 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFriend Recall in Online Games via Pre-training Edge Transformers
Feb 20, 2023



Friend recall is an important way to improve Daily Active Users (DAU) in Tencent games. Traditional friend recall methods focus on rules like friend intimacy or training a classifier for predicting lost players' return probability, but ignore feature information of (active) players and historical friend recall events. In this work, we treat friend recall as a link prediction problem and explore several link prediction methods which can use features of both active and lost players, as well as historical events. Furthermore, we propose a novel Edge Transformer model and pre-train the model via masked auto-encoders. Our method achieves state-of-the-art results in the offline experiments and online A/B Tests of three Tencent games.
Learning High-order Structural and Attribute information by Knowledge Graph Attention Networks for Enhancing Knowledge Graph Embedding
Oct 10, 2019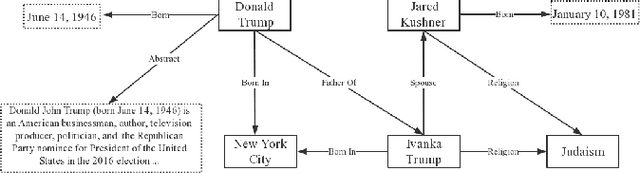



The goal of representation learning of knowledge graph is to encode both entities and relations into a low-dimensional embedding spaces. Many recent works have demonstrated the benefits of knowledge graph embedding on knowledge graph completion task, such as relation extraction. However, we observe that: 1) existing method just take direct relations between entities into consideration and fails to express high-order structural relationship between entities; 2) these methods just leverage relation triples of KGs while ignoring a large number of attribute triples that encoding rich semantic information. To overcome these limitations, this paper propose a novel knowledge graph embedding method, named KANE, which is inspired by the recent developments of graph convolutional networks (GCN). KANE can capture both high-order structural and attribute information of KGs in an efficient, explicit and unified manner under the graph convolutional networks framework. Empirical results on three datasets show that KANE significantly outperforms seven state-of-arts methods. Further analysis verify the efficiency of our method and the benefits brought by the attention mechanism.
Effective and Efficient Network Embedding Initialization via Graph Partitioning
Aug 28, 2019
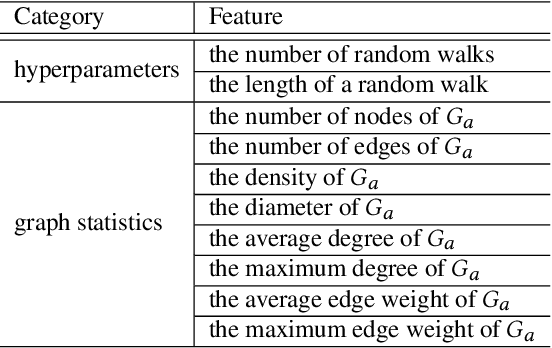
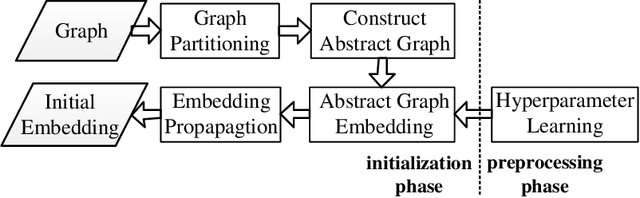
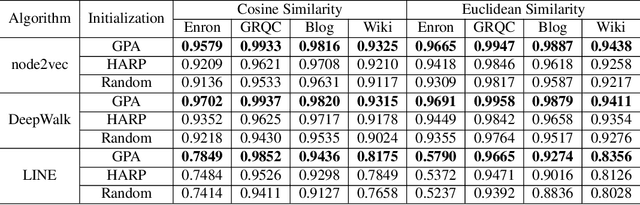
Network embedding has been intensively studied in the literature and widely used in various applications, such as link prediction and node classification. While previous work focus on the design of new algorithms or are tailored for various problem settings, the discussion of initialization strategies in the learning process is often missed. In this work, we address this important issue of initialization for network embedding that could dramatically improve the performance of the algorithms on both effectiveness and efficiency. Specifically, we first exploit the graph partition technique that divides the graph into several disjoint subsets, and then construct an abstract graph based on the partitions. We obtain the initialization of the embedding for each node in the graph by computing the network embedding on the abstract graph, which is much smaller than the input graph, and then propagating the embedding among the nodes in the input graph. With extensive experiments on various datasets, we demonstrate that our initialization technique significantly improves the performance of the state-of-the-art algorithms on the evaluations of link prediction and node classification by up to 7.76% and 8.74% respectively. Besides, we show that the technique of initialization reduces the running time of the state-of-the-arts by at least 20%.
A Comprehensive Survey of Graph Embedding: Problems, Techniques and Applications
Feb 02, 2018



Graph is an important data representation which appears in a wide diversity of real-world scenarios. Effective graph analytics provides users a deeper understanding of what is behind the data, and thus can benefit a lot of useful applications such as node classification, node recommendation, link prediction, etc. However, most graph analytics methods suffer the high computation and space cost. Graph embedding is an effective yet efficient way to solve the graph analytics problem. It converts the graph data into a low dimensional space in which the graph structural information and graph properties are maximally preserved. In this survey, we conduct a comprehensive review of the literature in graph embedding. We first introduce the formal definition of graph embedding as well as the related concepts. After that, we propose two taxonomies of graph embedding which correspond to what challenges exist in different graph embedding problem settings and how the existing work address these challenges in their solutions. Finally, we summarize the applications that graph embedding enables and suggest four promising future research directions in terms of computation efficiency, problem settings, techniques and application scenarios.
From Node Embedding To Community Embedding
Sep 14, 2017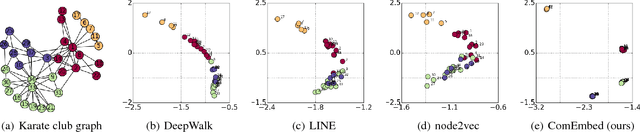
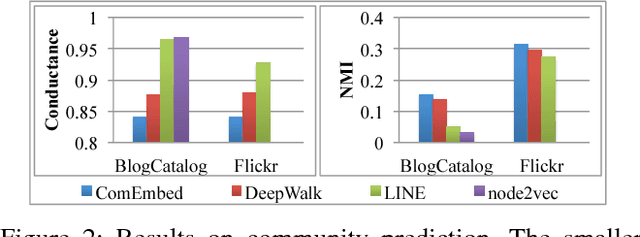
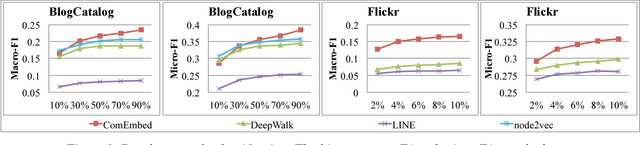
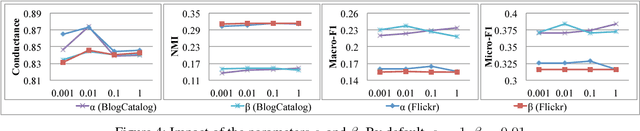
Most of the existing graph embedding methods focus on nodes, which aim to output a vector representation for each node in the graph such that two nodes being "close" on the graph are close too in the low-dimensional space. Despite the success of embedding individual nodes for graph analytics, we notice that an important concept of embedding communities (i.e., groups of nodes) is missing. Embedding communities is useful, not only for supporting various community-level applications, but also to help preserve community structure in graph embedding. In fact, we see community embedding as providing a higher-order proximity to define the node closeness, whereas most of the popular graph embedding methods focus on first-order and/or second-order proximities. To learn the community embedding, we hinge upon the insight that community embedding and node embedding reinforce with each other. As a result, we propose ComEmbed, the first community embedding method, which jointly optimizes the community embedding and node embedding together. We evaluate ComEmbed on real-world data sets. We show it outperforms the state-of-the-art baselines in both tasks of node classification and community prediction.
Active Learning for Graph Embedding
May 15, 2017



Graph embedding provides an efficient solution for graph analysis by converting the graph into a low-dimensional space which preserves the structure information. In contrast to the graph structure data, the i.i.d. node embedding can be processed efficiently in terms of both time and space. Current semi-supervised graph embedding algorithms assume the labelled nodes are given, which may not be always true in the real world. While manually label all training data is inapplicable, how to select the subset of training data to label so as to maximize the graph analysis task performance is of great importance. This motivates our proposed active graph embedding (AGE) framework, in which we design a general active learning query strategy for any semi-supervised graph embedding algorithm. AGE selects the most informative nodes as the training labelled nodes based on the graphical information (i.e., node centrality) as well as the learnt node embedding (i.e., node classification uncertainty and node embedding representativeness). Different query criteria are combined with the time-sensitive parameters which shift the focus from graph based query criteria to embedding based criteria as the learning progresses. Experiments have been conducted on three public data sets and the results verified the effectiveness of each component of our query strategy and the power of combining them using time-sensitive parameters. Our code is available online at: https://github.com/vwz/AGE.
From Community Detection to Community Profiling
Jan 17, 2017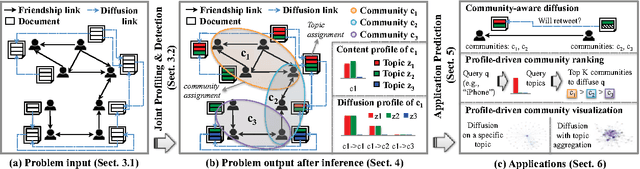



Most existing community-related studies focus on detection, which aim to find the community membership for each user from user friendship links. However, membership alone, without a complete profile of what a community is and how it interacts with other communities, has limited applications. This motivates us to consider systematically profiling the communities and thereby developing useful community-level applications. In this paper, we for the first time formalize the concept of community profiling. With rich user information on the network, such as user published content and user diffusion links, we characterize a community in terms of both its internal content profile and external diffusion profile. The difficulty of community profiling is often underestimated. We novelly identify three unique challenges and propose a joint Community Profiling and Detection (CPD) model to address them accordingly. We also contribute a scalable inference algorithm, which scales linearly with the data size and it is easily parallelizable. We evaluate CPD on large-scale real-world data sets, and show that it is significantly better than the state-of-the-art baselines in various tasks.