 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
RGL: A Graph-Centric, Modular Framework for Efficient Retrieval-Augmented Generation on Graphs
Mar 25, 2025Recent advances in graph learning have paved the way for innovative retrieval-augmented generation (RAG) systems that leverage the inherent relational structures in graph data. However, many existing approaches suffer from rigid, fixed settings and significant engineering overhead, limiting their adaptability and scalability. Additionally, the RAG community has largely overlooked the decades of research in the graph database community regarding the efficient retrieval of interesting substructures on large-scale graphs. In this work, we introduce the RAG-on-Graphs Library (RGL), a modular framework that seamlessly integrates the complete RAG pipeline-from efficient graph indexing and dynamic node retrieval to subgraph construction, tokenization, and final generation-into a unified system. RGL addresses key challenges by supporting a variety of graph formats and integrating optimized implementations for essential components, achieving speedups of up to 143x compared to conventional methods. Moreover, its flexible utilities, such as dynamic node filtering, allow for rapid extraction of pertinent subgraphs while reducing token consumption. Our extensive evaluations demonstrate that RGL not only accelerates the prototyping process but also enhances the performance and applicability of graph-based RAG systems across a range of tasks.
Automatic Pruning via Structured Lasso with Class-wise Information
Feb 13, 2025Most pruning methods concentrate on unimportant filters of neural networks. However, they face the loss of statistical information due to a lack of consideration for class-wise data. In this paper, from the perspective of leveraging precise class-wise information for model pruning, we utilize structured lasso with guidance from Information Bottleneck theory. Our approach ensures that statistical information is retained during the pruning process. With these techniques, we introduce two innovative adaptive network pruning schemes: sparse graph-structured lasso pruning with Information Bottleneck (\textbf{sGLP-IB}) and sparse tree-guided lasso pruning with Information Bottleneck (\textbf{sTLP-IB}). The key aspect is pruning model filters using sGLP-IB and sTLP-IB to better capture class-wise relatedness. Compared to multiple state-of-the-art methods, our approaches demonstrate superior performance across three datasets and six model architectures in extensive experiments. For instance, using the VGG16 model on the CIFAR-10 dataset, we achieve a parameter reduction of 85%, a decrease in FLOPs by 61%, and maintain an accuracy of 94.10% (0.14% higher than the original model); we reduce the parameters by 55% with the accuracy at 76.12% using the ResNet architecture on ImageNet (only drops 0.03%). In summary, we successfully reduce model size and computational resource usage while maintaining accuracy. Our codes are at https://anonymous.4open.science/r/IJCAI-8104.
One-shot Federated Learning Methods: A Practical Guide
Feb 13, 2025One-shot Federated Learning (OFL) is a distributed machine learning paradigm that constrains client-server communication to a single round, addressing privacy and communication overhead issues associated with multiple rounds of data exchange in traditional Federated Learning (FL). OFL demonstrates the practical potential for integration with future approaches that require collaborative training models, such as large language models (LLMs). However, current OFL methods face two major challenges: data heterogeneity and model heterogeneity, which result in subpar performance compared to conventional FL methods. Worse still, despite numerous studies addressing these limitations, a comprehensive summary is still lacking. To address these gaps, this paper presents a systematic analysis of the challenges faced by OFL and thoroughly reviews the current methods. We also offer an innovative categorization method and analyze the trade-offs of various techniques. Additionally, we discuss the most promising future directions and the technologies that should be integrated into the OFL field. This work aims to provide guidance and insights for future research.
Partitioning Message Passing for Graph Fraud Detection
Nov 16, 2024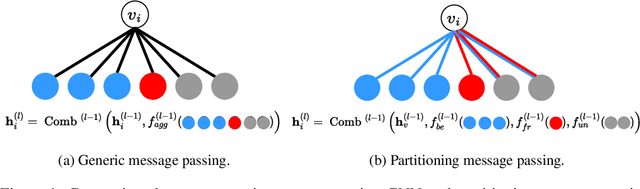
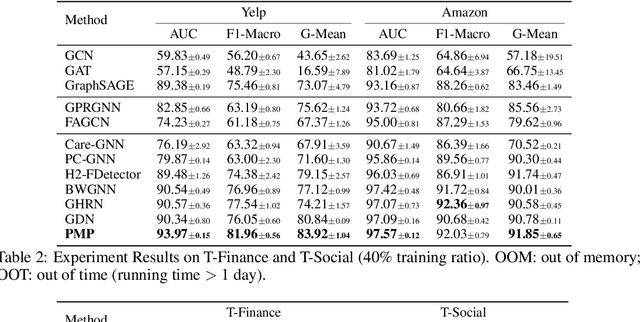
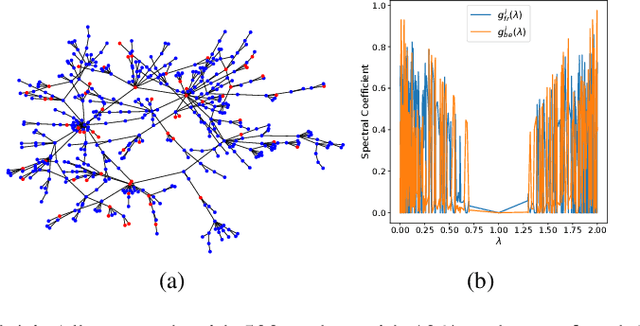
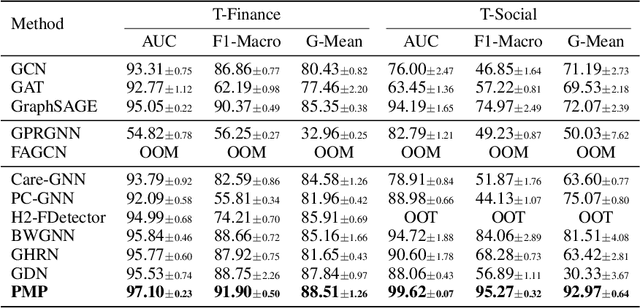
Label imbalance and homophily-heterophily mixture are the fundamental problems encountered when applying Graph Neural Networks (GNNs) to Graph Fraud Detection (GFD) tasks. Existing GNN-based GFD models are designed to augment graph structure to accommodate the inductive bias of GNNs towards homophily, by excluding heterophilic neighbors during message passing. In our work, we argue that the key to applying GNNs for GFD is not to exclude but to {\em distinguish} neighbors with different labels. Grounded in this perspective, we introduce Partitioning Message Passing (PMP), an intuitive yet effective message passing paradigm expressly crafted for GFD. Specifically, in the neighbor aggregation stage of PMP, neighbors with different classes are aggregated with distinct node-specific aggregation functions. By this means, the center node can adaptively adjust the information aggregated from its heterophilic and homophilic neighbors, thus avoiding the model gradient being dominated by benign nodes which occupy the majority of the population. We theoretically establish a connection between the spatial formulation of PMP and spectral analysis to characterize that PMP operates an adaptive node-specific spectral graph filter, which demonstrates the capability of PMP to handle heterophily-homophily mixed graphs. Extensive experimental results show that PMP can significantly boost the performance on GFD tasks.
ED-ViT: Splitting Vision Transformer for Distributed Inference on Edge Devices
Oct 15, 2024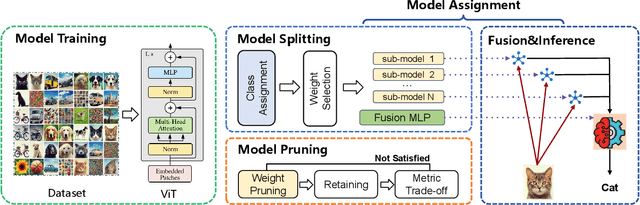

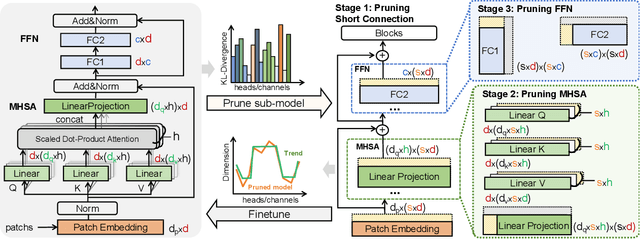
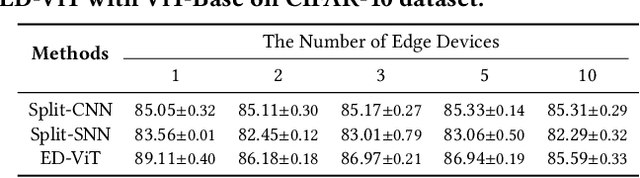
Deep learning models are increasingly deployed on resource-constrained edge devices for real-time data analytics. In recent years, Vision Transformer models and their variants have demonstrated outstanding performance across various computer vision tasks. However, their high computational demands and inference latency pose significant challenges for model deployment on resource-constraint edge devices. To address this issue, we propose a novel Vision Transformer splitting framework, ED-ViT, designed to execute complex models across multiple edge devices efficiently. Specifically, we partition Vision Transformer models into several sub-models, where each sub-model is tailored to handle a specific subset of data classes. To further minimize computation overhead and inference latency, we introduce a class-wise pruning technique that reduces the size of each sub-model. We conduct extensive experiments on five datasets with three model structures, demonstrating that our approach significantly reduces inference latency on edge devices and achieves a model size reduction of up to 28.9 times and 34.1 times, respectively, while maintaining test accuracy comparable to the original Vision Transformer. Additionally, we compare ED-ViT with two state-of-the-art methods that deploy CNN and SNN models on edge devices, evaluating accuracy, inference time, and overall model size. Our comprehensive evaluation underscores the effectiveness of the proposed ED-ViT framework.
BuffGraph: Enhancing Class-Imbalanced Node Classification via Buffer Nodes
Feb 20, 2024



Class imbalance in graph-structured data, where minor classes are significantly underrepresented, poses a critical challenge for Graph Neural Networks (GNNs). To address this challenge, existing studies generally generate new minority nodes and edges connecting new nodes to the original graph to make classes balanced. However, they do not solve the problem that majority classes still propagate information to minority nodes by edges in the original graph which introduces bias towards majority classes. To address this, we introduce BuffGraph, which inserts buffer nodes into the graph, modulating the impact of majority classes to improve minor class representation. Our extensive experiments across diverse real-world datasets empirically demonstrate that BuffGraph outperforms existing baseline methods in class-imbalanced node classification in both natural settings and imbalanced settings. Code is available at https://anonymous.4open.science/r/BuffGraph-730A.
Advancing Graph Representation Learning with Large Language Models: A Comprehensive Survey of Techniques
Feb 04, 2024
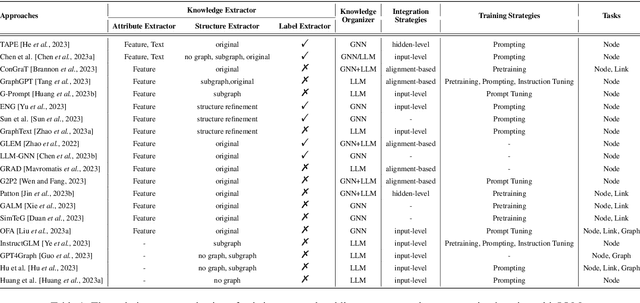
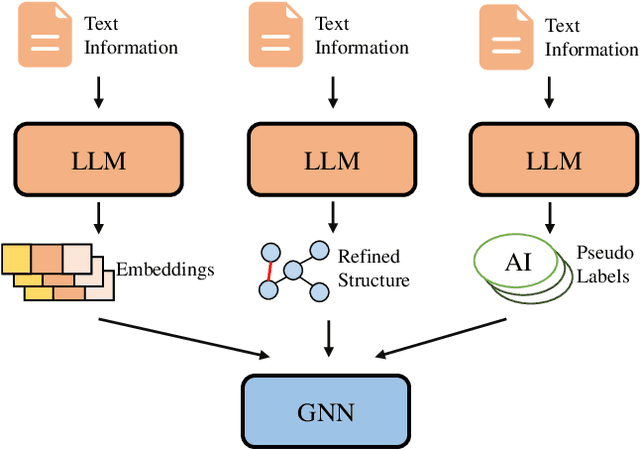
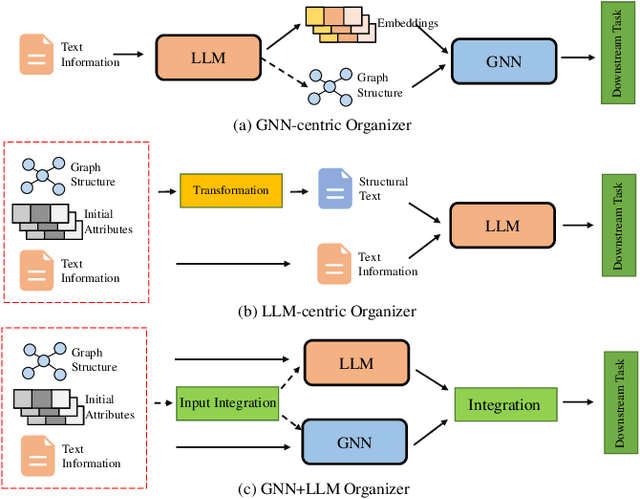
The integration of Large Language Models (LLMs) with Graph Representation Learning (GRL) marks a significant evolution in analyzing complex data structures. This collaboration harnesses the sophisticated linguistic capabilities of LLMs to improve the contextual understanding and adaptability of graph models, thereby broadening the scope and potential of GRL. Despite a growing body of research dedicated to integrating LLMs into the graph domain, a comprehensive review that deeply analyzes the core components and operations within these models is notably lacking. Our survey fills this gap by proposing a novel taxonomy that breaks down these models into primary components and operation techniques from a novel technical perspective. We further dissect recent literature into two primary components including knowledge extractors and organizers, and two operation techniques including integration and training stratigies, shedding light on effective model design and training strategies. Additionally, we identify and explore potential future research avenues in this nascent yet underexplored field, proposing paths for continued progress.
Few-Shot Learning on Graphs: from Meta-learning to Pre-training and Prompting
Feb 02, 2024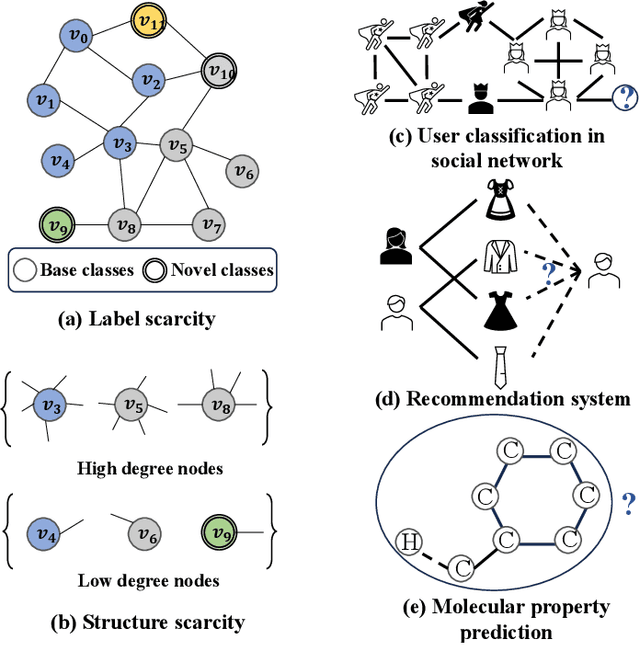
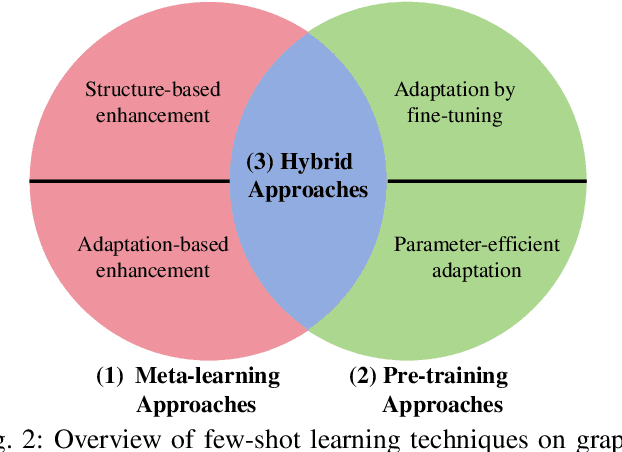
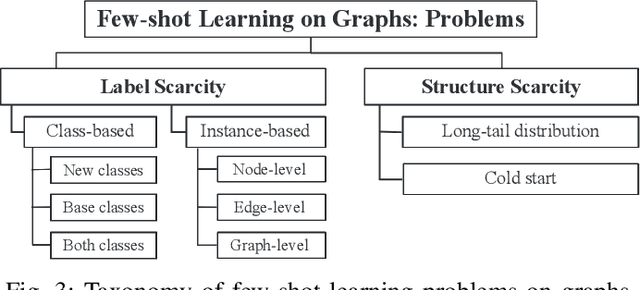
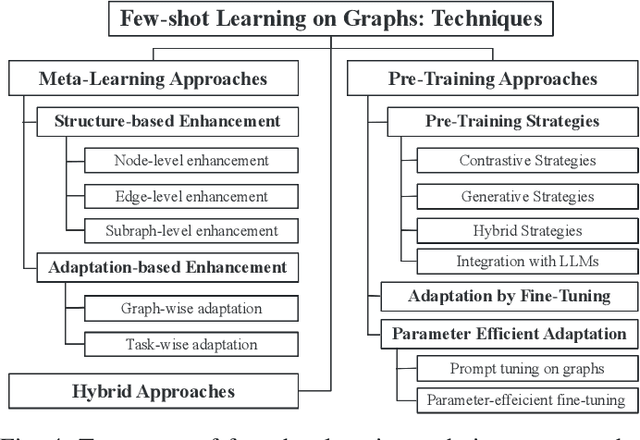
Graph representation learning, a critical step in graph-centric tasks, has seen significant advancements. Earlier techniques often operate in an end-to-end setting, where performance heavily relies on the availability of ample labeled data. This constraint has spurred the emergence of few-shot learning on graphs, where only a few task-specific labels are available for each task. Given the extensive literature in this field, this survey endeavors to synthesize recent developments, provide comparative insights, and identify future directions. We systematically categorize existing studies into three major families: meta-learning approaches, pre-training approaches, and hybrid approaches, with a finer-grained classification in each family to aid readers in their method selection process. Within each category, we analyze the relationships among these methods and compare their strengths and limitations. Finally, we outline prospective future directions for few-shot learning on graphs to catalyze continued innovation in this field.
HGPROMPT: Bridging Homogeneous and Heterogeneous Graphs for Few-shot Prompt Learning
Dec 04, 2023Graph neural networks (GNNs) and heterogeneous graph neural networks (HGNNs) are prominent techniques for homogeneous and heterogeneous graph representation learning, yet their performance in an end-to-end supervised framework greatly depends on the availability of task-specific supervision. To reduce the labeling cost, pre-training on self-supervised pretext tasks has become a popular paradigm,but there is often a gap between the pre-trained model and downstream tasks, stemming from the divergence in their objectives. To bridge the gap, prompt learning has risen as a promising direction especially in few-shot settings, without the need to fully fine-tune the pre-trained model. While there has been some early exploration of prompt-based learning on graphs, they primarily deal with homogeneous graphs, ignoring the heterogeneous graphs that are prevalent in downstream applications. In this paper, we propose HGPROMPT, a novel pre-training and prompting framework to unify not only pre-training and downstream tasks but also homogeneous and heterogeneous graphs via a dual-template design. Moreover, we propose dual-prompt in HGPROMPT to assist a downstream task in locating the most relevant prior to bridge the gaps caused by not only feature variations but also heterogeneity differences across tasks. Finally, we thoroughly evaluate and analyze HGPROMPT through extensive experiments on three public datasets.