generation of molecules are essential prerequisites for both chemists and AI systems tackling various chemical tasks. We present MolLangBench, a comprehensive benchmark designed to evaluate fundamental molecule-language interface tasks: language-prompted molecular structure recognition, editing, and generation. To ensure high-quality, unambiguous, and deterministic outputs, we construct the recognition tasks using automated cheminformatics tools, and curate editing and generation tasks through rigorous expert annotation and validation. MolLangBench supports the evaluation of models that interface language with different molecular representations, including linear strings, molecular images, and molecular graphs. Evaluations of state-of-the-art models reveal significant limitations: the strongest model (o3) achieves $79.2\%$ and $78.5\%$ accuracy on recognition and editing tasks, which are intuitively simple for humans, and performs even worse on the generation task, reaching only $29.0\%$ accuracy. These results highlight the shortcomings of current AI systems in handling even preliminary molecular recognition and manipulation tasks. We hope MolLangBench will catalyze further research toward more effective and reliable AI systems for chemical applications.
Adverseness vs. Equilibrium: Exploring Graph Adversarial Resilience through Dynamic Equilibrium
May 20, 2025Adversarial attacks to graph analytics are gaining increased attention. To date, two lines of countermeasures have been proposed to resist various graph adversarial attacks from the perspectives of either graph per se or graph neural networks. Nevertheless, a fundamental question lies in whether there exists an intrinsic adversarial resilience state within a graph regime and how to find out such a critical state if exists. This paper contributes to tackle the above research questions from three unique perspectives: i) we regard the process of adversarial learning on graph as a complex multi-object dynamic system, and model the behavior of adversarial attack; ii) we propose a generalized theoretical framework to show the existence of critical adversarial resilience state; and iii) we develop a condensed one-dimensional function to capture the dynamic variation of graph regime under perturbations, and pinpoint the critical state through solving the equilibrium point of dynamic system. Multi-facet experiments are conducted to show our proposed approach can significantly outperform the state-of-the-art defense methods under five commonly-used real-world datasets and three representative attacks.