 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapDream: Task-Driven Map Learning for Vision-Language Navigation
Feb 03, 2026Vision-Language Navigation (VLN) requires agents to follow natural language instructions in partially observed 3D environments, motivating map representations that aggregate spatial context beyond local perception. However, most existing approaches rely on hand-crafted maps constructed independently of the navigation policy. We argue that maps should instead be learned representations shaped directly by navigation objectives rather than exhaustive reconstructions. Based on this insight, we propose MapDream, a map-in-the-loop framework that formulates map construction as autoregressive bird's-eye-view (BEV) image synthesis. The framework jointly learns map generation and action prediction, distilling environmental context into a compact three-channel BEV map that preserves only navigation-critical affordances. Supervised pre-training bootstraps a reliable mapping-to-control interface, while the autoregressive design enables end-to-end joint optimization through reinforcement fine-tuning. Experiments on R2R-CE and RxR-CE achieve state-of-the-art monocular performance, validating task-driven generative map learning.
GPO: Growing Policy Optimization for Legged Robot Locomotion and Whole-Body Control
Jan 28, 2026Training reinforcement learning (RL) policies for legged robots remains challenging due to high-dimensional continuous actions, hardware constraints, and limited exploration. Existing methods for locomotion and whole-body control work well for position-based control with environment-specific heuristics (e.g., reward shaping, curriculum design, and manual initialization), but are less effective for torque-based control, where sufficiently exploring the action space and obtaining informative gradient signals for training is significantly more difficult. We introduce Growing Policy Optimization (GPO), a training framework that applies a time-varying action transformation to restrict the effective action space in the early stage, thereby encouraging more effective data collection and policy learning, and then progressively expands it to enhance exploration and achieve higher expected return. We prove that this transformation preserves the PPO update rule and introduces only bounded, vanishing gradient distortion, thereby ensuring stable training. We evaluate GPO on both quadruped and hexapod robots, including zero-shot deployment of simulation-trained policies on hardware. Policies trained with GPO consistently achieve better performance. These results suggest that GPO provides a general, environment-agnostic optimization framework for learning legged locomotion.
Inside Out: Evolving User-Centric Core Memory Trees for Long-Term Personalized Dialogue Systems
Jan 08, 2026Existing long-term personalized dialogue systems struggle to reconcile unbounded interaction streams with finite context constraints, often succumbing to memory noise accumulation, reasoning degradation, and persona inconsistency. To address these challenges, this paper proposes Inside Out, a framework that utilizes a globally maintained PersonaTree as the carrier of long-term user profiling. By constraining the trunk with an initial schema and updating the branches and leaves, PersonaTree enables controllable growth, achieving memory compression while preserving consistency. Moreover, we train a lightweight MemListener via reinforcement learning with process-based rewards to produce structured, executable, and interpretable {ADD, UPDATE, DELETE, NO_OP} operations, thereby supporting the dynamic evolution of the personalized tree. During response generation, PersonaTree is directly leveraged to enhance outputs in latency-sensitive scenarios; when users require more details, the agentic mode is triggered to introduce details on-demand under the constraints of the PersonaTree. Experiments show that PersonaTree outperforms full-text concatenation and various personalized memory systems in suppressing contextual noise and maintaining persona consistency. Notably, the small MemListener model achieves memory-operation decision performance comparable to, or even surpassing, powerful reasoning models such as DeepSeek-R1-0528 and Gemini-3-Pro.
DeepSynth-Eval: Objectively Evaluating Information Consolidation in Deep Survey Writing
Jan 07, 2026The evolution of Large Language Models (LLMs) towards autonomous agents has catalyzed progress in Deep Research. While retrieval capabilities are well-benchmarked, the post-retrieval synthesis stage--where agents must digest massive amounts of context and consolidate fragmented evidence into coherent, long-form reports--remains under-evaluated due to the subjectivity of open-ended writing. To bridge this gap, we introduce DeepSynth-Eval, a benchmark designed to objectively evaluate information consolidation capabilities. We leverage high-quality survey papers as gold standards, reverse-engineering research requests and constructing "Oracle Contexts" from their bibliographies to isolate synthesis from retrieval noise. We propose a fine-grained evaluation protocol using General Checklists (for factual coverage) and Constraint Checklists (for structural organization), transforming subjective judgment into verifiable metrics. Experiments across 96 tasks reveal that synthesizing information from hundreds of references remains a significant challenge. Our results demonstrate that agentic plan-and-write workflows significantly outperform single-turn generation, effectively reducing hallucinations and improving adherence to complex structural constraints.
ActAvatar: Temporally-Aware Precise Action Control for Talking Avatars
Dec 22, 2025Despite significant advances in talking avatar generation, existing methods face critical challenges: insufficient text-following capability for diverse actions, lack of temporal alignment between actions and audio content, and dependency on additional control signals such as pose skeletons. We present ActAvatar, a framework that achieves phase-level precision in action control through textual guidance by capturing both action semantics and temporal context. Our approach introduces three core innovations: (1) Phase-Aware Cross-Attention (PACA), which decomposes prompts into a global base block and temporally-anchored phase blocks, enabling the model to concentrate on phase-relevant tokens for precise temporal-semantic alignment; (2) Progressive Audio-Visual Alignment, which aligns modality influence with the hierarchical feature learning process-early layers prioritize text for establishing action structure while deeper layers emphasize audio for refining lip movements, preventing modality interference; (3) A two-stage training strategy that first establishes robust audio-visual correspondence on diverse data, then injects action control through fine-tuning on structured annotations, maintaining both audio-visual alignment and the model's text-following capabilities. Extensive experiments demonstrate that ActAvatar significantly outperforms state-of-the-art methods in both action control and visual quality.
Erased, But Not Forgotten: Erased Rectified Flow Transformers Still Remain Unsafe Under Concept Attack
Oct 01, 2025Recent advances in text-to-image (T2I) diffusion models have enabled impressive generative capabilities, but they also raise significant safety concerns due to the potential to produce harmful or undesirable content. While concept erasure has been explored as a mitigation strategy, most existing approaches and corresponding attack evaluations are tailored to Stable Diffusion (SD) and exhibit limited effectiveness when transferred to next-generation rectified flow transformers such as Flux. In this work, we present ReFlux, the first concept attack method specifically designed to assess the robustness of concept erasure in the latest rectified flow-based T2I framework. Our approach is motivated by the observation that existing concept erasure techniques, when applied to Flux, fundamentally rely on a phenomenon known as attention localization. Building on this insight, we propose a simple yet effective attack strategy that specifically targets this property. At its core, a reverse-attention optimization strategy is introduced to effectively reactivate suppressed signals while stabilizing attention. This is further reinforced by a velocity-guided dynamic that enhances the robustness of concept reactivation by steering the flow matching process, and a consistency-preserving objective that maintains the global layout and preserves unrelated content. Extensive experiments consistently demonstrate the effectiveness and efficiency of the proposed attack method, establishing a reliable benchmark for evaluating the robustness of concept erasure strategies in rectified flow transformers.
Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
Aug 28, 2025Vision-Language-Action (VLA) models have become a cornerstone in robotic policy learning, leveraging large-scale multimodal data for robust and scalable control. However, existing VLA frameworks primarily address short-horizon tasks, and their effectiveness on long-horizon, multi-step robotic manipulation remains limited due to challenges in skill chaining and subtask dependencies. In this work, we introduce Long-VLA, the first end-to-end VLA model specifically designed for long-horizon robotic tasks. Our approach features a novel phase-aware input masking strategy that adaptively segments each subtask into moving and interaction phases, enabling the model to focus on phase-relevant sensory cues and enhancing subtask compatibility. This unified strategy preserves the scalability and data efficiency of VLA training, and our architecture-agnostic module can be seamlessly integrated into existing VLA models. We further propose the L-CALVIN benchmark to systematically evaluate long-horizon manipulation. Extensive experiments on both simulated and real-world tasks demonstrate that Long-VLA significantly outperforms prior state-of-the-art methods, establishing a new baseline for long-horizon robotic control.
Can Structured Templates Facilitate LLMs in Tackling Harder Tasks? : An Exploration of Scaling Laws by Difficulty
Aug 26, 2025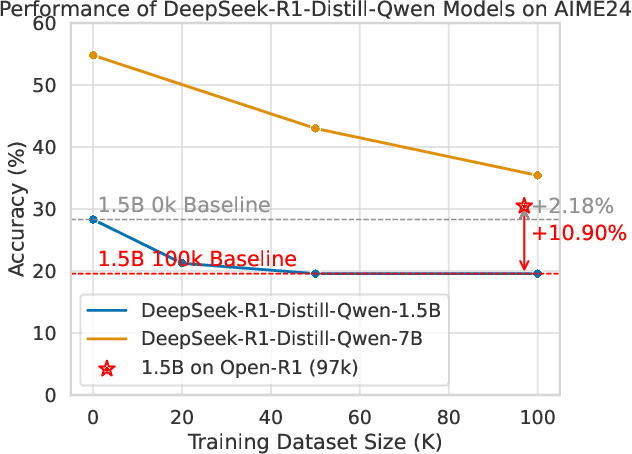
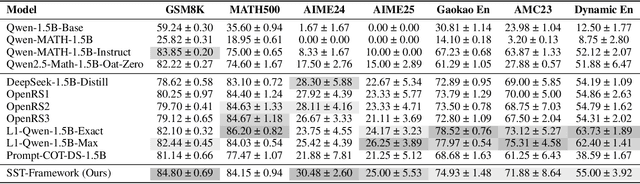
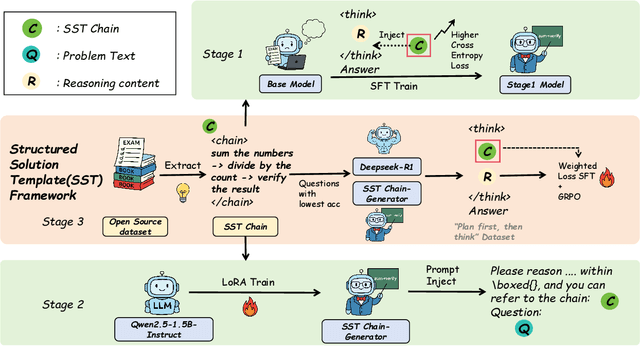

Structured, procedural reasoning is essential for Large Language Models (LLMs), especially in mathematics. While post-training methods have improved LLM performance, they still fall short in capturing deep procedural logic on complex tasks. To tackle the issue, in this paper, we first investigate this limitation and uncover a novel finding: a Scaling Law by Difficulty, which reveals that model performance follows a U-shaped curve with respect to training data complexity -- excessive low-difficulty data impedes abstraction, while high-difficulty data significantly enhances reasoning ability. Motivated by this, we propose the Structured Solution Template (SST) framework, which uses solution templates and a curriculum of varied difficulty to explicitly teach procedural reasoning. Specifically, SST comprises (1) fine-tuning with structured solution-template chains and dynamically weighted loss to prioritize procedural logic, (2) prompt-time injection of solution templates as cognitive scaffolds to guide inference, and (3) integrated curriculum fine-tuning that explicitly teaches the model to self-plan - execute - self-correct. Experiments on GSM8K, AIME24, and new Dynamic En benchmark show that SST significantly improves both accuracy and efficiency, especially on harder problems.
HieroAction: Hierarchically Guided VLM for Fine-Grained Action Analysis
Aug 23, 2025Evaluating human actions with clear and detailed feedback is important in areas such as sports, healthcare, and robotics, where decisions rely not only on final outcomes but also on interpretable reasoning. However, most existing methods provide only a final score without explanation or detailed analysis, limiting their practical applicability. To address this, we introduce HieroAction, a vision-language model that delivers accurate and structured assessments of human actions. HieroAction builds on two key ideas: (1) Stepwise Action Reasoning, a tailored chain of thought process designed specifically for action assessment, which guides the model to evaluate actions step by step, from overall recognition through sub action analysis to final scoring, thus enhancing interpretability and structured understanding; and (2) Hierarchical Policy Learning, a reinforcement learning strategy that enables the model to learn fine grained sub action dynamics and align them with high level action quality, thereby improving scoring precision. The reasoning pathway structures the evaluation process, while policy learning refines each stage through reward based optimization. Their integration ensures accurate and interpretable assessments, as demonstrated by superior performance across multiple benchmark datasets. Code will be released upon acceptance.
Mem4D: Decoupling Static and Dynamic Memory for Dynamic Scene Reconstruction
Aug 12, 2025Reconstructing dense geometry for dynamic scenes from a monocular video is a critical yet challenging task. Recent memory-based methods enable efficient online reconstruction, but they fundamentally suffer from a Memory Demand Dilemma: The memory representation faces an inherent conflict between the long-term stability required for static structures and the rapid, high-fidelity detail retention needed for dynamic motion. This conflict forces existing methods into a compromise, leading to either geometric drift in static structures or blurred, inaccurate reconstructions of dynamic objects. To address this dilemma, we propose Mem4D, a novel framework that decouples the modeling of static geometry and dynamic motion. Guided by this insight, we design a dual-memory architecture: 1) The Transient Dynamics Memory (TDM) focuses on capturing high-frequency motion details from recent frames, enabling accurate and fine-grained modeling of dynamic content; 2) The Persistent Structure Memory (PSM) compresses and preserves long-term spatial information, ensuring global consistency and drift-free reconstruction for static elements. By alternating queries to these specialized memories, Mem4D simultaneously maintains static geometry with global consistency and reconstructs dynamic elements with high fidelity. Experiments on challenging benchmarks demonstrate that our method achieves state-of-the-art or competitive performance while maintaining high efficiency. Codes will be publicly available.