 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIEG-Youpu Solution for NeurIPS 2022 WikiKG90Mv2-LSC
Mar 30, 2026WikiKG90Mv2 in NeurIPS 2022 is a large encyclopedic knowledge graph. Embedding knowledge graphs into continuous vector spaces is important for many practical applications, such as knowledge acquisition, question answering, and recommendation systems. Compared to existing knowledge graphs, WikiKG90Mv2 is a large scale knowledge graph, which is composed of more than 90 millions of entities. Both efficiency and accuracy should be considered when building graph embedding models for knowledge graph at scale. To this end, we follow the retrieve then re-rank pipeline, and make novel modifications in both retrieval and re-ranking stage. Specifically, we propose a priority infilling retrieval model to obtain candidates that are structurally and semantically similar. Then we propose an ensemble based re-ranking model with neighbor enhanced representations to produce final link prediction results among retrieved candidates. Experimental results show that our proposed method outperforms existing baseline methods and improves MRR of validation set from 0.2342 to 0.2839.
VisionNVS: Self-Supervised Inpainting for Novel View Synthesis under the Virtual-Shift Paradigm
Mar 18, 2026A fundamental bottleneck in Novel View Synthesis (NVS) for autonomous driving is the inherent supervision gap on novel trajectories: models are tasked with synthesizing unseen views during inference, yet lack ground truth images for these shifted poses during training. In this paper, we propose VisionNVS, a camera-only framework that fundamentally reformulates view synthesis from an ill-posed extrapolation problem into a self-supervised inpainting task. By introducing a ``Virtual-Shift'' strategy, we use monocular depth proxies to simulate occlusion patterns and map them onto the original view. This paradigm shift allows the use of raw, recorded images as pixel-perfect supervision, effectively eliminating the domain gap inherent in previous approaches. Furthermore, we address spatial consistency through a Pseudo-3D Seam Synthesis strategy, which integrates visual data from adjacent cameras during training to explicitly model real-world photometric discrepancies and calibration errors. Experiments demonstrate that VisionNVS achieves superior geometric fidelity and visual quality compared to LiDAR-dependent baselines, offering a robust solution for scalable driving simulation.
Disentangle Object and Non-object Infrared Features via Language Guidance
Jan 14, 2026Infrared object detection focuses on identifying and locating objects in complex environments (\eg, dark, snow, and rain) where visible imaging cameras are disabled by poor illumination. However, due to low contrast and weak edge information in infrared images, it is challenging to extract discriminative object features for robust detection. To deal with this issue, we propose a novel vision-language representation learning paradigm for infrared object detection. An additional textual supervision with rich semantic information is explored to guide the disentanglement of object and non-object features. Specifically, we propose a Semantic Feature Alignment (SFA) module to align the object features with the corresponding text features. Furthermore, we develop an Object Feature Disentanglement (OFD) module that disentangles text-aligned object features and non-object features by minimizing their correlation. Finally, the disentangled object features are entered into the detection head. In this manner, the detection performance can be remarkably enhanced via more discriminative and less noisy features. Extensive experimental results demonstrate that our approach achieves superior performance on two benchmarks: M\textsuperscript{3}FD (83.7\% mAP), FLIR (86.1\% mAP). Our code will be publicly available once the paper is accepted.
Each Prompt Matters: Scaling Reinforcement Learning Without Wasting Rollouts on Hundred-Billion-Scale MoE
Dec 08, 2025We present CompassMax-V3-Thinking, a hundred-billion-scale MoE reasoning model trained with a new RL framework built on one principle: each prompt must matter. Scaling RL to this size exposes critical inefficiencies-zero-variance prompts that waste rollouts, unstable importance sampling over long horizons, advantage inversion from standard reward models, and systemic bottlenecks in rollout processing. To overcome these challenges, we introduce several unified innovations: (1) Multi-Stage Zero-Variance Elimination, which filters out non-informative prompts and stabilizes group-based policy optimization (e.g. GRPO) by removing wasted rollouts; (2) ESPO, an entropy-adaptive optimization method that balances token-level and sequence-level importance sampling to maintain stable learning dynamics; (3) a Router Replay strategy that aligns training-time MoE router decisions with inference-time behavior to mitigate train-infer discrepancies, coupled with a reward model adjustment to prevent advantage inversion; (4) a high-throughput RL system with FP8-precision rollouts, overlapped reward computation, and length-aware scheduling to eliminate performance bottlenecks. Together, these contributions form a cohesive pipeline that makes RL on hundred-billion-scale MoE models stable and efficient. The resulting model delivers strong performance across both internal and public evaluations.
Chain-of-Talkers (CoTalk): Fast Human Annotation of Dense Image Captions
May 28, 2025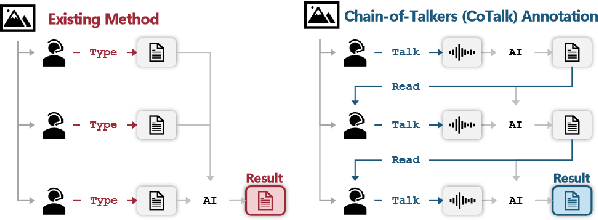

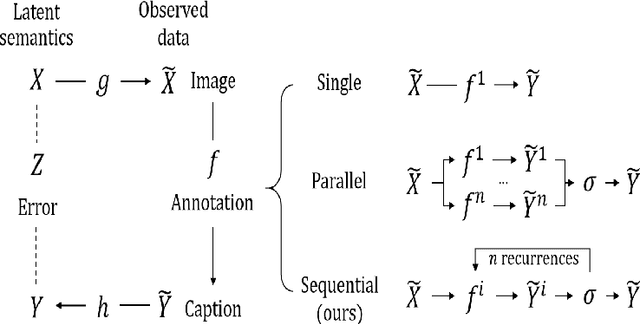
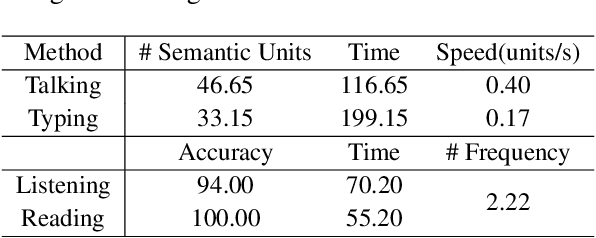
While densely annotated image captions significantly facilitate the learning of robust vision-language alignment, methodologies for systematically optimizing human annotation efforts remain underexplored. We introduce Chain-of-Talkers (CoTalk), an AI-in-the-loop methodology designed to maximize the number of annotated samples and improve their comprehensiveness under fixed budget constraints (e.g., total human annotation time). The framework is built upon two key insights. First, sequential annotation reduces redundant workload compared to conventional parallel annotation, as subsequent annotators only need to annotate the ``residual'' -- the missing visual information that previous annotations have not covered. Second, humans process textual input faster by reading while outputting annotations with much higher throughput via talking; thus a multimodal interface enables optimized efficiency. We evaluate our framework from two aspects: intrinsic evaluations that assess the comprehensiveness of semantic units, obtained by parsing detailed captions into object-attribute trees and analyzing their effective connections; extrinsic evaluation measures the practical usage of the annotated captions in facilitating vision-language alignment. Experiments with eight participants show our Chain-of-Talkers (CoTalk) improves annotation speed (0.42 vs. 0.30 units/sec) and retrieval performance (41.13\% vs. 40.52\%) over the parallel method.
RemoteSAM: Towards Segment Anything for Earth Observation
May 23, 2025
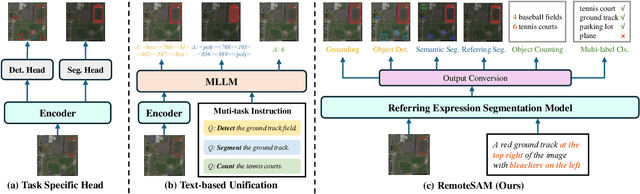
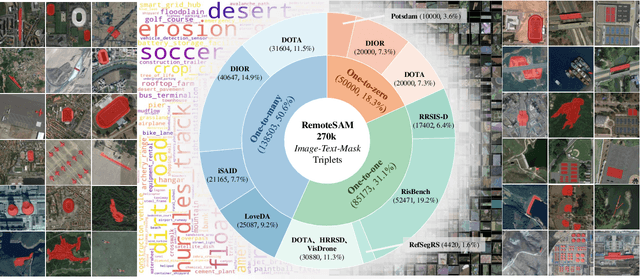
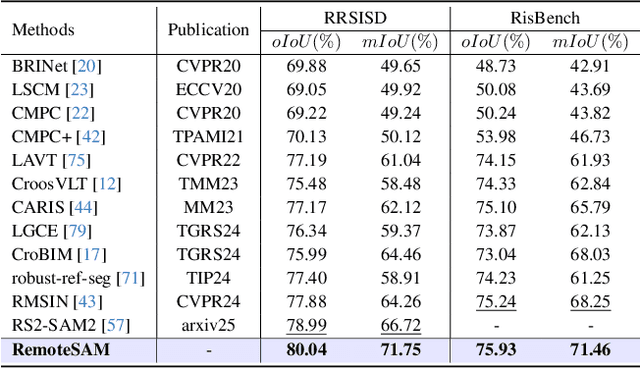
We aim to develop a robust yet flexible visual foundation model for Earth observation. It should possess strong capabilities in recognizing and localizing diverse visual targets while providing compatibility with various input-output interfaces required across different task scenarios. Current systems cannot meet these requirements, as they typically utilize task-specific architecture trained on narrow data domains with limited semantic coverage. Our study addresses these limitations from two aspects: data and modeling. We first introduce an automatic data engine that enjoys significantly better scalability compared to previous human annotation or rule-based approaches. It has enabled us to create the largest dataset of its kind to date, comprising 270K image-text-mask triplets covering an unprecedented range of diverse semantic categories and attribute specifications. Based on this data foundation, we further propose a task unification paradigm that centers around referring expression segmentation. It effectively handles a wide range of vision-centric perception tasks, including classification, detection, segmentation, grounding, etc, using a single model without any task-specific heads. Combining these innovations on data and modeling, we present RemoteSAM, a foundation model that establishes new SoTA on several earth observation perception benchmarks, outperforming other foundation models such as Falcon, GeoChat, and LHRS-Bot with significantly higher efficiency. Models and data are publicly available at https://github.com/1e12Leon/RemoteSAM.
Ultrasound Report Generation with Multimodal Large Language Models for Standardized Texts
May 13, 2025Ultrasound (US) report generation is a challenging task due to the variability of US images, operator dependence, and the need for standardized text. Unlike X-ray and CT, US imaging lacks consistent datasets, making automation difficult. In this study, we propose a unified framework for multi-organ and multilingual US report generation, integrating fragment-based multilingual training and leveraging the standardized nature of US reports. By aligning modular text fragments with diverse imaging data and curating a bilingual English-Chinese dataset, the method achieves consistent and clinically accurate text generation across organ sites and languages. Fine-tuning with selective unfreezing of the vision transformer (ViT) further improves text-image alignment. Compared to the previous state-of-the-art KMVE method, our approach achieves relative gains of about 2\% in BLEU scores, approximately 3\% in ROUGE-L, and about 15\% in CIDEr, while significantly reducing errors such as missing or incorrect content. By unifying multi-organ and multi-language report generation into a single, scalable framework, this work demonstrates strong potential for real-world clinical workflows.
RemoteTrimmer: Adaptive Structural Pruning for Remote Sensing Image Classification
Dec 17, 2024
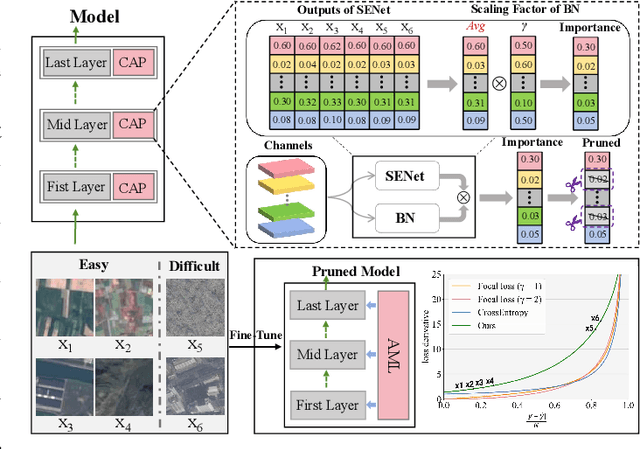
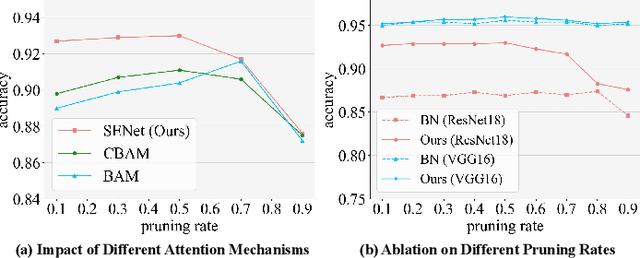
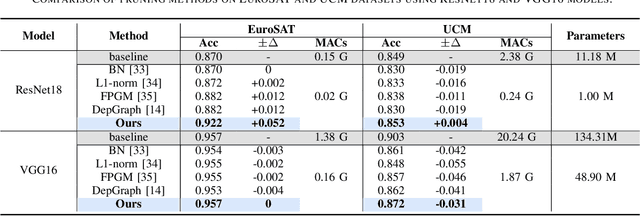
Since high resolution remote sensing image classification often requires a relatively high computation complexity, lightweight models tend to be practical and efficient. Model pruning is an effective method for model compression. However, existing methods rarely take into account the specificity of remote sensing images, resulting in significant accuracy loss after pruning. To this end, we propose an effective structural pruning approach for remote sensing image classification. Specifically, a pruning strategy that amplifies the differences in channel importance of the model is introduced. Then an adaptive mining loss function is designed for the fine-tuning process of the pruned model. Finally, we conducted experiments on two remote sensing classification datasets. The experimental results demonstrate that our method achieves minimal accuracy loss after compressing remote sensing classification models, achieving state-of-the-art (SoTA) performance.
Domain-invariant Progressive Knowledge Distillation for UAV-based Object Detection
Aug 21, 2024
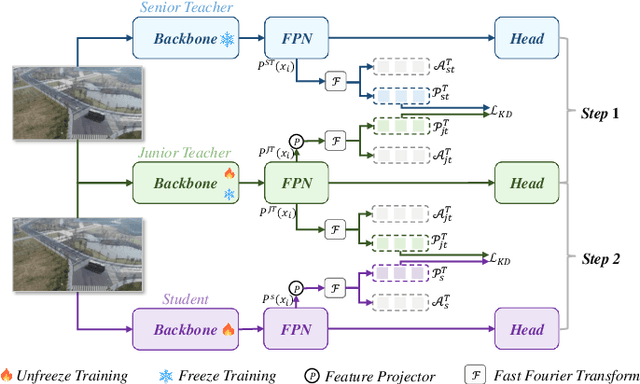
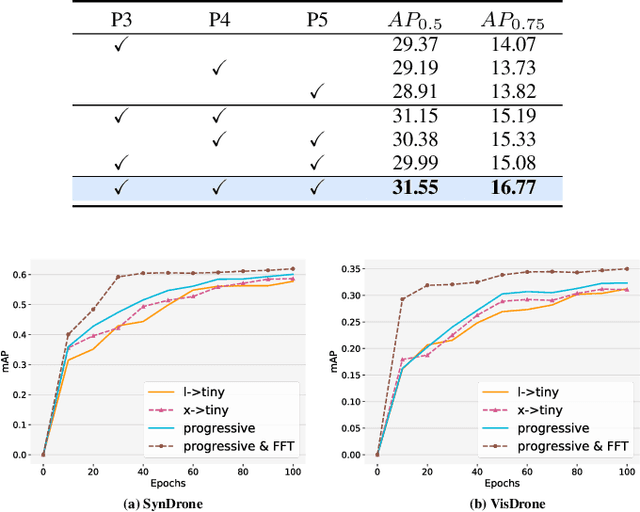
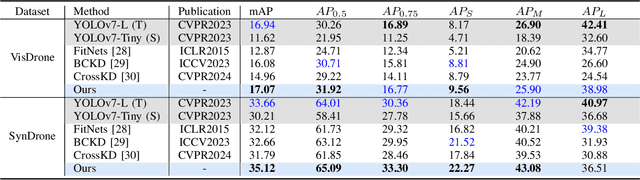
Knowledge distillation (KD) is an effective method for compressing models in object detection tasks. Due to limited computational capability, UAV-based object detection (UAV-OD) widely adopt the KD technique to obtain lightweight detectors. Existing methods often overlook the significant differences in feature space caused by the large gap in scale between the teacher and student models. This limitation hampers the efficiency of knowledge transfer during the distillation process. Furthermore, the complex backgrounds in UAV images make it challenging for the student model to efficiently learn the object features. In this paper, we propose a novel knowledge distillation framework for UAV-OD. Specifically, a progressive distillation approach is designed to alleviate the feature gap between teacher and student models. Then a new feature alignment method is provided to extract object-related features for enhancing student model's knowledge reception efficiency. Finally, extensive experiments are conducted to validate the effectiveness of our proposed approach. The results demonstrate that our proposed method achieves state-of-the-art (SoTA) performance in two UAV-OD datasets.
UEMM-Air: A Synthetic Multi-modal Dataset for Unmanned Aerial Vehicle Object Detection
Jun 10, 2024



The development of multi-modal object detection for Unmanned Aerial Vehicles (UAVs) typically relies on a large amount of pixel-aligned multi-modal image data. However, existing datasets face challenges such as limited modalities, high construction costs, and imprecise annotations. To this end, we propose a synthetic multi-modal UAV-based object detection dataset, UEMM-Air. Specially, we simulate various UAV flight scenarios and object types using the Unreal Engine (UE). Then we design the UAV's flight logic to automatically collect data from different scenarios, perspectives, and altitudes. Finally, we propose a novel heuristic automatic annotation algorithm to generate accurate object detection labels. In total, our UEMM-Air consists of 20k pairs of images with 5 modalities and precise annotations. Moreover, we conduct numerous experiments and establish new benchmark results on our dataset. We found that models pre-trained on UEMM-Air exhibit better performance on downstream tasks compared to other similar datasets. The dataset is publicly available (https://github.com/1e12Leon/UEMM-Air) to support the research of multi-modal UAV object detection models.