 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreFlect: From Retrospective to Prospective Reflection in Large Language Model Agents
Feb 06, 2026Advanced large language model agents typically adopt self-reflection for improving performance, where agents iteratively analyze past actions to correct errors. However, existing reflective approaches are inherently retrospective: agents act, observe failure, and only then attempt to recover. In this work, we introduce PreFlect, a prospective reflection mechanism that shifts the paradigm from post hoc correction to pre-execution foresight by criticizing and refining agent plans before execution. To support grounded prospective reflection, we distill planning errors from historical agent trajectories, capturing recurring success and failure patterns observed across past executions. Furthermore, we complement prospective reflection with a dynamic re-planning mechanism that provides execution-time plan update in case the original plan encounters unexpected deviation. Evaluations on different benchmarks demonstrate that PreFlect significantly improves overall agent utility on complex real-world tasks, outperforming strong reflection-based baselines and several more complex agent architectures. Code will be updated at https://github.com/wwwhy725/PreFlect.
AI Transparency Atlas: Framework, Scoring, and Real-Time Model Card Evaluation Pipeline
Dec 13, 2025AI model documentation is fragmented across platforms and inconsistent in structure, preventing policymakers, auditors, and users from reliably assessing safety claims, data provenance, and version-level changes. We analyzed documentation from five frontier models (Gemini 3, Grok 4.1, Llama 4, GPT-5, and Claude 4.5) and 100 Hugging Face model cards, identifying 947 unique section names with extreme naming variation. Usage information alone appeared under 97 distinct labels. Using the EU AI Act Annex IV and the Stanford Transparency Index as baselines, we developed a weighted transparency framework with 8 sections and 23 subsections that prioritizes safety-critical disclosures (Safety Evaluation: 25%, Critical Risk: 20%) over technical specifications. We implemented an automated multi-agent pipeline that extracts documentation from public sources and scores completeness through LLM-based consensus. Evaluating 50 models across vision, multimodal, open-source, and closed-source systems cost less than $3 in total and revealed systematic gaps. Frontier labs (xAI, Microsoft, Anthropic) achieve approximately 80% compliance, while most providers fall below 60%. Safety-critical categories show the largest deficits: deception behaviors, hallucinations, and child safety evaluations account for 148, 124, and 116 aggregate points lost, respectively, across all evaluated models.
MoM: Mixtures of Scenario-Aware Document Memories for Retrieval-Augmented Generation Systems
Oct 16, 2025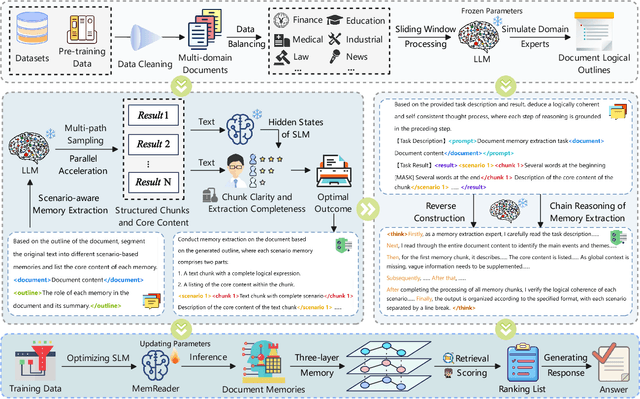
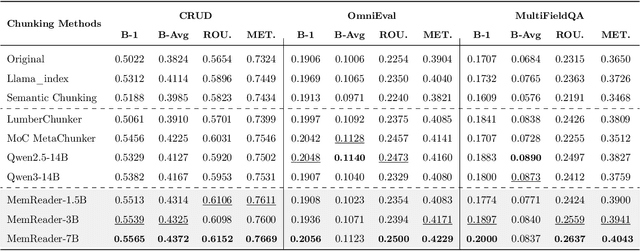
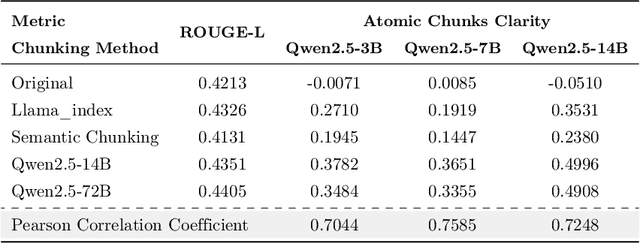
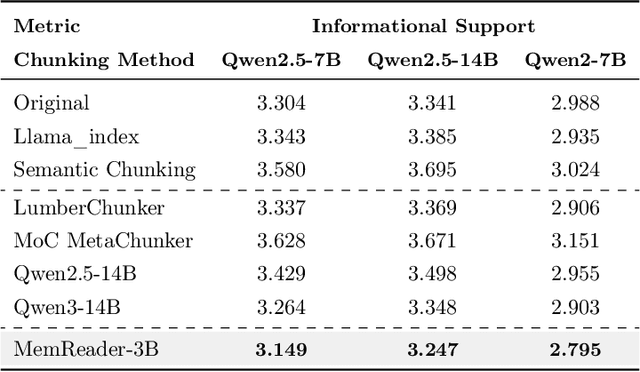
The traditional RAG paradigm, which typically engages in the comprehension of relevant text chunks in response to received queries, inherently restricts both the depth of knowledge internalization and reasoning capabilities. To address this limitation, our research transforms the text processing in RAG from passive chunking to proactive understanding, defining this process as document memory extraction with the objective of simulating human cognitive processes during reading. Building upon this, we propose the Mixtures of scenario-aware document Memories (MoM) framework, engineered to efficiently handle documents from multiple domains and train small language models (SLMs) to acquire the ability to proactively explore and construct document memories. The MoM initially instructs large language models (LLMs) to simulate domain experts in generating document logical outlines, thereby directing structured chunking and core content extraction. It employs a multi-path sampling and multi-perspective evaluation mechanism, specifically designing comprehensive metrics that represent chunk clarity and extraction completeness to select the optimal document memories. Additionally, to infuse deeper human-like reading abilities during the training of SLMs, we incorporate a reverse reasoning strategy, which deduces refined expert thinking paths from high-quality outcomes. Finally, leveraging diverse forms of content generated by MoM, we develop a three-layer document memory retrieval mechanism, which is grounded in our theoretical proof from the perspective of probabilistic modeling. Extensive experimental results across three distinct domains demonstrate that the MoM framework not only resolves text chunking challenges in existing RAG systems, providing LLMs with semantically complete document memories, but also paves the way for SLMs to achieve human-centric intelligent text processing.
Aria: An Agent For Retrieval and Iterative Auto-Formalization via Dependency Graph
Oct 06, 2025Accurate auto-formalization of theorem statements is essential for advancing automated discovery and verification of research-level mathematics, yet remains a major bottleneck for LLMs due to hallucinations, semantic mismatches, and their inability to synthesize new definitions. To tackle these issues, we present Aria (Agent for Retrieval and Iterative Autoformalization), a system for conjecture-level formalization in Lean that emulates human expert reasoning via a two-phase Graph-of-Thought process: recursively decomposing statements into a dependency graph and then constructing formalizations from grounded concepts. To ensure semantic correctness, we introduce AriaScorer, a checker that retrieves definitions from Mathlib for term-level grounding, enabling rigorous and reliable verification. We evaluate Aria on diverse benchmarks. On ProofNet, it achieves 91.6% compilation success rate and 68.5% final accuracy, surpassing previous methods. On FATE-X, a suite of challenging algebra problems from research literature, it outperforms the best baseline with 44.0% vs. 24.0% final accuracy. On a dataset of homological conjectures, Aria reaches 42.9% final accuracy while all other models score 0%.
Growing Visual Generative Capacity for Pre-Trained MLLMs
Oct 02, 2025Multimodal large language models (MLLMs) extend the success of language models to visual understanding, and recent efforts have sought to build unified MLLMs that support both understanding and generation. However, constructing such models remains challenging: hybrid approaches combine continuous embeddings with diffusion or flow-based objectives, producing high-quality images but breaking the autoregressive paradigm, while pure autoregressive approaches unify text and image prediction over discrete visual tokens but often face trade-offs between semantic alignment and pixel-level fidelity. In this work, we present Bridge, a pure autoregressive unified MLLM that augments pre-trained visual understanding models with generative ability through a Mixture-of-Transformers architecture, enabling both image understanding and generation within a single next-token prediction framework. To further improve visual generation fidelity, we propose a semantic-to-pixel discrete representation that integrates compact semantic tokens with fine-grained pixel tokens, achieving strong language alignment and precise description of visual details with only a 7.9% increase in sequence length. Extensive experiments across diverse multimodal benchmarks demonstrate that Bridge achieves competitive or superior results in both understanding and generation benchmarks, while requiring less training data and reduced training time compared to prior unified MLLMs.
RACap: Relation-Aware Prompting for Lightweight Retrieval-Augmented Image Captioning
Sep 19, 2025Recent retrieval-augmented image captioning methods incorporate external knowledge to compensate for the limitations in comprehending complex scenes. However, current approaches face challenges in relation modeling: (1) the representation of semantic prompts is too coarse-grained to capture fine-grained relationships; (2) these methods lack explicit modeling of image objects and their semantic relationships. To address these limitations, we propose RACap, a relation-aware retrieval-augmented model for image captioning, which not only mines structured relation semantics from retrieval captions, but also identifies heterogeneous objects from the image. RACap effectively retrieves structured relation features that contain heterogeneous visual information to enhance the semantic consistency and relational expressiveness. Experimental results show that RACap, with only 10.8M trainable parameters, achieves superior performance compared to previous lightweight captioning models.
Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations
Jun 23, 2025
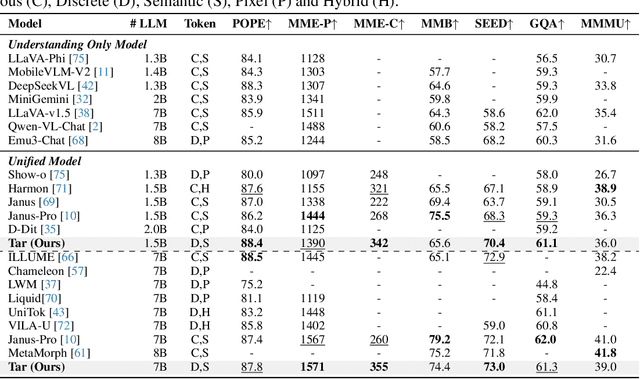
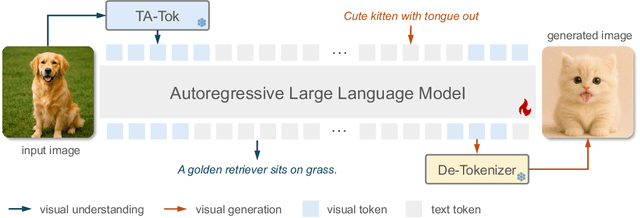
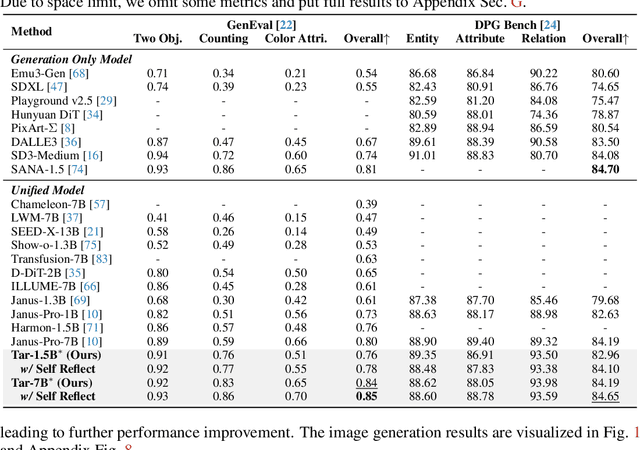
This paper presents a multimodal framework that attempts to unify visual understanding and generation within a shared discrete semantic representation. At its core is the Text-Aligned Tokenizer (TA-Tok), which converts images into discrete tokens using a text-aligned codebook projected from a large language model's (LLM) vocabulary. By integrating vision and text into a unified space with an expanded vocabulary, our multimodal LLM, Tar, enables cross-modal input and output through a shared interface, without the need for modality-specific designs. Additionally, we propose scale-adaptive encoding and decoding to balance efficiency and visual detail, along with a generative de-tokenizer to produce high-fidelity visual outputs. To address diverse decoding needs, we utilize two complementary de-tokenizers: a fast autoregressive model and a diffusion-based model. To enhance modality fusion, we investigate advanced pre-training tasks, demonstrating improvements in both visual understanding and generation. Experiments across benchmarks show that Tar matches or surpasses existing multimodal LLM methods, achieving faster convergence and greater training efficiency. Code, models, and data are available at https://tar.csuhan.com
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025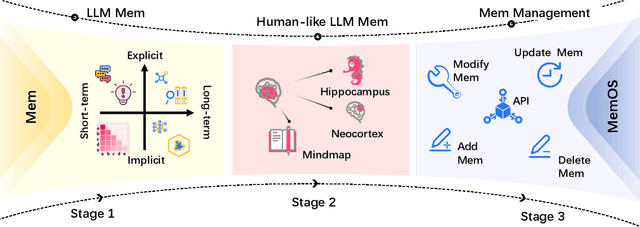
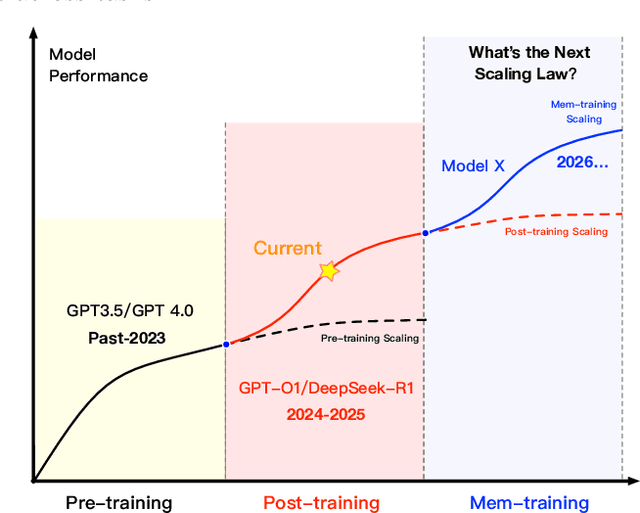
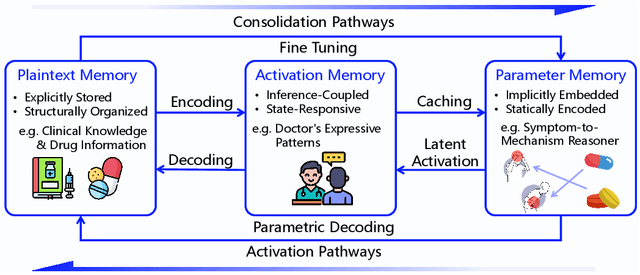
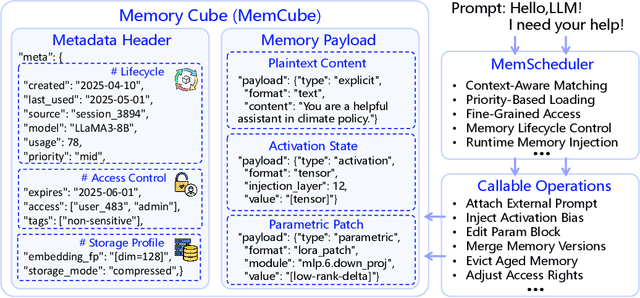
Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
LLM-DSE: Searching Accelerator Parameters with LLM Agents
May 18, 2025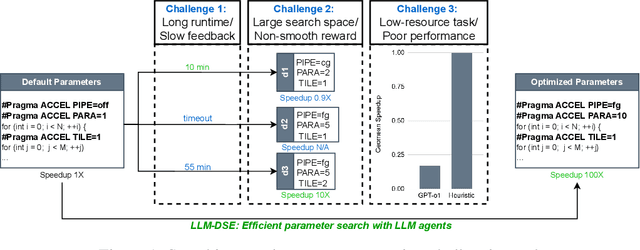
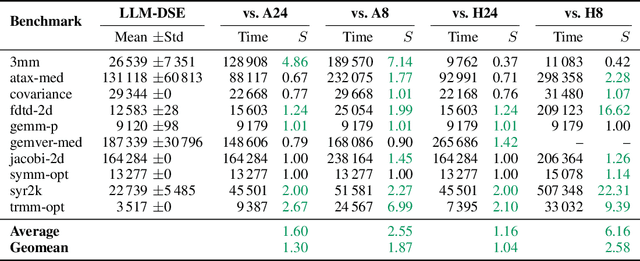
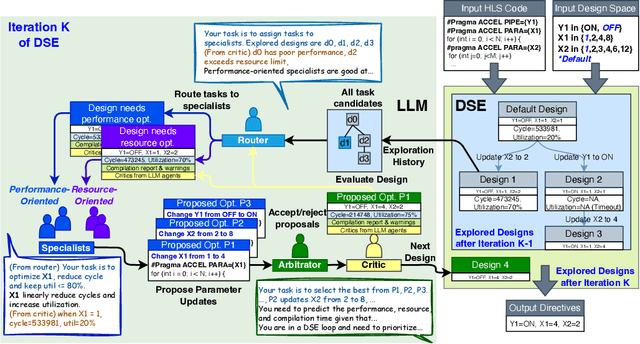

Even though high-level synthesis (HLS) tools mitigate the challenges of programming domain-specific accelerators (DSAs) by raising the abstraction level, optimizing hardware directive parameters remains a significant hurdle. Existing heuristic and learning-based methods struggle with adaptability and sample efficiency.We present LLM-DSE, a multi-agent framework designed specifically for optimizing HLS directives. Combining LLM with design space exploration (DSE), our explorer coordinates four agents: Router, Specialists, Arbitrator, and Critic. These multi-agent components interact with various tools to accelerate the optimization process. LLM-DSE leverages essential domain knowledge to identify efficient parameter combinations while maintaining adaptability through verbal learning from online interactions. Evaluations on the HLSyn dataset demonstrate that LLM-DSE achieves substantial $2.55\times$ performance gains over state-of-the-art methods, uncovering novel designs while reducing runtime. Ablation studies validate the effectiveness and necessity of the proposed agent interactions. Our code is open-sourced here: https://github.com/Nozidoali/LLM-DSE.
MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System
Mar 12, 2025



Retrieval-Augmented Generation (RAG), while serving as a viable complement to large language models (LLMs), often overlooks the crucial aspect of text chunking within its pipeline. This paper initially introduces a dual-metric evaluation method, comprising Boundary Clarity and Chunk Stickiness, to enable the direct quantification of chunking quality. Leveraging this assessment method, we highlight the inherent limitations of traditional and semantic chunking in handling complex contextual nuances, thereby substantiating the necessity of integrating LLMs into chunking process. To address the inherent trade-off between computational efficiency and chunking precision in LLM-based approaches, we devise the granularity-aware Mixture-of-Chunkers (MoC) framework, which consists of a three-stage processing mechanism. Notably, our objective is to guide the chunker towards generating a structured list of chunking regular expressions, which are subsequently employed to extract chunks from the original text. Extensive experiments demonstrate that both our proposed metrics and the MoC framework effectively settle challenges of the chunking task, revealing the chunking kernel while enhancing the performance of the RAG system.