 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoM: Mixtures of Scenario-Aware Document Memories for Retrieval-Augmented Generation Systems
Oct 16, 2025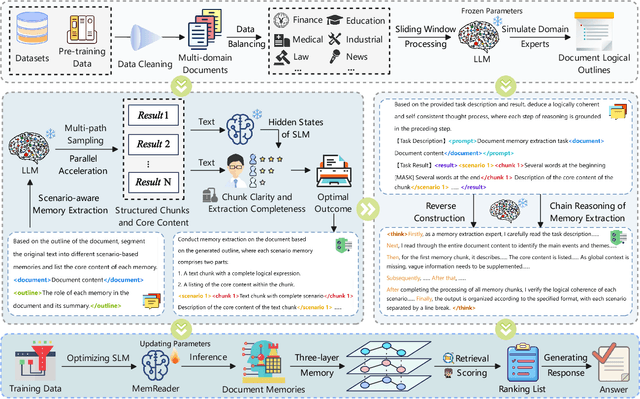
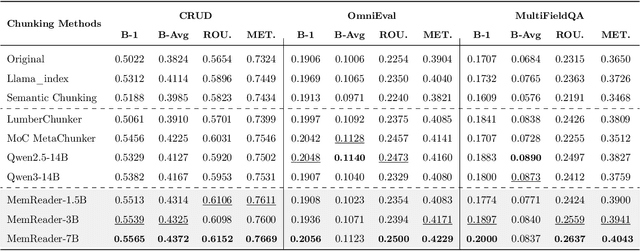
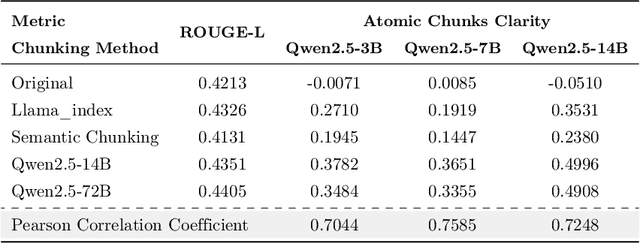
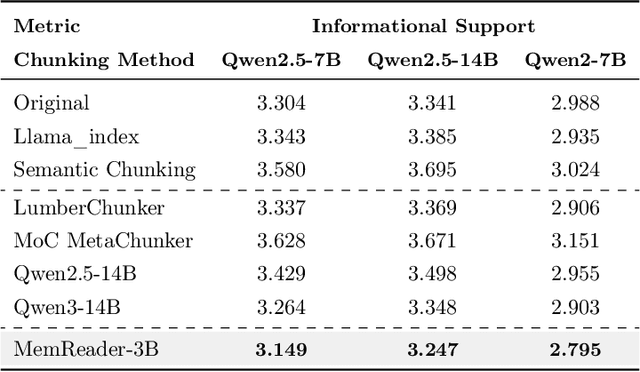
The traditional RAG paradigm, which typically engages in the comprehension of relevant text chunks in response to received queries, inherently restricts both the depth of knowledge internalization and reasoning capabilities. To address this limitation, our research transforms the text processing in RAG from passive chunking to proactive understanding, defining this process as document memory extraction with the objective of simulating human cognitive processes during reading. Building upon this, we propose the Mixtures of scenario-aware document Memories (MoM) framework, engineered to efficiently handle documents from multiple domains and train small language models (SLMs) to acquire the ability to proactively explore and construct document memories. The MoM initially instructs large language models (LLMs) to simulate domain experts in generating document logical outlines, thereby directing structured chunking and core content extraction. It employs a multi-path sampling and multi-perspective evaluation mechanism, specifically designing comprehensive metrics that represent chunk clarity and extraction completeness to select the optimal document memories. Additionally, to infuse deeper human-like reading abilities during the training of SLMs, we incorporate a reverse reasoning strategy, which deduces refined expert thinking paths from high-quality outcomes. Finally, leveraging diverse forms of content generated by MoM, we develop a three-layer document memory retrieval mechanism, which is grounded in our theoretical proof from the perspective of probabilistic modeling. Extensive experimental results across three distinct domains demonstrate that the MoM framework not only resolves text chunking challenges in existing RAG systems, providing LLMs with semantically complete document memories, but also paves the way for SLMs to achieve human-centric intelligent text processing.
MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System
Mar 12, 2025



Retrieval-Augmented Generation (RAG), while serving as a viable complement to large language models (LLMs), often overlooks the crucial aspect of text chunking within its pipeline. This paper initially introduces a dual-metric evaluation method, comprising Boundary Clarity and Chunk Stickiness, to enable the direct quantification of chunking quality. Leveraging this assessment method, we highlight the inherent limitations of traditional and semantic chunking in handling complex contextual nuances, thereby substantiating the necessity of integrating LLMs into chunking process. To address the inherent trade-off between computational efficiency and chunking precision in LLM-based approaches, we devise the granularity-aware Mixture-of-Chunkers (MoC) framework, which consists of a three-stage processing mechanism. Notably, our objective is to guide the chunker towards generating a structured list of chunking regular expressions, which are subsequently employed to extract chunks from the original text. Extensive experiments demonstrate that both our proposed metrics and the MoC framework effectively settle challenges of the chunking task, revealing the chunking kernel while enhancing the performance of the RAG system.
Meta-Chunking: Learning Efficient Text Segmentation via Logical Perception
Oct 16, 2024



Retrieval-Augmented Generation (RAG), while serving as a viable complement to large language models (LLMs), often overlooks the crucial aspect of text chunking within its pipeline, which impacts the quality of knowledge-intensive tasks. This paper introduces the concept of Meta-Chunking, which refers to a granularity between sentences and paragraphs, consisting of a collection of sentences within a paragraph that have deep linguistic logical connections. To implement Meta-Chunking, we designed two strategies based on LLMs: Margin Sampling Chunking and Perplexity Chunking. The former employs LLMs to perform binary classification on whether consecutive sentences need to be segmented, making decisions based on the probability difference obtained from margin sampling. The latter precisely identifies text chunk boundaries by analyzing the characteristics of perplexity distribution. Additionally, considering the inherent complexity of different texts, we propose a strategy that combines Meta-Chunking with dynamic merging to achieve a balance between fine-grained and coarse-grained text chunking. Experiments conducted on eleven datasets demonstrate that Meta-Chunking can more efficiently improve the performance of single-hop and multi-hop question answering based on RAG. For instance, on the 2WikiMultihopQA dataset, it outperforms similarity chunking by 1.32 while only consuming 45.8% of the time. Our code is available at https://github.com/IAAR-Shanghai/Meta-Chunking.