 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniScale: Adaptive Unified Inference Scaling via Online Joint Optimization of Model Routing and Test-Time Scaling
May 29, 2026In real-world deployments of large language models (LLMs), balancing inference quality and computational cost has become a central challenge. Existing approaches tackle this trade-off along two largely independent dimensions: model routing, which switches among models of different scales to match request complexity, and test-time scaling (TTS), which adjusts inference-time compute within a fixed model for fine-grained control. However, this decoupled design introduces inherent limitations. Model routing yields coarse-grained, discrete performance changes due to the sparse set of model scales, while single-model TTS often encounters capacity ceilings and exhibits diminishing returns as compute increases. Moreover, treating the two mechanisms separately restricts adaptability in dynamic inference environments. To overcome these limitations, we introduce Unified Inference Scaling (UIS), which unifies model routing and TTS in a single optimization space. Building on this formulation, we propose UniScale, an online framework that models adaptive UIS as a contextual multi-armed bandit problem and learns inference policies via LinUCB. The framework incorporates efficiency-aware learning and cost modeling to ensure stable and scalable optimization over high-dimensional action spaces. Evaluation shows that UniScale effectively exploits the synergy in the UIS space to deliver a fine-grained and consistently better quality-cost trade-off across diverse, dynamic inference scenarios.
CUBic: Coordinated Unified Bimanual Perception and Control Framework
May 13, 2026Recent advances in visuomotor policy learning have enabled robots to perform control directly from visual inputs. Yet, extending such end-to-end learning from single-arm to bimanual manipulation remains challenging due to the need for both independent perception and coordinated interaction between arms. Existing methods typically favor one side -- either decoupling the two arms to avoid interference or enforcing strong cross-arm coupling for coordination -- thus lacking a unified treatment. We propose CUBic, a Coordinated and Unified framework for Bimanual perception and control that reformulates bimanual coordination as a unified perceptual modeling problem. CUBic learns a shared tokenized representation bridging perception and control, where independence and coordination emerge intrinsically from structure rather than from hand-crafted coupling. Our approach integrates three components: unidirectional perception aggregation, bidirectional perception coordination through two codebooks with shared mapping, and a unified perception-to-control diffusion policy. Extensive experiments on the RoboTwin benchmark show that CUBic consistently surpasses standard baselines, achieving marked improvements in coordination accuracy and task success rates over state-of-the-art visuomotor baselines.
FOZO: Forward-Only Zeroth-Order Prompt Optimization for Test-Time Adaptation
Mar 05, 2026Test-Time Adaptation (TTA) is essential for enabling deep learning models to handle real-world data distribution shifts. However, current approaches face significant limitations: backpropagation-based methods are not suitable for low-end deployment devices, due to their high computation and memory requirements, as well as their tendency to modify model weights during adaptation; while traditional backpropagation-free techniques exhibit constrained adaptation capabilities. In this work, we propose Forward-Only Zeroth-Order Optimization (FOZO), a novel and practical backpropagation-free paradigm for TTA. FOZO leverages a memory-efficient zeroth-order prompt optimization, which is led by objectives optimizing both intermediate feature statistics and prediction entropy. To ensure efficient and stable adaptation over the out-of-distribution data stream, we introduce a dynamically decaying perturbation scale during zeroth-order gradient estimation and theoretically prove its convergence under the TTA data stream assumption. Extensive continual adaptation experiments on ImageNet-C, ImageNet-R, and ImageNet-Sketch demonstrate FOZO's superior performance, achieving 59.52% Top-1 accuracy on ImageNet-C (5K, level 5) and outperforming main gradient-based methods and SOTA forward-only FOA (58.13%). Furthermore, FOZO exhibits strong generalization on quantized (INT8) models. These findings demonstrate that FOZO is a highly competitive solution for TTA deployment in resource-limited scenarios.
Chain-of-Talkers (CoTalk): Fast Human Annotation of Dense Image Captions
May 28, 2025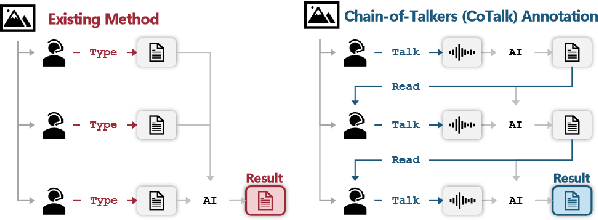

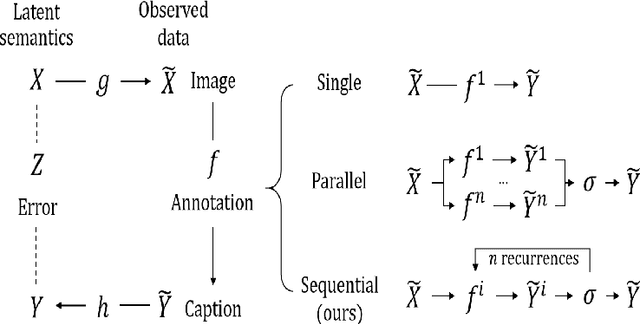
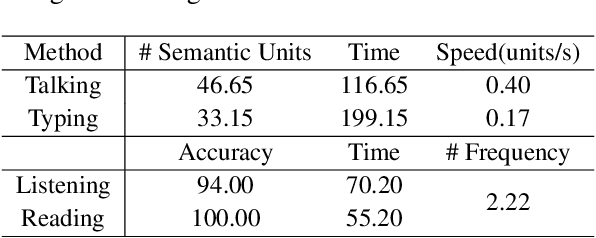
While densely annotated image captions significantly facilitate the learning of robust vision-language alignment, methodologies for systematically optimizing human annotation efforts remain underexplored. We introduce Chain-of-Talkers (CoTalk), an AI-in-the-loop methodology designed to maximize the number of annotated samples and improve their comprehensiveness under fixed budget constraints (e.g., total human annotation time). The framework is built upon two key insights. First, sequential annotation reduces redundant workload compared to conventional parallel annotation, as subsequent annotators only need to annotate the ``residual'' -- the missing visual information that previous annotations have not covered. Second, humans process textual input faster by reading while outputting annotations with much higher throughput via talking; thus a multimodal interface enables optimized efficiency. We evaluate our framework from two aspects: intrinsic evaluations that assess the comprehensiveness of semantic units, obtained by parsing detailed captions into object-attribute trees and analyzing their effective connections; extrinsic evaluation measures the practical usage of the annotated captions in facilitating vision-language alignment. Experiments with eight participants show our Chain-of-Talkers (CoTalk) improves annotation speed (0.42 vs. 0.30 units/sec) and retrieval performance (41.13\% vs. 40.52\%) over the parallel method.
HF-VTON: High-Fidelity Virtual Try-On via Consistent Geometric and Semantic Alignment
May 26, 2025Virtual try-on technology has become increasingly important in the fashion and retail industries, enabling the generation of high-fidelity garment images that adapt seamlessly to target human models. While existing methods have achieved notable progress, they still face significant challenges in maintaining consistency across different poses. Specifically, geometric distortions lead to a lack of spatial consistency, mismatches in garment structure and texture across poses result in semantic inconsistency, and the loss or distortion of fine-grained details diminishes visual fidelity. To address these challenges, we propose HF-VTON, a novel framework that ensures high-fidelity virtual try-on performance across diverse poses. HF-VTON consists of three key modules: (1) the Appearance-Preserving Warp Alignment Module (APWAM), which aligns garments to human poses, addressing geometric deformations and ensuring spatial consistency; (2) the Semantic Representation and Comprehension Module (SRCM), which captures fine-grained garment attributes and multi-pose data to enhance semantic representation, maintaining structural, textural, and pattern consistency; and (3) the Multimodal Prior-Guided Appearance Generation Module (MPAGM), which integrates multimodal features and prior knowledge from pre-trained models to optimize appearance generation, ensuring both semantic and geometric consistency. Additionally, to overcome data limitations in existing benchmarks, we introduce the SAMP-VTONS dataset, featuring multi-pose pairs and rich textual annotations for a more comprehensive evaluation. Experimental results demonstrate that HF-VTON outperforms state-of-the-art methods on both VITON-HD and SAMP-VTONS, excelling in visual fidelity, semantic consistency, and detail preservation.
DocMMIR: A Framework for Document Multi-modal Information Retrieval
May 25, 2025The rapid advancement of unsupervised representation learning and large-scale pre-trained vision-language models has significantly improved cross-modal retrieval tasks. However, existing multi-modal information retrieval (MMIR) studies lack a comprehensive exploration of document-level retrieval and suffer from the absence of cross-domain datasets at this granularity. To address this limitation, we introduce DocMMIR, a novel multi-modal document retrieval framework designed explicitly to unify diverse document formats and domains, including Wikipedia articles, scientific papers (arXiv), and presentation slides, within a comprehensive retrieval scenario. We construct a large-scale cross-domain multimodal benchmark, comprising 450K samples, which systematically integrates textual and visual information. Our comprehensive experimental analysis reveals substantial limitations in current state-of-the-art MLLMs (CLIP, BLIP2, SigLIP-2, ALIGN) when applied to our tasks, with only CLIP demonstrating reasonable zero-shot performance. Furthermore, we conduct a systematic investigation of training strategies, including cross-modal fusion methods and loss functions, and develop a tailored approach to train CLIP on our benchmark. This results in a +31% improvement in MRR@10 compared to the zero-shot baseline. All our data and code are released in https://github.com/J1mL1/DocMMIR.
TCC-Bench: Benchmarking the Traditional Chinese Culture Understanding Capabilities of MLLMs
May 19, 2025



Recent progress in Multimodal Large Language Models (MLLMs) have significantly enhanced the ability of artificial intelligence systems to understand and generate multimodal content. However, these models often exhibit limited effectiveness when applied to non-Western cultural contexts, which raises concerns about their wider applicability. To address this limitation, we propose the Traditional Chinese Culture understanding Benchmark (TCC-Bench), a bilingual (i.e., Chinese and English) Visual Question Answering (VQA) benchmark specifically designed for assessing the understanding of traditional Chinese culture by MLLMs. TCC-Bench comprises culturally rich and visually diverse data, incorporating images from museum artifacts, everyday life scenes, comics, and other culturally significant contexts. We adopt a semi-automated pipeline that utilizes GPT-4o in text-only mode to generate candidate questions, followed by human curation to ensure data quality and avoid potential data leakage. The benchmark also avoids language bias by preventing direct disclosure of cultural concepts within question texts. Experimental evaluations across a wide range of MLLMs demonstrate that current models still face significant challenges when reasoning about culturally grounded visual content. The results highlight the need for further research in developing culturally inclusive and context-aware multimodal systems. The code and data can be found at: https://tcc-bench.github.io/.
Multi-agent Multi-armed Bandit with Fully Heavy-tailed Dynamics
Jan 31, 2025We study decentralized multi-agent multi-armed bandits in fully heavy-tailed settings, where clients communicate over sparse random graphs with heavy-tailed degree distributions and observe heavy-tailed (homogeneous or heterogeneous) reward distributions with potentially infinite variance. The objective is to maximize system performance by pulling the globally optimal arm with the highest global reward mean across all clients. We are the first to address such fully heavy-tailed scenarios, which capture the dynamics and challenges in communication and inference among multiple clients in real-world systems. In homogeneous settings, our algorithmic framework exploits hub-like structures unique to heavy-tailed graphs, allowing clients to aggregate rewards and reduce noises via hub estimators when constructing UCB indices; under $M$ clients and degree distributions with power-law index $\alpha > 1$, our algorithm attains a regret bound (almost) of order $O(M^{1 -\frac{1}{\alpha}} \log{T})$. Under heterogeneous rewards, clients synchronize by communicating with neighbors, aggregating exchanged estimators in UCB indices; With our newly established information delay bounds on sparse random graphs, we prove a regret bound of $O(M \log{T})$. Our results improve upon existing work, which only address time-invariant connected graphs, or light-tailed dynamics in dense graphs and rewards.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024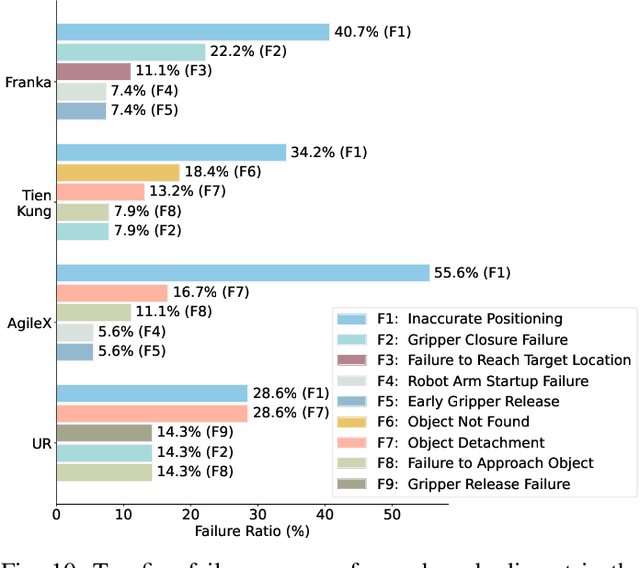
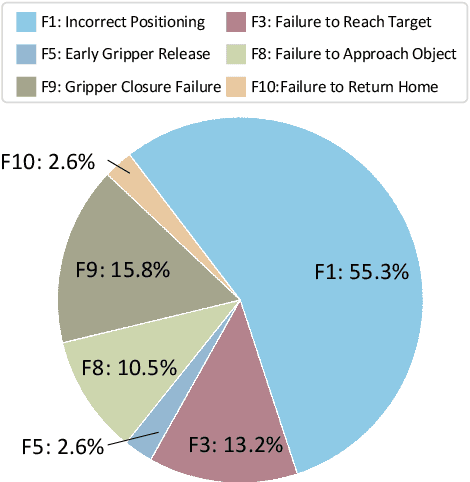
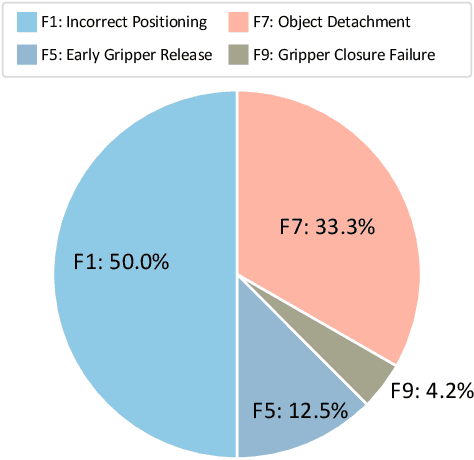
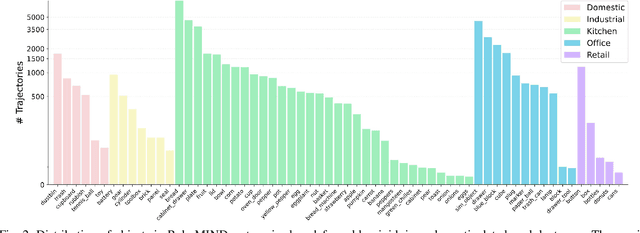
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
Benchmarking Multimodal Retrieval Augmented Generation with Dynamic VQA Dataset and Self-adaptive Planning Agent
Nov 05, 2024



Multimodal Retrieval Augmented Generation (mRAG) plays an important role in mitigating the "hallucination" issue inherent in multimodal large language models (MLLMs). Although promising, existing heuristic mRAGs typically predefined fixed retrieval processes, which causes two issues: (1) Non-adaptive Retrieval Queries. (2) Overloaded Retrieval Queries. However, these flaws cannot be adequately reflected by current knowledge-seeking visual question answering (VQA) datasets, since the most required knowledge can be readily obtained with a standard two-step retrieval. To bridge the dataset gap, we first construct Dyn-VQA dataset, consisting of three types of "dynamic" questions, which require complex knowledge retrieval strategies variable in query, tool, and time: (1) Questions with rapidly changing answers. (2) Questions requiring multi-modal knowledge. (3) Multi-hop questions. Experiments on Dyn-VQA reveal that existing heuristic mRAGs struggle to provide sufficient and precisely relevant knowledge for dynamic questions due to their rigid retrieval processes. Hence, we further propose the first self-adaptive planning agent for multimodal retrieval, OmniSearch. The underlying idea is to emulate the human behavior in question solution which dynamically decomposes complex multimodal questions into sub-question chains with retrieval action. Extensive experiments prove the effectiveness of our OmniSearch, also provide direction for advancing mRAG. The code and dataset will be open-sourced at https://github.com/Alibaba-NLP/OmniSearch.