 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering as Reasoning: A $k$-Means Interpretation of Chain-of-Thought Graph Learning
May 24, 2026Chain-of-Thought (CoT) prompting has shown promise in enhancing the reasoning capabilities of large language models (LLMs) on text-attributed graphs (TAGs). This work reframes CoT-based graph learning through the principle of clustering as reasoning, offering a $k$-means interpretation of how iterative reasoning operates over graph-structured data. We observe that existing graph CoT methods rely on disjoint architectures and fixed graph representations, limiting step-by-step semantic-topological interaction and interpretability. To overcome this limitation, we propose a unified framework named KCoT that integrates CoT reasoning with graph representation learning. Our key theoretical result reveals a formal mathematical correspondence between a Transformer block and the $k$-means algorithm, allowing reasoning to be interpreted as iterative assignment and update steps. Based on this insight, we introduce a Semantic Discriminating Prompt that explicitly formulates these steps as structured CoT reasoning, together with a structure-grounded alignment strategy to fuse topological priors with evolving thought-conditioned representations. Experiments on standard benchmarks demonstrate consistent improvements over state-of-the-art methods, validating clustering as a principled mechanism for CoT-based graph learning.
PrimeKG-CL: A Continual Graph Learning Benchmark on Evolving Biomedical Knowledge Graphs
May 11, 2026Biomedical knowledge graphs underwrite drug repurposing and clinical decision support, yet the upstream ontologies they depend on update on independent cycles that add millions of edges and deprecate hundreds of thousands more between releases. Yet existing continual graph learning has been studied almost exclusively on synthetic random splits of static, generic KGs, a regime that cannot reproduce the asynchronous, structured evolution real biomedical KGs undergo. To this end, we introduce PrimeKG-CL, a CGL benchmark built from nine authoritative biomedical databases (129K+ nodes, 8.1M+ edges, 10 node types, 30 relation types) with two genuine temporal snapshots (June 2021, July 2023; 5.83M edges added, 889K removed, 7.21M persistent), 10 entity-type-grouped tasks, multimodal node features, and a per-task persistent/added/removed test stratification. On three tasks (biomedical relationship prediction, entity classification, KGQA), we evaluate six CL strategies across four KGE decoders, plus LKGE, an LLM-RAG agent, and CMKL. We find that decoder choice and continual learning strategy interact strongly: no single strategy performs best across all decoders, and mismatched combinations can significantly degrade performance. Moreover, only DistMult exhibits a clear separation between persistent and deprecated knowledge, indicating that standard metrics conflate retention of still-valid facts with failure to forget outdated ones; this effect is absent under RotatE. In addition, multimodal features improve entity-level tasks by up to 60%, and a recent CKGE framework (IncDE) failed to scale to our 5.67M-triple base task across five attempts up to 350GB RAM. Data, pipeline, baselines, and the stratified split are released openly. Dataset:huggingface.co/datasets/yradwan147/PrimeKGCL|Code:github.com/yradwan147/primekg-cl-neurips2026
UrbanGraphEmbeddings: Learning and Evaluating Spatially Grounded Multimodal Embeddings for Urban Science
Feb 09, 2026Learning transferable multimodal embeddings for urban environments is challenging because urban understanding is inherently spatial, yet existing datasets and benchmarks lack explicit alignment between street-view images and urban structure. We introduce UGData, a spatially grounded dataset that anchors street-view images to structured spatial graphs and provides graph-aligned supervision via spatial reasoning paths and spatial context captions, exposing distance, directionality, connectivity, and neighborhood context beyond image content. Building on UGData, we propose UGE, a two-stage training strategy that progressively and stably aligns images, text, and spatial structures by combining instruction-guided contrastive learning with graph-based spatial encoding. We finally introduce UGBench, a comprehensive benchmark to evaluate how spatially grounded embeddings support diverse urban understanding tasks -- including geolocation ranking, image retrieval, urban perception, and spatial grounding. We develop UGE on multiple state-of-the-art VLM backbones, including Qwen2-VL, Qwen2.5-VL, Phi-3-Vision, and LLaVA1.6-Mistral, and train fixed-dimensional spatial embeddings with LoRA tuning. UGE built upon Qwen2.5-VL-7B backbone achieves up to 44% improvement in image retrieval and 30% in geolocation ranking on training cities, and over 30% and 22% gains respectively on held-out cities, demonstrating the effectiveness of explicit spatial grounding for spatially intensive urban tasks.
MolGA: Molecular Graph Adaptation with Pre-trained 2D Graph Encoder
Oct 08, 2025Molecular graph representation learning is widely used in chemical and biomedical research. While pre-trained 2D graph encoders have demonstrated strong performance, they overlook the rich molecular domain knowledge associated with submolecular instances (atoms and bonds). While molecular pre-training approaches incorporate such knowledge into their pre-training objectives, they typically employ designs tailored to a specific type of knowledge, lacking the flexibility to integrate diverse knowledge present in molecules. Hence, reusing widely available and well-validated pre-trained 2D encoders, while incorporating molecular domain knowledge during downstream adaptation, offers a more practical alternative. In this work, we propose MolGA, which adapts pre-trained 2D graph encoders to downstream molecular applications by flexibly incorporating diverse molecular domain knowledge. First, we propose a molecular alignment strategy that bridge the gap between pre-trained topological representations with domain-knowledge representations. Second, we introduce a conditional adaptation mechanism that generates instance-specific tokens to enable fine-grained integration of molecular domain knowledge for downstream tasks. Finally, we conduct extensive experiments on eleven public datasets, demonstrating the effectiveness of MolGA.
Taming Recommendation Bias with Causal Intervention on Evolving Personal Popularity
May 20, 2025
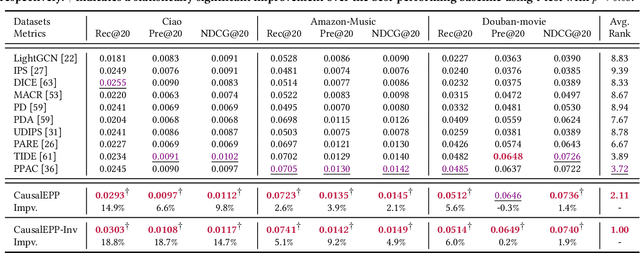

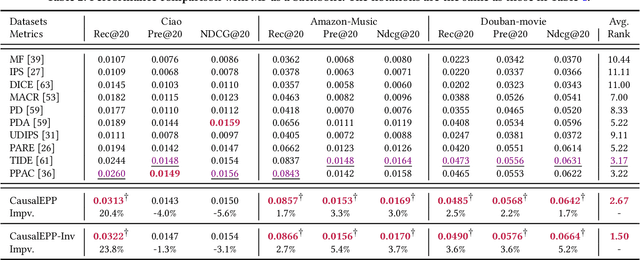
Popularity bias occurs when popular items are recommended far more frequently than they should be, negatively impacting both user experience and recommendation accuracy. Existing debiasing methods mitigate popularity bias often uniformly across all users and only partially consider the time evolution of users or items. However, users have different levels of preference for item popularity, and this preference is evolving over time. To address these issues, we propose a novel method called CausalEPP (Causal Intervention on Evolving Personal Popularity) for taming recommendation bias, which accounts for the evolving personal popularity of users. Specifically, we first introduce a metric called {Evolving Personal Popularity} to quantify each user's preference for popular items. Then, we design a causal graph that integrates evolving personal popularity into the conformity effect, and apply deconfounded training to mitigate the popularity bias of the causal graph. During inference, we consider the evolution consistency between users and items to achieve a better recommendation. Empirical studies demonstrate that CausalEPP outperforms baseline methods in reducing popularity bias while improving recommendation accuracy.
GCoT: Chain-of-Thought Prompt Learning for Graphs
Feb 12, 2025Chain-of-thought (CoT) prompting has achieved remarkable success in natural language processing (NLP). However, its vast potential remains largely unexplored for graphs. This raises an interesting question: How can we design CoT prompting for graphs to guide graph models to learn step by step? On one hand, unlike natural languages, graphs are non-linear and characterized by complex topological structures. On the other hand, many graphs lack textual data, making it difficult to formulate language-based CoT prompting. In this work, we propose the first CoT prompt learning framework for text-free graphs, GCoT. Specifically, we decompose the adaptation process for each downstream task into a series of inference steps, with each step consisting of prompt-based inference, ``thought'' generation, and thought-conditioned prompt learning. While the steps mimic CoT prompting in NLP, the exact mechanism differs significantly. Specifically, at each step, an input graph, along with a prompt, is first fed into a pre-trained graph encoder for prompt-based inference. We then aggregate the hidden layers of the encoder to construct a ``thought'', which captures the working state of each node in the current step. Conditioned on this thought, we learn a prompt specific to each node based on the current state. These prompts are fed into the next inference step, repeating the cycle. To evaluate and analyze the effectiveness of GCoT, we conduct comprehensive experiments on eight public datasets, which demonstrate the advantage of our approach.
SAMGPT: Text-free Graph Foundation Model for Multi-domain Pre-training and Cross-domain Adaptation
Feb 08, 2025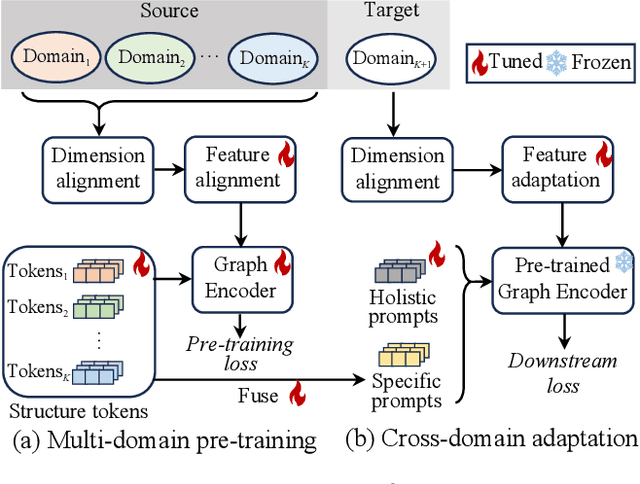
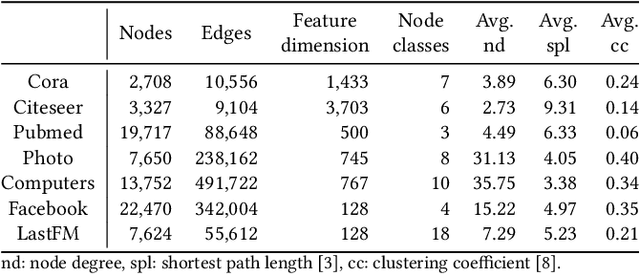
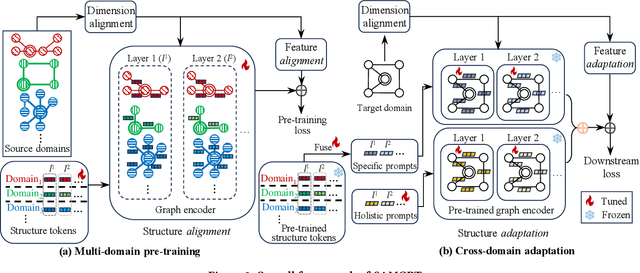
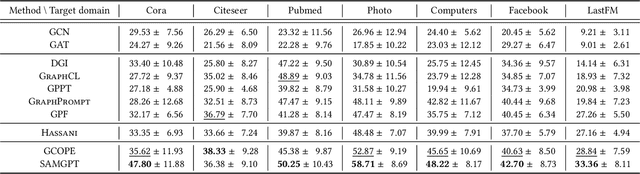
Graphs are able to model interconnected entities in many online services, supporting a wide range of applications on the Web. This raises an important question: How can we train a graph foundational model on multiple source domains and adapt to an unseen target domain? A major obstacle is that graphs from different domains often exhibit divergent characteristics. Some studies leverage large language models to align multiple domains based on textual descriptions associated with the graphs, limiting their applicability to text-attributed graphs. For text-free graphs, a few recent works attempt to align different feature distributions across domains, while generally neglecting structural differences. In this work, we propose a novel Structure Alignment framework for text-free Multi-domain Graph Pre-Training and cross-domain adaptation (SAMGPT). It is designed to learn multi-domain knowledge from graphs originating in multiple source domains, which can then be adapted to address applications in an unseen target domain. Specifically, we introduce a set of structure tokens to harmonize structure-based aggregation across source domains during the pre-training phase. Next, for cross-domain adaptation, we design dual prompts, namely, holistic prompts and specific prompts, which adapt unified multi-domain structural knowledge and fine-grained, domain-specific information, respectively, to a target domain. Finally, we conduct comprehensive experiments on seven public datasets to evaluate and analyze the effectiveness of SAMGPT.
Non-Homophilic Graph Pre-Training and Prompt Learning
Aug 22, 2024



Graphs are ubiquitous for modeling complex relationships between objects across various fields. Graph neural networks (GNNs) have become a mainstream technique for graph-based applications, but their performance heavily relies on abundant labeled data. To reduce labeling requirement, pre-training and prompt learning has become a popular alternative. However, most existing prompt methods do not differentiate homophilic and heterophilic characteristics of real-world graphs. In particular, many real-world graphs are non-homophilic, not strictly or uniformly homophilic with mixing homophilic and heterophilic patterns, exhibiting varying non-homophilic characteristics across graphs and nodes. In this paper, we propose ProNoG, a novel pre-training and prompt learning framework for such non-homophilic graphs. First, we analyze existing graph pre-training methods, providing theoretical insights into the choice of pre-training tasks. Second, recognizing that each node exhibits unique non-homophilic characteristics, we propose a conditional network to characterize the node-specific patterns in downstream tasks. Finally, we thoroughly evaluate and analyze ProNoG through extensive experiments on ten public datasets.
Text-Free Multi-domain Graph Pre-training:Toward Graph Foundation Models
May 22, 2024Given the ubiquity of graph data, it is intriguing to ask: Is it possible to train a graph foundation model on a broad range of graph data across diverse domains? A major hurdle toward this goal lies in the fact that graphs from different domains often exhibit profoundly divergent characteristics. Although there have been some initial efforts in integrating multi-domain graphs for pre-training, they primarily rely on textual descriptions to align the graphs, limiting their application to text-attributed graphs. Moreover, different source domains may conflict or interfere with each other, and their relevance to the target domain can vary significantly. To address these issues, we propose MDGPT, a text free Multi-Domain Graph Pre-Training and adaptation framework designed to exploit multi-domain knowledge for graph learning. First, we propose a set of domain tokens to to align features across source domains for synergistic pre-training. Second, we propose a dual prompts, consisting of a unifying prompt and a mixing prompt, to further adapt the target domain with unified multi-domain knowledge and a tailored mixture of domain-specific knowledge. Finally, we conduct extensive experiments involving six public datasets to evaluate and analyze MDGPT, which outperforms prior art by up to 37.9%.
DyGPrompt: Learning Feature and Time Prompts on Dynamic Graphs
May 22, 2024



Dynamic graphs are pervasive in the real world, modeling dynamic relations between objects across various fields. For dynamic graph modeling, dynamic graph neural networks (DGNNs) have emerged as a mainstream technique, which are generally pre-trained on the link prediction task, leaving a significant gap from the objectives of downstream tasks such as node classification. To bridge the gap, prompt-based learning has gained traction on graphs. However, existing efforts focus on static graphs, neglecting the evolution of dynamic graphs. In this paper, we propose DyGPrompt, a novel pre-training and prompting framework for dynamic graph modeling. First, we design dual prompts to address the gap in both task objectives and dynamic variations across pre-training and downstream tasks. Second, we recognize that node and time features mutually characterize each other, and propose dual condition-nets to model the evolving node-time patterns in downstream tasks. Finally, we thoroughly evaluate and analyze DyGPrompt through extensive experiments on three public datasets.