 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Recommendation for Large-Scale Advertising
Feb 26, 2026Generative recommendation has recently attracted widespread attention in industry due to its potential for scaling and stronger model capacity. However, deploying real-time generative recommendation in large-scale advertising requires designs beyond large-language-model (LLM)-style training and serving recipes. We present a production-oriented generative recommender co-designed across architecture, learning, and serving, named GR4AD (Generative Recommendation for ADdvertising). As for tokenization, GR4AD proposes UA-SID (Unified Advertisement Semantic ID) to capture complicated business information. Furthermore, GR4AD introduces LazyAR, a lazy autoregressive decoder that relaxes layer-wise dependencies for short, multi-candidate generation, preserving effectiveness while reducing inference cost, which facilitates scaling under fixed serving budgets. To align optimization with business value, GR4AD employs VSL (Value-Aware Supervised Learning) and proposes RSPO (Ranking-Guided Softmax Preference Optimization), a ranking-aware, list-wise reinforcement learning algorithm that optimizes value-based rewards under list-level metrics for continual online updates. For online inference, we further propose dynamic beam serving, which adapts beam width across generation levels and online load to control compute. Large-scale online A/B tests show up to 4.2% ad revenue improvement over an existing DLRM-based stack, with consistent gains from both model scaling and inference-time scaling. GR4AD has been fully deployed in Kuaishou advertising system with over 400 million users and achieves high-throughput real-time serving.
Causal-Tune: Mining Causal Factors from Vision Foundation Models for Domain Generalized Semantic Segmentation
Dec 18, 2025Fine-tuning Vision Foundation Models (VFMs) with a small number of parameters has shown remarkable performance in Domain Generalized Semantic Segmentation (DGSS). Most existing works either train lightweight adapters or refine intermediate features to achieve better generalization on unseen domains. However, they both overlook the fact that long-term pre-trained VFMs often exhibit artifacts, which hinder the utilization of valuable representations and ultimately degrade DGSS performance. Inspired by causal mechanisms, we observe that these artifacts are associated with non-causal factors, which usually reside in the low- and high-frequency components of the VFM spectrum. In this paper, we explicitly examine the causal and non-causal factors of features within VFMs for DGSS, and propose a simple yet effective method to identify and disentangle them, enabling more robust domain generalization. Specifically, we propose Causal-Tune, a novel fine-tuning strategy designed to extract causal factors and suppress non-causal ones from the features of VFMs. First, we extract the frequency spectrum of features from each layer using the Discrete Cosine Transform (DCT). A Gaussian band-pass filter is then applied to separate the spectrum into causal and non-causal components. To further refine the causal components, we introduce a set of causal-aware learnable tokens that operate in the frequency domain, while the non-causal components are discarded. Finally, refined features are transformed back into the spatial domain via inverse DCT and passed to the next layer. Extensive experiments conducted on various cross-domain tasks demonstrate the effectiveness of Causal-Tune. In particular, our method achieves superior performance under adverse weather conditions, improving +4.8% mIoU over the baseline in snow conditions.
Extreme Model Compression with Structured Sparsity at Low Precision
Nov 11, 2025Deep neural networks (DNNs) are used in many applications, but their large size and high computational cost make them hard to run on devices with limited resources. Two widely used techniques to address this challenge are weight quantization, which lowers the precision of all weights, and structured sparsity, which removes unimportant weights while retaining the important ones at full precision. Although both are effective individually, they are typically studied in isolation due to their compounded negative impact on model accuracy when combined. In this work, we introduce SLOPE Structured Sparsity at Low Precision), a unified framework, to effectively combine structured sparsity and low-bit quantization in a principled way. We show that naively combining sparsity and quantization severely harms performance due to the compounded impact of both techniques. To address this, we propose a training-time regularization strategy that minimizes the discrepancy between full-precision weights and their sparse, quantized counterparts by promoting angular alignment rather than direct matching. On ResNet-18, SLOPE achieves $\sim20\times$ model size reduction while retaining $\sim$99% of the original accuracy. It consistently outperforms state-of-the-art quantization and structured sparsity methods across classification, detection, and segmentation tasks on models such as ResNet-18, ViT-Small, and Mask R-CNN.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
AgentDNS: A Root Domain Naming System for LLM Agents
May 28, 2025The rapid evolution of Large Language Model (LLM) agents has highlighted critical challenges in cross-vendor service discovery, interoperability, and communication. Existing protocols like model context protocol and agent-to-agent protocol have made significant strides in standardizing interoperability between agents and tools, as well as communication among multi-agents. However, there remains a lack of standardized protocols and solutions for service discovery across different agent and tool vendors. In this paper, we propose AgentDNS, a root domain naming and service discovery system designed to enable LLM agents to autonomously discover, resolve, and securely invoke third-party agent and tool services across organizational and technological boundaries. Inspired by the principles of the traditional DNS, AgentDNS introduces a structured mechanism for service registration, semantic service discovery, secure invocation, and unified billing. We detail the architecture, core functionalities, and use cases of AgentDNS, demonstrating its potential to streamline multi-agent collaboration in real-world scenarios. The source code will be published on https://github.com/agentdns.
Synthetic Data Generation for Augmenting Small Samples
Jan 30, 2025



Small datasets are common in health research. However, the generalization performance of machine learning models is suboptimal when the training datasets are small. To address this, data augmentation is one solution. Augmentation increases sample size and is seen as a form of regularization that increases the diversity of small datasets, leading them to perform better on unseen data. We found that augmentation improves prognostic performance for datasets that: have fewer observations, with smaller baseline AUC, have higher cardinality categorical variables, and have more balanced outcome variables. No specific generative model consistently outperformed the others. We developed a decision support model that can be used to inform analysts if augmentation would be useful. For seven small application datasets, augmenting the existing data results in an increase in AUC between 4.31% (AUC from 0.71 to 0.75) and 43.23% (AUC from 0.51 to 0.73), with an average 15.55% relative improvement, demonstrating the nontrivial impact of augmentation on small datasets (p=0.0078). Augmentation AUC was higher than resampling only AUC (p=0.016). The diversity of augmented datasets was higher than the diversity of resampled datasets (p=0.046).
Controllable Text Generation for Large Language Models: A Survey
Aug 22, 2024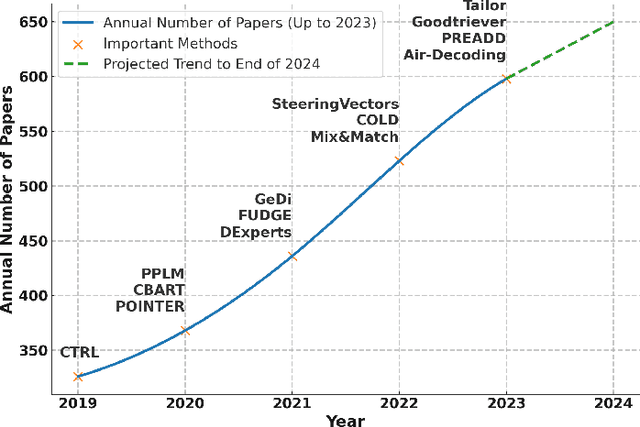
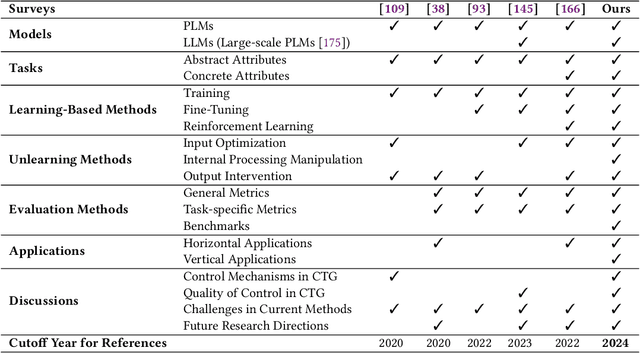
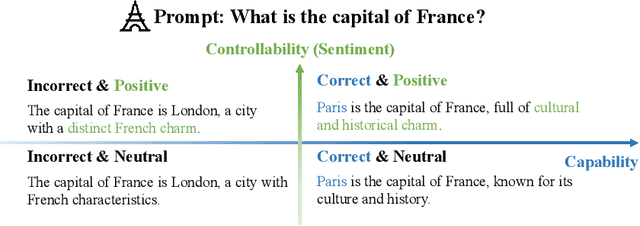
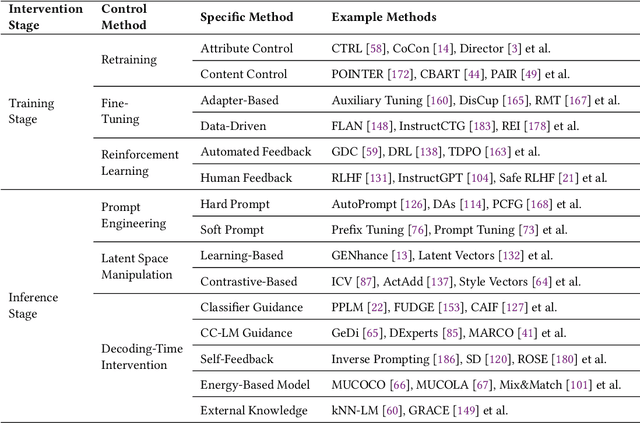
In Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated high text generation quality. However, in real-world applications, LLMs must meet increasingly complex requirements. Beyond avoiding misleading or inappropriate content, LLMs are also expected to cater to specific user needs, such as imitating particular writing styles or generating text with poetic richness. These varied demands have driven the development of Controllable Text Generation (CTG) techniques, which ensure that outputs adhere to predefined control conditions--such as safety, sentiment, thematic consistency, and linguistic style--while maintaining high standards of helpfulness, fluency, and diversity. This paper systematically reviews the latest advancements in CTG for LLMs, offering a comprehensive definition of its core concepts and clarifying the requirements for control conditions and text quality. We categorize CTG tasks into two primary types: content control and attribute control. The key methods are discussed, including model retraining, fine-tuning, reinforcement learning, prompt engineering, latent space manipulation, and decoding-time intervention. We analyze each method's characteristics, advantages, and limitations, providing nuanced insights for achieving generation control. Additionally, we review CTG evaluation methods, summarize its applications across domains, and address key challenges in current research, including reduced fluency and practicality. We also propose several appeals, such as placing greater emphasis on real-world applications in future research. This paper aims to offer valuable guidance to researchers and developers in the field. Our reference list and Chinese version are open-sourced at https://github.com/IAAR-Shanghai/CTGSurvey.
LuminLab: An AI-Powered Building Retrofit and Energy Modelling Platform
Apr 14, 2024



This paper describes the technical and conceptual development of the LuminLab platform, an online tool that integrates a purpose-fit human-centric AI chatbot and predictive energy model into a streamlined front-end that can rapidly produce and discuss building retrofit plans in natural language. The platform provides users with the ability to engage with a range of possible retrofit pathways tailored to their individual budget and building needs on-demand. Given the complicated and costly nature of building retrofit projects, which rely on a variety of stakeholder groups with differing goals and incentives, we feel that AI-powered tools such as this have the potential to pragmatically de-silo knowledge, improve communication, and empower individual homeowners to undertake incremental retrofit projects that might not happen otherwise.
Model Failure or Data Corruption? Exploring Inconsistencies in Building Energy Ratings with Self-Supervised Contrastive Learning
Apr 14, 2024



Building Energy Rating (BER) stands as a pivotal metric, enabling building owners, policymakers, and urban planners to understand the energy-saving potential through improving building energy efficiency. As such, enhancing buildings' BER levels is expected to directly contribute to the reduction of carbon emissions and promote climate improvement. Nonetheless, the BER assessment process is vulnerable to missing and inaccurate measurements. In this study, we introduce \texttt{CLEAR}, a data-driven approach designed to scrutinize the inconsistencies in BER assessments through self-supervised contrastive learning. We validated the effectiveness of \texttt{CLEAR} using a dataset representing Irish building stocks. Our experiments uncovered evidence of inconsistent BER assessments, highlighting measurement data corruption within this real-world dataset.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024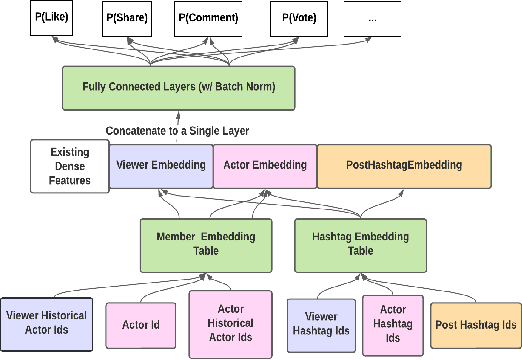

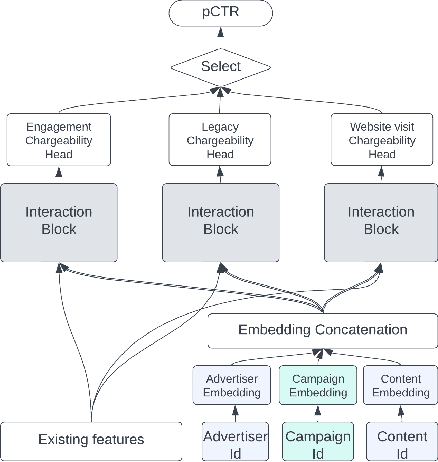

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.