 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARS: Dysarthria-Aware Rhythm-Style Synthesis for ASR Enhancement
Mar 02, 2026Dysarthric speech exhibits abnormal prosody and significant speaker variability, presenting persistent challenges for automatic speech recognition (ASR). While text-to-speech (TTS)-based data augmentation has shown potential, existing methods often fail to accurately model the pathological rhythm and acoustic style of dysarthric speech. To address this, we propose DARS, a dysarthria-aware rhythm-style synthesis framework based on the Matcha-TTS architecture. DARS incorporates a multi-stage rhythm predictor optimized by contrastive preferences between normal and dysarthric speech, along with a dysarthric-style conditional flow matching mechanism, jointly enhancing temporal rhythm reconstruction and pathological acoustic style simulation. Experiments on the TORGO dataset demonstrate that DARS achieves a Mean Cepstral Distortion (MCD) of 4.29, closely approximating real dysarthric speech. Adapting a Whisper-based ASR system with synthetic dysarthric speech from DARS achieves a 54.22% relative reduction in word error rate (WER) compared to state-of-the-art methods, demonstrating the framework's effectiveness in enhancing recognition performance.
* Submitted to 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)
End-to-End Simultaneous Dysarthric Speech Reconstruction with Frame-Level Adaptor and Multiple Wait-k Knowledge Distillation
Mar 02, 2026Dysarthric speech reconstruction (DSR) typically employs a cascaded system that combines automatic speech recognition (ASR) and sentence-level text-to-speech (TTS) to convert dysarthric speech into normally-prosodied speech. However, dysarthric individuals often speak more slowly, leading to excessively long response times in such systems, rendering them impractical in long-speech scenarios. Cascaded DSR systems based on streaming ASR and incremental TTS can help reduce latency. However, patients with differing dysarthria severity exhibit substantial pronunciation variability for the same text, resulting in poor robustness of ASR and limiting the intelligibility of reconstructed speech. In addition, incremental TTS suffers from poor prosodic feature prediction due to a limited receptive field. In this study, we propose an end-to-end simultaneous DSR system with two key innovations: 1) A frame-level adaptor module is introduced to bridge ASR and TTS. By employing explicit-implicit semantic information fusion and joint module training, it enhances the error tolerance of TTS to ASR outputs. 2) A multiple wait-k autoregressive TTS module is designed to mitigate prosodic degradation via multi-view knowledge distillation. Our system has an average response time of 1.03 seconds on Tesla A100, with an average real-time factor (RTF) of 0.71. On the UASpeech dataset, it attains a mean opinion score (MOS) of 4.67 and demonstrates a 54.25% relative reduction in word error rate (WER) compared to the state-of-the-art. Our demo is available at: https://wflrz123.github.io/
* Submitted to 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)
UPA: Unsupervised Prompt Agent via Tree-Based Search and Selection
Jan 30, 2026Prompt agents have recently emerged as a promising paradigm for automated prompt optimization, framing refinement as a sequential decision-making problem over a structured prompt space. While this formulation enables the use of advanced planning algorithms, these methods typically assume access to supervised reward signals, which are often unavailable in practical scenarios. In this work, we propose UPA, an Unsupervised Prompt Agent that realizes structured search and selection without relying on supervised feedback. Specifically, during search, UPA iteratively constructs an evolving tree structure to navigate the prompt space, guided by fine-grained and order-invariant pairwise comparisons from Large Language Models (LLMs). Crucially, as these local comparisons do not inherently yield a consistent global scale, we decouple systematic prompt exploration from final selection, introducing a two-stage framework grounded in the Bradley-Terry-Luce (BTL) model. This framework first performs path-wise Bayesian aggregation of local comparisons to filter candidates under uncertainty, followed by global tournament-style comparisons to infer latent prompt quality and identify the optimal prompt. Experiments across multiple tasks demonstrate that UPA consistently outperforms existing prompt optimization methods, showing that agent-style optimization remains highly effective even in fully unsupervised settings.
Residual Cross-Attention Transformer-Based Multi-User CSI Feedback with Deep Joint Source-Channel Coding
May 26, 2025This letter proposes a deep-learning (DL)-based multi-user channel state information (CSI) feedback framework for massive multiple-input multiple-output systems, where the deep joint source-channel coding (DJSCC) is utilized to improve the CSI reconstruction accuracy. Specifically, we design a multi-user joint CSI feedback framework, whereby the CSI correlation of nearby users is utilized to reduce the feedback overhead. Under the framework, we propose a new residual cross-attention transformer architecture, which is deployed at the base station to further improve the CSI feedback performance. Moreover, to tackle the "cliff-effect" of conventional bit-level CSI feedback approaches, we integrated DJSCC into the multi-user CSI feedback, together with utilizing a two-stage training scheme to adapt to varying uplink noise levels. Experimental results demonstrate the superiority of our methods in CSI feedback performance, with low network complexity and better scalability.
Hypergraph Multi-modal Large Language Model: Exploiting EEG and Eye-tracking Modalities to Evaluate Heterogeneous Responses for Video Understanding
Jul 11, 2024



Understanding of video creativity and content often varies among individuals, with differences in focal points and cognitive levels across different ages, experiences, and genders. There is currently a lack of research in this area, and most existing benchmarks suffer from several drawbacks: 1) a limited number of modalities and answers with restrictive length; 2) the content and scenarios within the videos are excessively monotonous, transmitting allegories and emotions that are overly simplistic. To bridge the gap to real-world applications, we introduce a large-scale \textbf{S}ubjective \textbf{R}esponse \textbf{I}ndicators for \textbf{A}dvertisement \textbf{V}ideos dataset, namely SRI-ADV. Specifically, we collected real changes in Electroencephalographic (EEG) and eye-tracking regions from different demographics while they viewed identical video content. Utilizing this multi-modal dataset, we developed tasks and protocols to analyze and evaluate the extent of cognitive understanding of video content among different users. Along with the dataset, we designed a \textbf{H}ypergraph \textbf{M}ulti-modal \textbf{L}arge \textbf{L}anguage \textbf{M}odel (HMLLM) to explore the associations among different demographics, video elements, EEG and eye-tracking indicators. HMLLM could bridge semantic gaps across rich modalities and integrate information beyond different modalities to perform logical reasoning. Extensive experimental evaluations on SRI-ADV and other additional video-based generative performance benchmarks demonstrate the effectiveness of our method. The codes and dataset will be released at \url{https://github.com/suay1113/HMLLM}.
The USTC-NERCSLIP Systems for The ICMC-ASR Challenge
Jul 02, 2024


This report describes the submitted system to the In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) challenge, which considers the ASR task with multi-speaker overlapping and Mandarin accent dynamics in the ICMC case. We implement the front-end speaker diarization using the self-supervised learning representation based multi-speaker embedding and beamforming using the speaker position, respectively. For ASR, we employ an iterative pseudo-label generation method based on fusion model to obtain text labels of unsupervised data. To mitigate the impact of accent, an Accent-ASR framework is proposed, which captures pronunciation-related accent features at a fine-grained level and linguistic information at a coarse-grained level. On the ICMC-ASR eval set, the proposed system achieves a CER of 13.16% on track 1 and a cpCER of 21.48% on track 2, which significantly outperforms the official baseline system and obtains the first rank on both tracks.
Deep Joint Semantic Coding and Beamforming for Near-Space Airship-Borne Massive MIMO Network
May 30, 2024



Near-space airship-borne communication network is recognized to be an indispensable component of the future integrated ground-air-space network thanks to airships' advantage of long-term residency at stratospheric altitudes, but it urgently needs reliable and efficient Airship-to-X link. To improve the transmission efficiency and capacity, this paper proposes to integrate semantic communication with massive multiple-input multiple-output (MIMO) technology. Specifically, we propose a deep joint semantic coding and beamforming (JSCBF) scheme for airship-based massive MIMO image transmission network in space, in which semantics from both source and channel are fused to jointly design the semantic coding and physical layer beamforming. First, we design two semantic extraction networks to extract semantics from image source and channel state information, respectively. Then, we propose a semantic fusion network that can fuse these semantics into complex-valued semantic features for subsequent physical-layer transmission. To efficiently transmit the fused semantic features at the physical layer, we then propose the hybrid data and model-driven semantic-aware beamforming networks. At the receiver, a semantic decoding network is designed to reconstruct the transmitted images. Finally, we perform end-to-end deep learning to jointly train all the modules, using the image reconstruction quality at the receivers as a metric. The proposed deep JSCBF scheme fully combines the efficient source compressibility and robust error correction capability of semantic communication with the high spectral efficiency of massive MIMO, achieving a significant performance improvement over existing approaches.
An Integrated Visual Analytics System for Studying Clinical Carotid Artery Plaques
Aug 09, 2023



Carotid artery plaques can cause arterial vascular diseases such as stroke and myocardial infarction, posing a severe threat to human life. However, the current clinical examination mainly relies on a direct assessment by physicians of patients' clinical indicators and medical images, lacking an integrated visualization tool for analyzing the influencing factors and composition of carotid artery plaques. We have designed an intelligent carotid artery plaque visual analysis system for vascular surgery experts to comprehensively analyze the clinical physiological and imaging indicators of carotid artery diseases. The system mainly includes two functions: First, it displays the correlation between carotid artery plaque and various factors through a series of information visualization methods and integrates the analysis of patient physiological indicator data. Second, it enhances the interface guidance analysis of the inherent correlation between the components of carotid artery plaque through machine learning and displays the spatial distribution of the plaque on medical images. Additionally, we conducted two case studies on carotid artery plaques using real data obtained from a hospital, and the results indicate that our designed carotid analysis system can effectively provide clinical diagnosis and treatment guidance for vascular surgeons.
Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
Jun 27, 2023Transducer is one of the mainstream frameworks for streaming speech recognition. There is a performance gap between the streaming and non-streaming transducer models due to limited context. To reduce this gap, an effective way is to ensure that their hidden and output distributions are consistent, which can be achieved by hierarchical knowledge distillation. However, it is difficult to ensure the distribution consistency simultaneously because the learning of the output distribution depends on the hidden one. In this paper, we propose an adaptive two-stage knowledge distillation method consisting of hidden layer learning and output layer learning. In the former stage, we learn hidden representation with full context by applying mean square error loss function. In the latter stage, we design a power transformation based adaptive smoothness method to learn stable output distribution. It achieved 19\% relative reduction in word error rate, and a faster response for the first token compared with the original streaming model in LibriSpeech corpus.
AutoKary2022: A Large-Scale Densely Annotated Dateset for Chromosome Instance Segmentation
Mar 31, 2023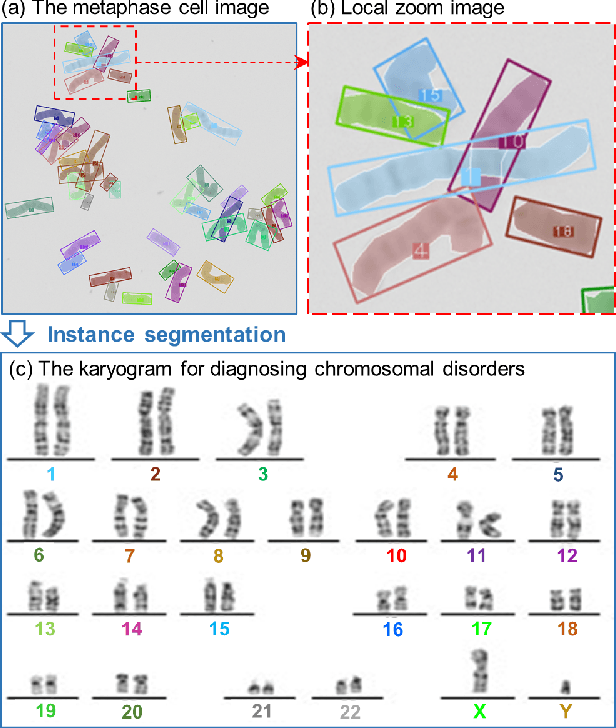
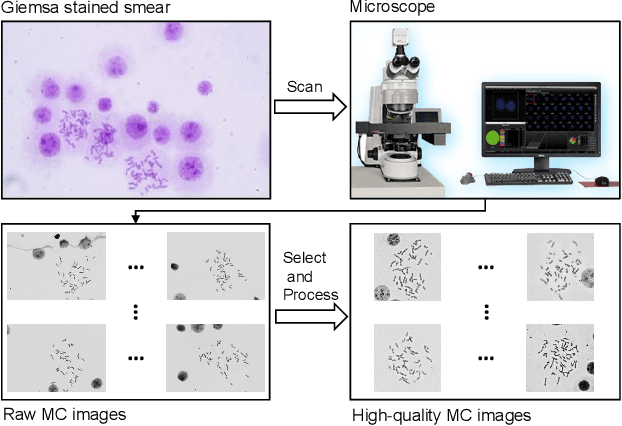
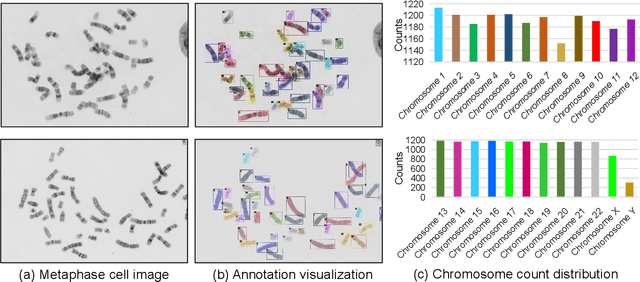
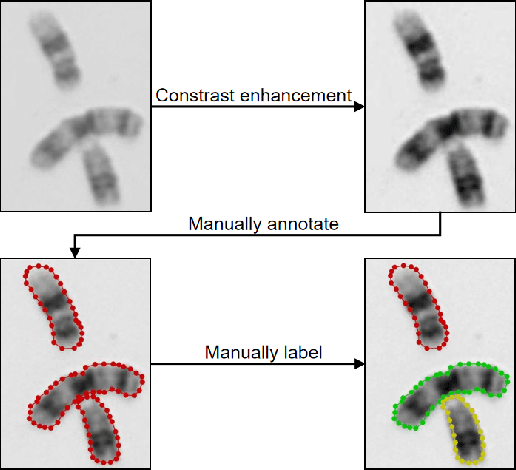
Automated chromosome instance segmentation from metaphase cell microscopic images is critical for the diagnosis of chromosomal disorders (i.e., karyotype analysis). However, it is still a challenging task due to lacking of densely annotated datasets and the complicated morphologies of chromosomes, e.g., dense distribution, arbitrary orientations, and wide range of lengths. To facilitate the development of this area, we take a big step forward and manually construct a large-scale densely annotated dataset named AutoKary2022, which contains over 27,000 chromosome instances in 612 microscopic images from 50 patients. Specifically, each instance is annotated with a polygonal mask and a class label to assist in precise chromosome detection and segmentation. On top of it, we systematically investigate representative methods on this dataset and obtain a number of interesting findings, which helps us have a deeper understanding of the fundamental problems in chromosome instance segmentation. We hope this dataset could advance research towards medical understanding. The dataset can be available at: https://github.com/wangjuncongyu/chromosome-instance-segmentation-dataset.