 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting Channel-Patch Dependencies in Time Series Forecasting with Graph Spectral Decomposition
Mar 14, 2026Time series forecasting has attracted significant attention in the field of AI. Previous works have revealed that the Channel-Independent (CI) strategy improves forecasting performance by modeling each channel individually, but it often suffers from poor generalization and overlooks meaningful inter-channel interactions. Conversely, Channel-Dependent (CD) strategies aggregate all channels, which may introduce irrelevant information and lead to oversmoothing. Despite recent progress, few existing methods offer the flexibility to adaptively balance CI and CD strategies in response to varying channel dependencies. To address this, we propose a generic plugin xCPD, that can adaptively model the channel-patch dependencies from the perspective of graph spectral decomposition. Specifically, xCPD first projects multivariate signals into the frequency domain using a shared graph Fourier basis, and groups patches into low-, mid-, and high-frequency bands based on their spectral energy responses. xCPD then applies a channel-adaptive routing mechanism that dynamically adjusts the degree of inter-channel interaction for each patch, enabling selective activation of frequency-specific experts. This facilitates fine-grained input-aware modeling of smooth trends, local fluctuations, and abrupt transitions. xCPD can be seamlessly integrated on top of existing CI and CD forecasting models, consistently enhancing both accuracy and generalization across benchmarks. The code is available https://github.com/Clearloveyuan/xCPD.
Node Role-Guided LLMs for Dynamic Graph Clustering
Mar 14, 2026Dynamic graph clustering aims to detect and track time-varying clusters in dynamic graphs, revealing how complex real-world systems evolve over time. However, existing methods are predominantly black-box models. They lack interpretability in their clustering decisions and fail to provide semantic explanations of why clusters form or how they evolve, severely limiting their use in safety-critical domains such as healthcare or transportation. To address these limitations, we propose an end-to-end interpretable framework that maps continuous graph embeddings into discrete semantic concepts through learnable prototypes. Specifically, we first decompose node representations into orthogonal role and clustering subspaces, so that nodes with similar roles (e.g., hubs, bridges) but different cluster affiliations can be properly distinguished. We then introduce five node role prototypes (Leader, Contributor, Wanderer, Connector, Newcomer) in the role subspace as semantic anchors, transforming continuous embeddings into discrete concepts to facilitate LLM understanding of node roles within communities. Finally, we design a hierarchical LLM reasoning mechanism to generate both clustering results and natural language explanations, while providing consistency feedback as weak supervision to refine node representations. Experimental results on four synthetic and six real-world benchmarks demonstrate the effectiveness, interpretability, and robustness of DyG-RoLLM. Code is available at https://github.com/Clearloveyuan/DyG-RoLLM.
ELLMob: Event-Driven Human Mobility Generation with Self-Aligned LLM Framework
Mar 09, 2026Human mobility generation aims to synthesize plausible trajectory data, which is widely used in urban system research. While Large Language Model-based methods excel at generating routine trajectories, they struggle to capture deviated mobility during large-scale societal events. This limitation stems from two critical gaps: (1) the absence of event-annotated mobility datasets for design and evaluation, and (2) the inability of current frameworks to reconcile competitions between users' habitual patterns and event-imposed constraints when making trajectory decisions. This work addresses these gaps with a twofold contribution. First, we construct the first event-annotated mobility dataset covering three major events: Typhoon Hagibis, COVID-19, and the Tokyo 2021 Olympics. Second, we propose ELLMob, a self-aligned LLM framework that first extracts competing rationales between habitual patterns and event constraints, based on Fuzzy-Trace Theory, and then iteratively aligns them to generate trajectories that are both habitually grounded and event-responsive. Extensive experiments show that ELLMob wins state-of-the-art baselines across all events, demonstrating its effectiveness. Our codes and datasets are available at https://github.com/deepkashiwa20/ELLMob.
See2Refine: Vision-Language Feedback Improves LLM-Based eHMI Action Designers
Feb 02, 2026Automated vehicles lack natural communication channels with other road users, making external Human-Machine Interfaces (eHMIs) essential for conveying intent and maintaining trust in shared environments. However, most eHMI studies rely on developer-crafted message-action pairs, which are difficult to adapt to diverse and dynamic traffic contexts. A promising alternative is to use Large Language Models (LLMs) as action designers that generate context-conditioned eHMI actions, yet such designers lack perceptual verification and typically depend on fixed prompts or costly human-annotated feedback for improvement. We present See2Refine, a human-free, closed-loop framework that uses vision-language model (VLM) perceptual evaluation as automated visual feedback to improve an LLM-based eHMI action designer. Given a driving context and a candidate eHMI action, the VLM evaluates the perceived appropriateness of the action, and this feedback is used to iteratively revise the designer's outputs, enabling systematic refinement without human supervision. We evaluate our framework across three eHMI modalities (lightbar, eyes, and arm) and multiple LLM model sizes. Across settings, our framework consistently outperforms prompt-only LLM designers and manually specified baselines in both VLM-based metrics and human-subject evaluations. Results further indicate that the improvements generalize across modalities and that VLM evaluations are well aligned with human preferences, supporting the robustness and effectiveness of See2Refine for scalable action design.
A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy
Jun 11, 2025Recent improvements in large language models (LLMs) have led many researchers to focus on building fully autonomous AI agents. This position paper questions whether this approach is the right path forward, as these autonomous systems still have problems with reliability, transparency, and understanding the actual requirements of human. We suggest a different approach: LLM-based Human-Agent Systems (LLM-HAS), where AI works with humans rather than replacing them. By keeping human involved to provide guidance, answer questions, and maintain control, these systems can be more trustworthy and adaptable. Looking at examples from healthcare, finance, and software development, we show how human-AI teamwork can handle complex tasks better than AI working alone. We also discuss the challenges of building these collaborative systems and offer practical solutions. This paper argues that progress in AI should not be measured by how independent systems become, but by how well they can work with humans. The most promising future for AI is not in systems that take over human roles, but in those that enhance human capabilities through meaningful partnership.
Automating eHMI Action Design with LLMs for Automated Vehicle Communication
May 27, 2025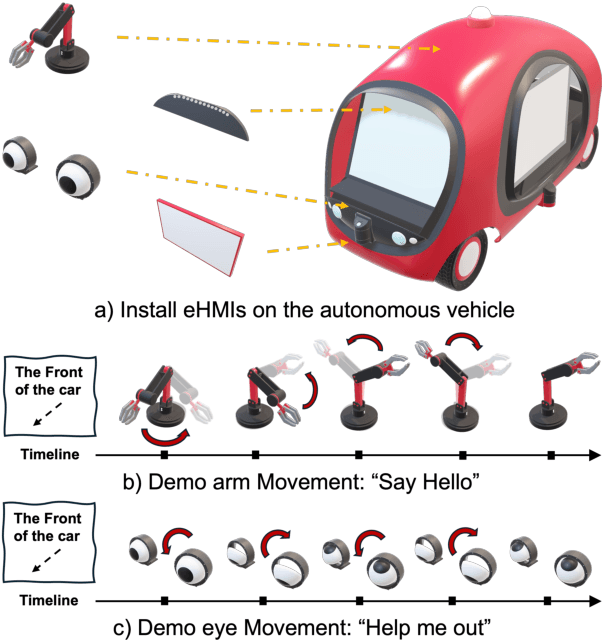
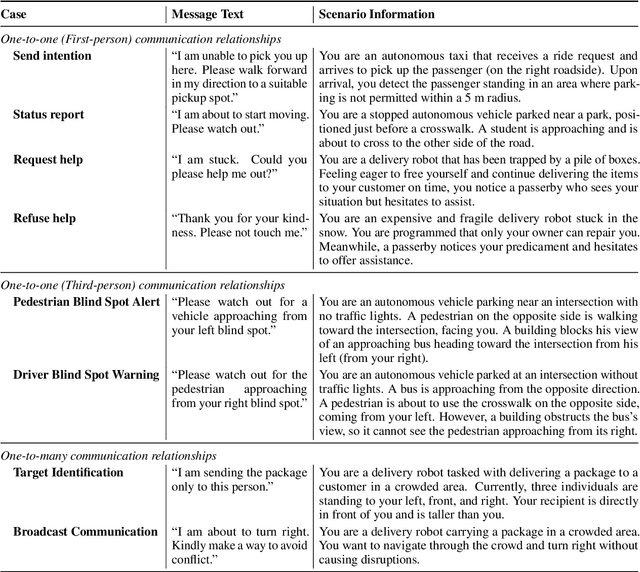
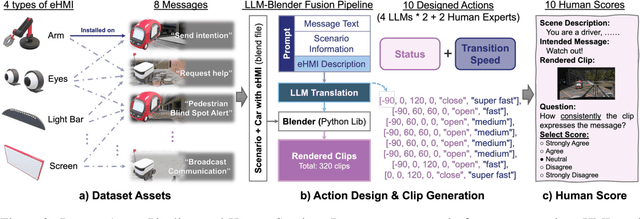

The absence of explicit communication channels between automated vehicles (AVs) and other road users requires the use of external Human-Machine Interfaces (eHMIs) to convey messages effectively in uncertain scenarios. Currently, most eHMI studies employ predefined text messages and manually designed actions to perform these messages, which limits the real-world deployment of eHMIs, where adaptability in dynamic scenarios is essential. Given the generalizability and versatility of large language models (LLMs), they could potentially serve as automated action designers for the message-action design task. To validate this idea, we make three contributions: (1) We propose a pipeline that integrates LLMs and 3D renderers, using LLMs as action designers to generate executable actions for controlling eHMIs and rendering action clips. (2) We collect a user-rated Action-Design Scoring dataset comprising a total of 320 action sequences for eight intended messages and four representative eHMI modalities. The dataset validates that LLMs can translate intended messages into actions close to a human level, particularly for reasoning-enabled LLMs. (3) We introduce two automated raters, Action Reference Score (ARS) and Vision-Language Models (VLMs), to benchmark 18 LLMs, finding that the VLM aligns with human preferences yet varies across eHMI modalities.
Understanding Fact Recall in Language Models: Why Two-Stage Training Encourages Memorization but Mixed Training Teaches Knowledge
May 22, 2025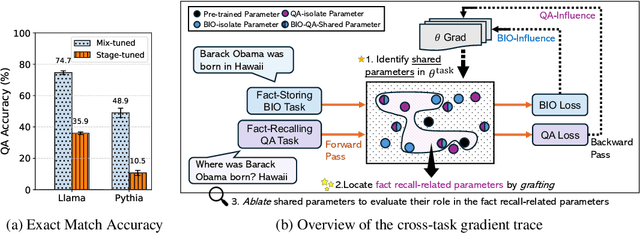
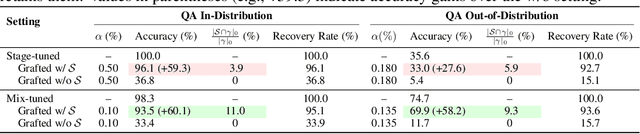
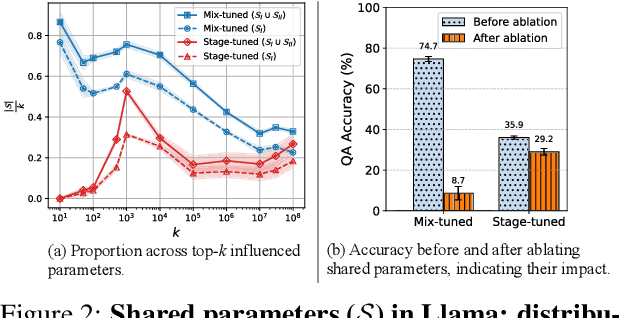
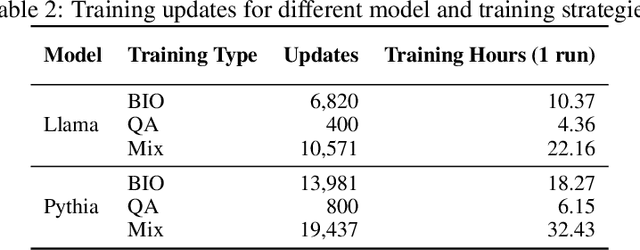
Fact recall, the ability of language models (LMs) to retrieve specific factual knowledge, remains a challenging task despite their impressive general capabilities. Common training strategies often struggle to promote robust recall behavior with two-stage training, which first trains a model with fact-storing examples (e.g., factual statements) and then with fact-recalling examples (question-answer pairs), tending to encourage rote memorization rather than generalizable fact retrieval. In contrast, mixed training, which jointly uses both types of examples, has been empirically shown to improve the ability to recall facts, but the underlying mechanisms are still poorly understood. In this work, we investigate how these training strategies affect how model parameters are shaped during training and how these differences relate to their ability to recall facts. We introduce cross-task gradient trace to identify shared parameters, those strongly influenced by both fact-storing and fact-recalling examples. Our analysis on synthetic fact recall datasets with the Llama-3.2B and Pythia-2.8B models reveals that mixed training encouraging a larger and more centralized set of shared parameters. These findings suggest that the emergence of parameters may play a key role in enabling LMs to generalize factual knowledge across task formulations.
Taming Recommendation Bias with Causal Intervention on Evolving Personal Popularity
May 20, 2025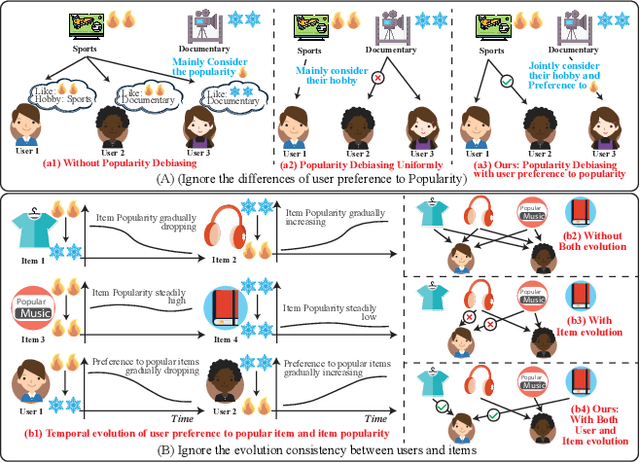
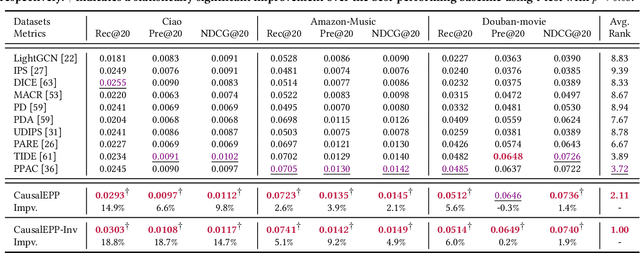

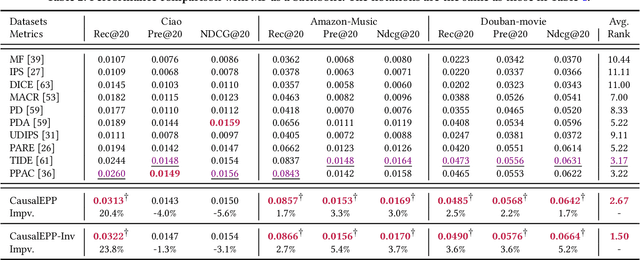
Popularity bias occurs when popular items are recommended far more frequently than they should be, negatively impacting both user experience and recommendation accuracy. Existing debiasing methods mitigate popularity bias often uniformly across all users and only partially consider the time evolution of users or items. However, users have different levels of preference for item popularity, and this preference is evolving over time. To address these issues, we propose a novel method called CausalEPP (Causal Intervention on Evolving Personal Popularity) for taming recommendation bias, which accounts for the evolving personal popularity of users. Specifically, we first introduce a metric called {Evolving Personal Popularity} to quantify each user's preference for popular items. Then, we design a causal graph that integrates evolving personal popularity into the conformity effect, and apply deconfounded training to mitigate the popularity bias of the causal graph. During inference, we consider the evolution consistency between users and items to achieve a better recommendation. Empirical studies demonstrate that CausalEPP outperforms baseline methods in reducing popularity bias while improving recommendation accuracy.
A Survey on Large Language Model based Human-Agent Systems
May 01, 2025Recent advances in large language models (LLMs) have sparked growing interest in building fully autonomous agents. However, fully autonomous LLM-based agents still face significant challenges, including limited reliability due to hallucinations, difficulty in handling complex tasks, and substantial safety and ethical risks, all of which limit their feasibility and trustworthiness in real-world applications. To overcome these limitations, LLM-based human-agent systems (LLM-HAS) incorporate human-provided information, feedback, or control into the agent system to enhance system performance, reliability and safety. This paper provides the first comprehensive and structured survey of LLM-HAS. It clarifies fundamental concepts, systematically presents core components shaping these systems, including environment & profiling, human feedback, interaction types, orchestration and communication, explores emerging applications, and discusses unique challenges and opportunities. By consolidating current knowledge and offering a structured overview, we aim to foster further research and innovation in this rapidly evolving interdisciplinary field. Paper lists and resources are available at https://github.com/HenryPengZou/Awesome-LLM-Based-Human-Agent-System-Papers.
A Unified Retrieval Framework with Document Ranking and EDU Filtering for Multi-document Summarization
Apr 23, 2025In the field of multi-document summarization (MDS), transformer-based models have demonstrated remarkable success, yet they suffer an input length limitation. Current methods apply truncation after the retrieval process to fit the context length; however, they heavily depend on manually well-crafted queries, which are impractical to create for each document set for MDS. Additionally, these methods retrieve information at a coarse granularity, leading to the inclusion of irrelevant content. To address these issues, we propose a novel retrieval-based framework that integrates query selection and document ranking and shortening into a unified process. Our approach identifies the most salient elementary discourse units (EDUs) from input documents and utilizes them as latent queries. These queries guide the document ranking by calculating relevance scores. Instead of traditional truncation, our approach filters out irrelevant EDUs to fit the context length, ensuring that only critical information is preserved for summarization. We evaluate our framework on multiple MDS datasets, demonstrating consistent improvements in ROUGE metrics while confirming its scalability and flexibility across diverse model architectures. Additionally, we validate its effectiveness through an in-depth analysis, emphasizing its ability to dynamically select appropriate queries and accurately rank documents based on their relevance scores. These results demonstrate that our framework effectively addresses context-length constraints, establishing it as a robust and reliable solution for MDS.