 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: Contrastive Masked Feature Reconstruction on Graphs
Dec 15, 2025In the rapidly evolving field of self-supervised learning on graphs, generative and contrastive methodologies have emerged as two dominant approaches. Our study focuses on masked feature reconstruction (MFR), a generative technique where a model learns to restore the raw features of masked nodes in a self-supervised manner. We observe that both MFR and graph contrastive learning (GCL) aim to maximize agreement between similar elements. Building on this observation, we reveal a novel theoretical insight: under specific conditions, the objectives of MFR and node-level GCL converge, despite their distinct operational mechanisms. This theoretical connection suggests these approaches are complementary rather than fundamentally different, prompting us to explore their integration to enhance self-supervised learning on graphs. Our research presents Contrastive Masked Feature Reconstruction (CORE), a novel graph self-supervised learning framework that integrates contrastive learning into MFR. Specifically, we form positive pairs exclusively between the original and reconstructed features of masked nodes, encouraging the encoder to prioritize contextual information over the node's own features. Additionally, we leverage the masked nodes themselves as negative samples, combining MFR's reconstructive power with GCL's discriminative ability to better capture intrinsic graph structures. Empirically, our proposed framework CORE significantly outperforms MFR across node and graph classification tasks, demonstrating state-of-the-art results. In particular, CORE surpasses GraphMAE and GraphMAE2 by up to 2.80% and 3.72% on node classification tasks, and by up to 3.82% and 3.76% on graph classification tasks.
Contrastive General Graph Matching with Adaptive Augmentation Sampling
Jun 25, 2024



Graph matching has important applications in pattern recognition and beyond. Current approaches predominantly adopt supervised learning, demanding extensive labeled data which can be limited or costly. Meanwhile, self-supervised learning methods for graph matching often require additional side information such as extra categorical information and input features, limiting their application to the general case. Moreover, designing the optimal graph augmentations for self-supervised graph matching presents another challenge to ensure robustness and efficacy. To address these issues, we introduce a novel Graph-centric Contrastive framework for Graph Matching (GCGM), capitalizing on a vast pool of graph augmentations for contrastive learning, yet without needing any side information. Given the variety of augmentation choices, we further introduce a Boosting-inspired Adaptive Augmentation Sampler (BiAS), which adaptively selects more challenging augmentations tailored for graph matching. Through various experiments, our GCGM surpasses state-of-the-art self-supervised methods across various datasets, marking a significant step toward more effective, efficient and general graph matching.
Few-Shot Learning on Graphs: from Meta-learning to Pre-training and Prompting
Feb 02, 2024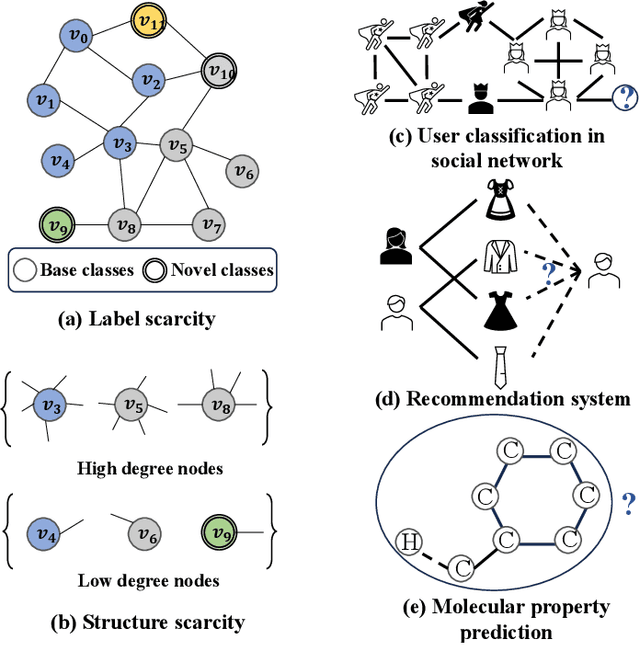
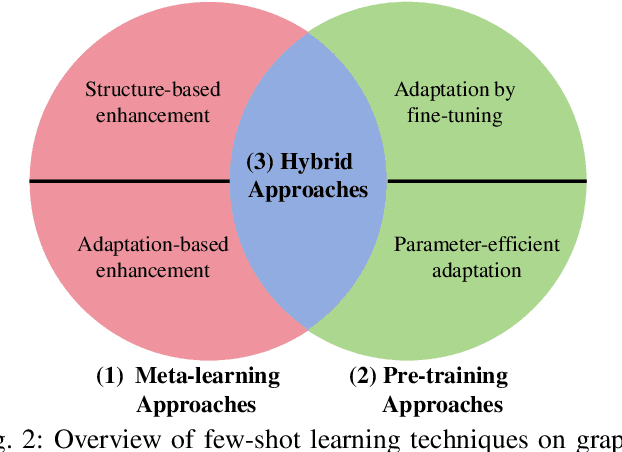
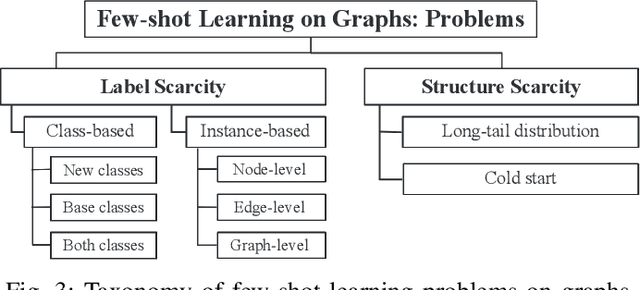
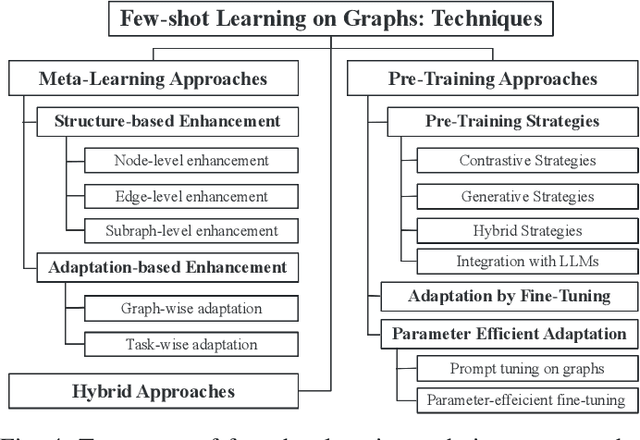
Graph representation learning, a critical step in graph-centric tasks, has seen significant advancements. Earlier techniques often operate in an end-to-end setting, where performance heavily relies on the availability of ample labeled data. This constraint has spurred the emergence of few-shot learning on graphs, where only a few task-specific labels are available for each task. Given the extensive literature in this field, this survey endeavors to synthesize recent developments, provide comparative insights, and identify future directions. We systematically categorize existing studies into three major families: meta-learning approaches, pre-training approaches, and hybrid approaches, with a finer-grained classification in each family to aid readers in their method selection process. Within each category, we analyze the relationships among these methods and compare their strengths and limitations. Finally, we outline prospective future directions for few-shot learning on graphs to catalyze continued innovation in this field.