 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnovator-VL: A Multimodal Large Language Model for Scientific Discovery
Jan 27, 2026We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.
RoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
Jan 06, 2026The hallmark of human intelligence is the ability to master new skills through Constructive Episodic Simulation-retrieving past experiences to synthesize solutions for novel tasks. While Large Language Models possess strong reasoning capabilities, they struggle to emulate this self-evolution: fine-tuning is computationally expensive and prone to catastrophic forgetting, while existing memory-based methods rely on passive semantic matching that often retrieves noise. To address these challenges, we propose MemRL, a framework that enables agents to self-evolve via non-parametric reinforcement learning on episodic memory. MemRL explicitly separates the stable reasoning of a frozen LLM from the plastic, evolving memory. Unlike traditional methods, MemRL employs a Two-Phase Retrieval mechanism that filters candidates by semantic relevance and then selects them based on learned Q-values (utility). These utilities are continuously refined via environmental feedback in an trial-and-error manner, allowing the agent to distinguish high-value strategies from similar noise. Extensive experiments on HLE, BigCodeBench, ALFWorld, and Lifelong Agent Bench demonstrate that MemRL significantly outperforms state-of-the-art baselines. Our analysis experiments confirm that MemRL effectively reconciles the stability-plasticity dilemma, enabling continuous runtime improvement without weight updates.
ParaMaP: Parallel Mapping and Collision-free Motion Planning for Reactive Robot Manipulation
Dec 27, 2025Real-time and collision-free motion planning remains challenging for robotic manipulation in unknown environments due to continuous perception updates and the need for frequent online replanning. To address these challenges, we propose a parallel mapping and motion planning framework that tightly integrates Euclidean Distance Transform (EDT)-based environment representation with a sampling-based model predictive control (SMPC) planner. On the mapping side, a dense distance-field-based representation is constructed using a GPU-based EDT and augmented with a robot-masked update mechanism to prevent false self-collision detections during online perception. On the planning side, motion generation is formulated as a stochastic optimization problem with a unified objective function and efficiently solved by evaluating large batches of candidate rollouts in parallel within a SMPC framework, in which a geometrically consistent pose tracking metric defined on SE(3) is incorporated to ensure fast and accurate convergence to the target pose. The entire mapping and planning pipeline is implemented on the GPU to support high-frequency replanning. The effectiveness of the proposed framework is validated through extensive simulations and real-world experiments on a 7-DoF robotic manipulator. More details are available at: https://zxw610.github.io/ParaMaP.
HaluMem: Evaluating Hallucinations in Memory Systems of Agents
Nov 05, 2025Memory systems are key components that enable AI systems such as LLMs and AI agents to achieve long-term learning and sustained interaction. However, during memory storage and retrieval, these systems frequently exhibit memory hallucinations, including fabrication, errors, conflicts, and omissions. Existing evaluations of memory hallucinations are primarily end-to-end question answering, which makes it difficult to localize the operational stage within the memory system where hallucinations arise. To address this, we introduce the Hallucination in Memory Benchmark (HaluMem), the first operation level hallucination evaluation benchmark tailored to memory systems. HaluMem defines three evaluation tasks (memory extraction, memory updating, and memory question answering) to comprehensively reveal hallucination behaviors across different operational stages of interaction. To support evaluation, we construct user-centric, multi-turn human-AI interaction datasets, HaluMem-Medium and HaluMem-Long. Both include about 15k memory points and 3.5k multi-type questions. The average dialogue length per user reaches 1.5k and 2.6k turns, with context lengths exceeding 1M tokens, enabling evaluation of hallucinations across different context scales and task complexities. Empirical studies based on HaluMem show that existing memory systems tend to generate and accumulate hallucinations during the extraction and updating stages, which subsequently propagate errors to the question answering stage. Future research should focus on developing interpretable and constrained memory operation mechanisms that systematically suppress hallucinations and improve memory reliability.
MoM: Mixtures of Scenario-Aware Document Memories for Retrieval-Augmented Generation Systems
Oct 16, 2025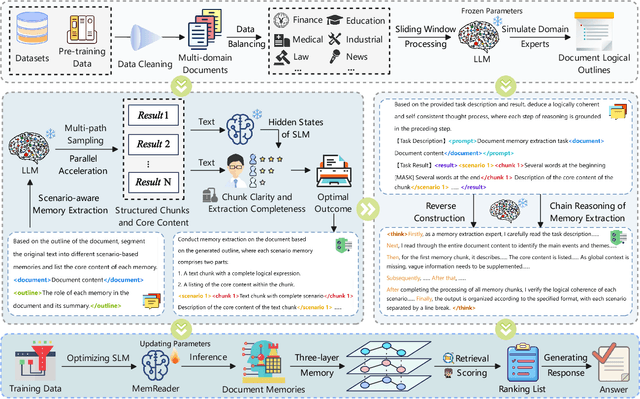
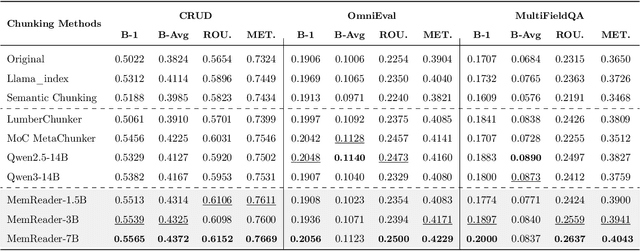
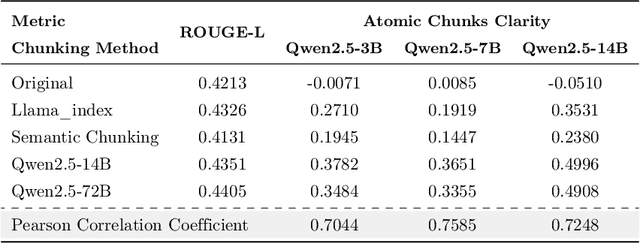
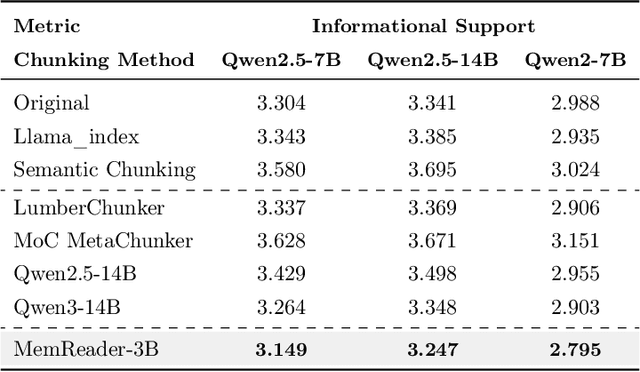
The traditional RAG paradigm, which typically engages in the comprehension of relevant text chunks in response to received queries, inherently restricts both the depth of knowledge internalization and reasoning capabilities. To address this limitation, our research transforms the text processing in RAG from passive chunking to proactive understanding, defining this process as document memory extraction with the objective of simulating human cognitive processes during reading. Building upon this, we propose the Mixtures of scenario-aware document Memories (MoM) framework, engineered to efficiently handle documents from multiple domains and train small language models (SLMs) to acquire the ability to proactively explore and construct document memories. The MoM initially instructs large language models (LLMs) to simulate domain experts in generating document logical outlines, thereby directing structured chunking and core content extraction. It employs a multi-path sampling and multi-perspective evaluation mechanism, specifically designing comprehensive metrics that represent chunk clarity and extraction completeness to select the optimal document memories. Additionally, to infuse deeper human-like reading abilities during the training of SLMs, we incorporate a reverse reasoning strategy, which deduces refined expert thinking paths from high-quality outcomes. Finally, leveraging diverse forms of content generated by MoM, we develop a three-layer document memory retrieval mechanism, which is grounded in our theoretical proof from the perspective of probabilistic modeling. Extensive experimental results across three distinct domains demonstrate that the MoM framework not only resolves text chunking challenges in existing RAG systems, providing LLMs with semantically complete document memories, but also paves the way for SLMs to achieve human-centric intelligent text processing.
InfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented Agents
Oct 02, 2025Information seeking is a fundamental requirement for humans. However, existing LLM agents rely heavily on open-web search, which exposes two fundamental weaknesses: online content is noisy and unreliable, and many real-world tasks require precise, domain-specific knowledge unavailable from the web. The emergence of the Model Context Protocol (MCP) now allows agents to interface with thousands of specialized tools, seemingly resolving this limitation. Yet it remains unclear whether agents can effectively leverage such tools -- and more importantly, whether they can integrate them with general-purpose search to solve complex tasks. Therefore, we introduce InfoMosaic-Bench, the first benchmark dedicated to multi-source information seeking in tool-augmented agents. Covering six representative domains (medicine, finance, maps, video, web, and multi-domain integration), InfoMosaic-Bench requires agents to combine general-purpose search with domain-specific tools. Tasks are synthesized with InfoMosaic-Flow, a scalable pipeline that grounds task conditions in verified tool outputs, enforces cross-source dependencies, and filters out shortcut cases solvable by trivial lookup. This design guarantees both reliability and non-triviality. Experiments with 14 state-of-the-art LLM agents reveal three findings: (i) web information alone is insufficient, with GPT-5 achieving only 38.2% accuracy and 67.5% pass rate; (ii) domain tools provide selective but inconsistent benefits, improving some domains while degrading others; and (iii) 22.4% of failures arise from incorrect tool usage or selection, highlighting that current LLMs still struggle with even basic tool handling.
HieroAction: Hierarchically Guided VLM for Fine-Grained Action Analysis
Aug 23, 2025Evaluating human actions with clear and detailed feedback is important in areas such as sports, healthcare, and robotics, where decisions rely not only on final outcomes but also on interpretable reasoning. However, most existing methods provide only a final score without explanation or detailed analysis, limiting their practical applicability. To address this, we introduce HieroAction, a vision-language model that delivers accurate and structured assessments of human actions. HieroAction builds on two key ideas: (1) Stepwise Action Reasoning, a tailored chain of thought process designed specifically for action assessment, which guides the model to evaluate actions step by step, from overall recognition through sub action analysis to final scoring, thus enhancing interpretability and structured understanding; and (2) Hierarchical Policy Learning, a reinforcement learning strategy that enables the model to learn fine grained sub action dynamics and align them with high level action quality, thereby improving scoring precision. The reasoning pathway structures the evaluation process, while policy learning refines each stage through reward based optimization. Their integration ensures accurate and interpretable assessments, as demonstrated by superior performance across multiple benchmark datasets. Code will be released upon acceptance.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.