 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical and Secure Federated Recommendation with Personalized Masks
Aug 18, 2021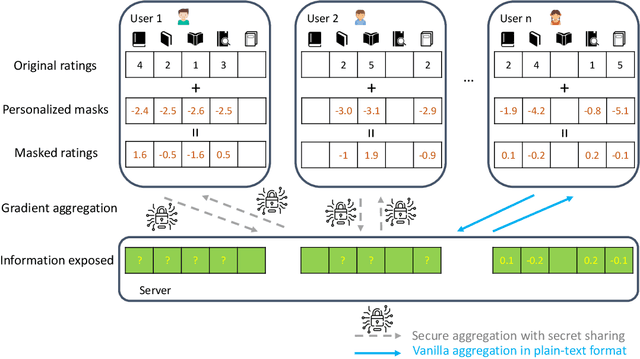
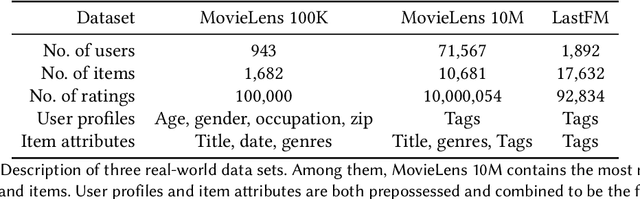


Federated recommendation is a new notion of private distributed recommender systems. It aims to address the data silo and privacy problems altogether. Current federated recommender systems mainly utilize homomorphic encryption and differential privacy methods to protect the intermediate computational results. However, the former comes with extra communication and computation costs, the latter damages model accuracy. Neither of them could simultaneously satisfy the real-time feedback and accurate personalization requirements of recommender systems. In this paper, we proposed a new federated recommendation framework, named federated masked matrix factorization. Federated masked matrix factorization could protect the data privacy in federated recommender systems without sacrificing efficiency or efficacy. Instead of using homomorphic encryption and differential privacy, we utilize the secret sharing technique to incorporate the secure aggregation process of federated matrix factorization. Compared with homomorphic encryption, secret sharing largely speeds up the whole training process. In addition, we introduce a new idea of personalized masks and apply it in the proposed federated masked matrix factorization framework. On the one hand, personalized masks could further improve efficiency. On the other hand, personalized masks also benefit efficacy. Empirically, we show the superiority of the designed model on different real-world data sets. Besides, we also provide the privacy guarantee and discuss the extension of the personalized mask method to the general federated learning tasks.
Adam revisited: a weighted past gradients perspective
Jan 01, 2021



Adaptive learning rate methods have been successfully applied in many fields, especially in training deep neural networks. Recent results have shown that adaptive methods with exponential increasing weights on squared past gradients (i.e., ADAM, RMSPROP) may fail to converge to the optimal solution. Though many algorithms, such as AMSGRAD and ADAMNC, have been proposed to fix the non-convergence issues, achieving a data-dependent regret bound similar to or better than ADAGRAD is still a challenge to these methods. In this paper, we propose a novel adaptive method weighted adaptive algorithm (WADA) to tackle the non-convergence issues. Unlike AMSGRAD and ADAMNC, we consider using a milder growing weighting strategy on squared past gradient, in which weights grow linearly. Based on this idea, we propose weighted adaptive gradient method framework (WAGMF) and implement WADA algorithm on this framework. Moreover, we prove that WADA can achieve a weighted data-dependent regret bound, which could be better than the original regret bound of ADAGRAD when the gradients decrease rapidly. This bound may partially explain the good performance of ADAM in practice. Finally, extensive experiments demonstrate the effectiveness of WADA and its variants in comparison with several variants of ADAM on training convex problems and deep neural networks.
* Zhong, Hui, et al. "Adam revisited: a weighted past gradients perspective." Frontiers of Computer Science 14.5 (2020): 1-16
Privacy Threats Against Federated Matrix Factorization
Jul 03, 2020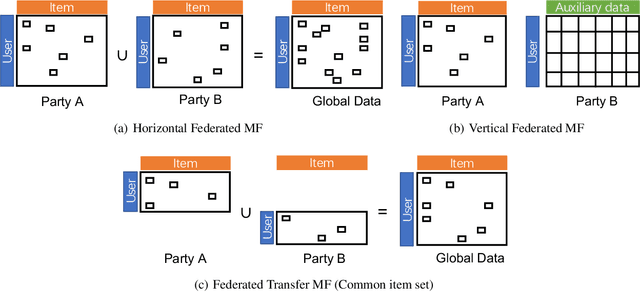
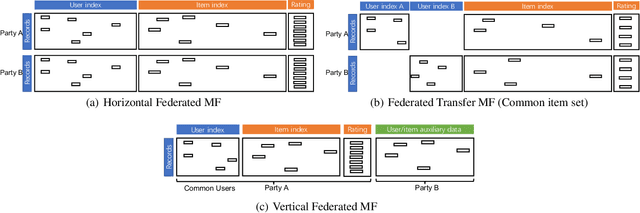
Matrix Factorization has been very successful in practical recommendation applications and e-commerce. Due to data shortage and stringent regulations, it can be hard to collect sufficient data to build performant recommender systems for a single company. Federated learning provides the possibility to bridge the data silos and build machine learning models without compromising privacy and security. Participants sharing common users or items collaboratively build a model over data from all the participants. There have been some works exploring the application of federated learning to recommender systems and the privacy issues in collaborative filtering systems. However, the privacy threats in federated matrix factorization are not studied. In this paper, we categorize federated matrix factorization into three types based on the partition of feature space and analyze privacy threats against each type of federated matrix factorization model. We also discuss privacy-preserving approaches. As far as we are aware, this is the first study of privacy threats of the matrix factorization method in the federated learning framework.
Vertex-reinforced Random Walk for Network Embedding
Feb 11, 2020
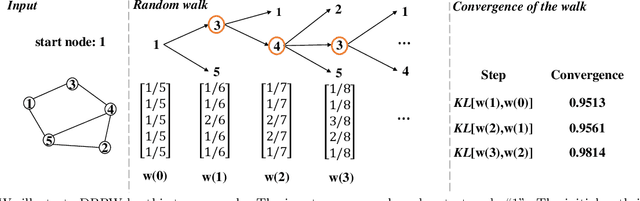
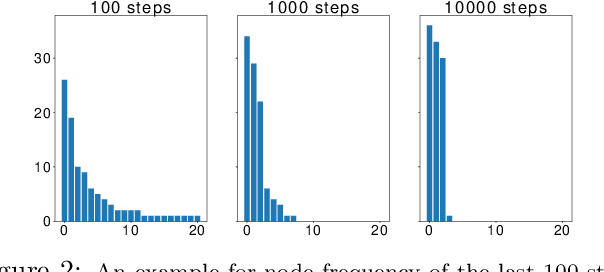
In this paper, we study the fundamental problem of random walk for network embedding. We propose to use non-Markovian random walk, variants of vertex-reinforced random walk (VRRW), to fully use the history of a random walk path. To solve the getting stuck problem of VRRW, we introduce an exploitation-exploration mechanism to help the random walk jump out of the stuck set. The new random walk algorithms share the same convergence property of VRRW and thus can be used to learn stable network embeddings. Experimental results on two link prediction benchmark datasets and three node classification benchmark datasets show that our proposed approach reinforce2vec can outperform state-of-the-art random walk based embedding methods by a large margin.
A Simple Regularization-based Algorithm for Learning Cross-Domain Word Embeddings
Feb 01, 2019

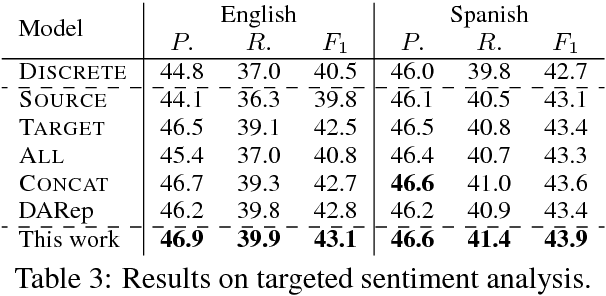
Learning word embeddings has received a significant amount of attention recently. Often, word embeddings are learned in an unsupervised manner from a large collection of text. The genre of the text typically plays an important role in the effectiveness of the resulting embeddings. How to effectively train word embedding models using data from different domains remains a problem that is underexplored. In this paper, we present a simple yet effective method for learning word embeddings based on text from different domains. We demonstrate the effectiveness of our approach through extensive experiments on various down-stream NLP tasks.
* 7 pages, accepted by EMNLP 2017
Deep Transfer Learning for Cross-domain Activity Recognition
Aug 19, 2018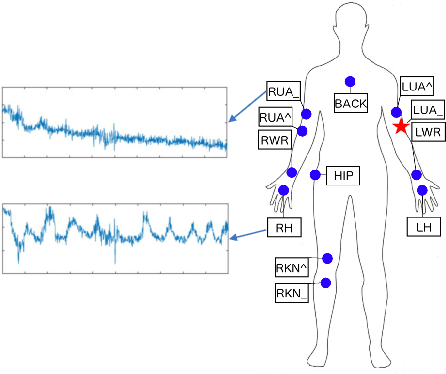
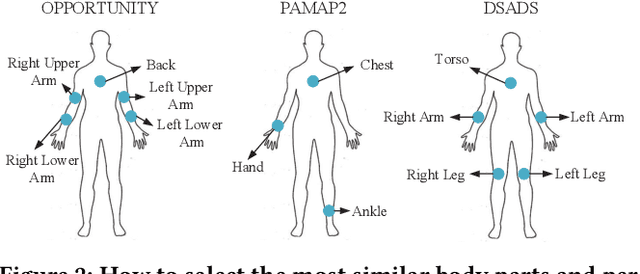
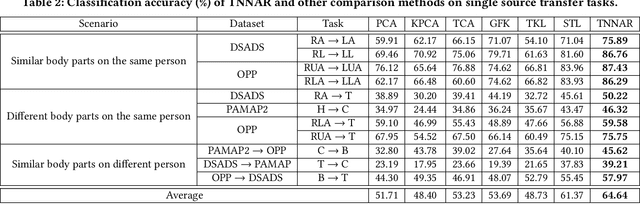
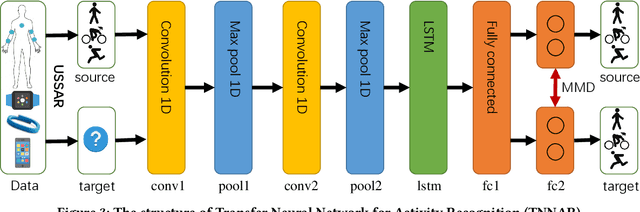
Human activity recognition plays an important role in people's daily life. However, it is often expensive and time-consuming to acquire sufficient labeled activity data. To solve this problem, transfer learning leverages the labeled samples from the source domain to annotate the target domain which has few or none labels. Unfortunately, when there are several source domains available, it is difficult to select the right source domains for transfer. The right source domain means that it has the most similar properties with the target domain, thus their similarity is higher, which can facilitate transfer learning. Choosing the right source domain helps the algorithm perform well and prevents the negative transfer. In this paper, we propose an effective Unsupervised Source Selection algorithm for Activity Recognition (USSAR). USSAR is able to select the most similar $K$ source domains from a list of available domains. After this, we propose an effective Transfer Neural Network to perform knowledge transfer for Activity Recognition (TNNAR). TNNAR could capture both the time and spatial relationship between activities while transferring knowledge. Experiments on three public activity recognition datasets demonstrate that: 1) The USSAR algorithm is effective in selecting the best source domains. 2) The TNNAR method can reach high accuracy when performing activity knowledge transfer.
A Comprehensive Survey of Graph Embedding: Problems, Techniques and Applications
Feb 02, 2018



Graph is an important data representation which appears in a wide diversity of real-world scenarios. Effective graph analytics provides users a deeper understanding of what is behind the data, and thus can benefit a lot of useful applications such as node classification, node recommendation, link prediction, etc. However, most graph analytics methods suffer the high computation and space cost. Graph embedding is an effective yet efficient way to solve the graph analytics problem. It converts the graph data into a low dimensional space in which the graph structural information and graph properties are maximally preserved. In this survey, we conduct a comprehensive review of the literature in graph embedding. We first introduce the formal definition of graph embedding as well as the related concepts. After that, we propose two taxonomies of graph embedding which correspond to what challenges exist in different graph embedding problem settings and how the existing work address these challenges in their solutions. Finally, we summarize the applications that graph embedding enables and suggest four promising future research directions in terms of computation efficiency, problem settings, techniques and application scenarios.
Topological Recurrent Neural Network for Diffusion Prediction
Nov 29, 2017

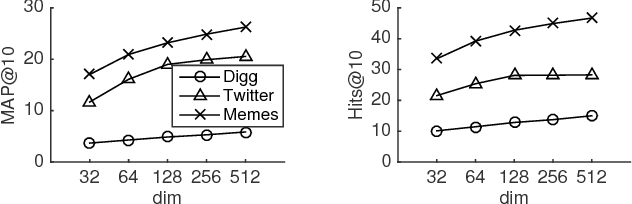

In this paper, we study the problem of using representation learning to assist information diffusion prediction on graphs. In particular, we aim at estimating the probability of an inactive node to be activated next in a cascade. Despite the success of recent deep learning methods for diffusion, we find that they often underexplore the cascade structure. We consider a cascade as not merely a sequence of nodes ordered by their activation time stamps; instead, it has a richer structure indicating the diffusion process over the data graph. As a result, we introduce a new data model, namely diffusion topologies, to fully describe the cascade structure. We find it challenging to model diffusion topologies, which are dynamic directed acyclic graphs (DAGs), with the existing neural networks. Therefore, we propose a novel topological recurrent neural network, namely Topo-LSTM, for modeling dynamic DAGs. We customize Topo-LSTM for the diffusion prediction task, and show it improves the state-of-the-art baselines, by 20.1%--56.6% (MAP) relatively, across multiple real-world data sets. Our code and data sets are available online at https://github.com/vwz/topolstm.
From Node Embedding To Community Embedding
Sep 14, 2017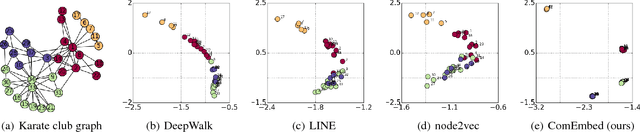
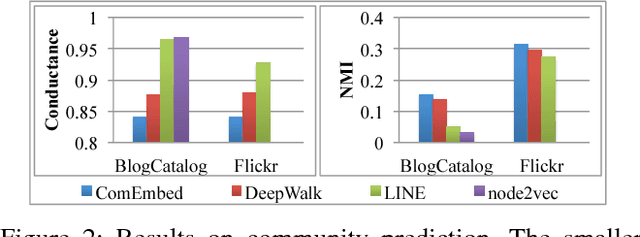
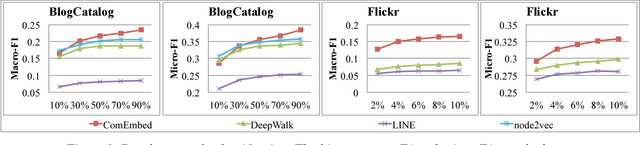
Most of the existing graph embedding methods focus on nodes, which aim to output a vector representation for each node in the graph such that two nodes being "close" on the graph are close too in the low-dimensional space. Despite the success of embedding individual nodes for graph analytics, we notice that an important concept of embedding communities (i.e., groups of nodes) is missing. Embedding communities is useful, not only for supporting various community-level applications, but also to help preserve community structure in graph embedding. In fact, we see community embedding as providing a higher-order proximity to define the node closeness, whereas most of the popular graph embedding methods focus on first-order and/or second-order proximities. To learn the community embedding, we hinge upon the insight that community embedding and node embedding reinforce with each other. As a result, we propose ComEmbed, the first community embedding method, which jointly optimizes the community embedding and node embedding together. We evaluate ComEmbed on real-world data sets. We show it outperforms the state-of-the-art baselines in both tasks of node classification and community prediction.
Active Learning for Graph Embedding
May 15, 2017



Graph embedding provides an efficient solution for graph analysis by converting the graph into a low-dimensional space which preserves the structure information. In contrast to the graph structure data, the i.i.d. node embedding can be processed efficiently in terms of both time and space. Current semi-supervised graph embedding algorithms assume the labelled nodes are given, which may not be always true in the real world. While manually label all training data is inapplicable, how to select the subset of training data to label so as to maximize the graph analysis task performance is of great importance. This motivates our proposed active graph embedding (AGE) framework, in which we design a general active learning query strategy for any semi-supervised graph embedding algorithm. AGE selects the most informative nodes as the training labelled nodes based on the graphical information (i.e., node centrality) as well as the learnt node embedding (i.e., node classification uncertainty and node embedding representativeness). Different query criteria are combined with the time-sensitive parameters which shift the focus from graph based query criteria to embedding based criteria as the learning progresses. Experiments have been conducted on three public data sets and the results verified the effectiveness of each component of our query strategy and the power of combining them using time-sensitive parameters. Our code is available online at: https://github.com/vwz/AGE.