 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee2Refine: Vision-Language Feedback Improves LLM-Based eHMI Action Designers
Feb 02, 2026Automated vehicles lack natural communication channels with other road users, making external Human-Machine Interfaces (eHMIs) essential for conveying intent and maintaining trust in shared environments. However, most eHMI studies rely on developer-crafted message-action pairs, which are difficult to adapt to diverse and dynamic traffic contexts. A promising alternative is to use Large Language Models (LLMs) as action designers that generate context-conditioned eHMI actions, yet such designers lack perceptual verification and typically depend on fixed prompts or costly human-annotated feedback for improvement. We present See2Refine, a human-free, closed-loop framework that uses vision-language model (VLM) perceptual evaluation as automated visual feedback to improve an LLM-based eHMI action designer. Given a driving context and a candidate eHMI action, the VLM evaluates the perceived appropriateness of the action, and this feedback is used to iteratively revise the designer's outputs, enabling systematic refinement without human supervision. We evaluate our framework across three eHMI modalities (lightbar, eyes, and arm) and multiple LLM model sizes. Across settings, our framework consistently outperforms prompt-only LLM designers and manually specified baselines in both VLM-based metrics and human-subject evaluations. Results further indicate that the improvements generalize across modalities and that VLM evaluations are well aligned with human preferences, supporting the robustness and effectiveness of See2Refine for scalable action design.
GTA: Generative Traffic Agents for Simulating Realistic Mobility Behavior
Jan 27, 2026People's transportation choices reflect complex trade-offs shaped by personal preferences, social norms, and technology acceptance. Predicting such behavior at scale is a critical challenge with major implications for urban planning and sustainable transport. Traditional methods use handcrafted assumptions and costly data collection, making them impractical for early-stage evaluations of new technologies or policies. We introduce Generative Traffic Agents (GTA) for simulating large-scale, context-sensitive transportation choices using LLM-powered, persona-based agents. GTA generates artificial populations from census-based sociodemographic data. It simulates activity schedules and mode choices, enabling scalable, human-like simulations without handcrafted rules. We evaluate GTA in Berlin-scale experiments, comparing simulation results against empirical data. While agents replicate patterns, such as modal split by socioeconomic status, they show systematic biases in trip length and mode preference. GTA offers new opportunities for modeling how future innovations, from bike lanes to transit apps, shape mobility decisions.
Automating eHMI Action Design with LLMs for Automated Vehicle Communication
May 27, 2025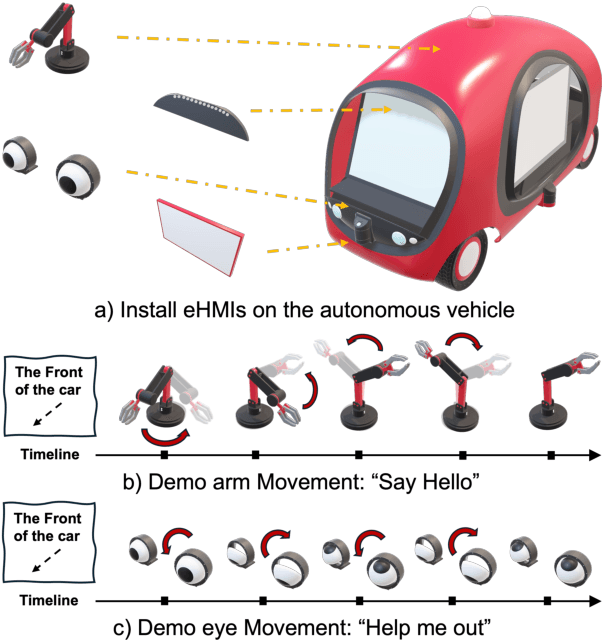
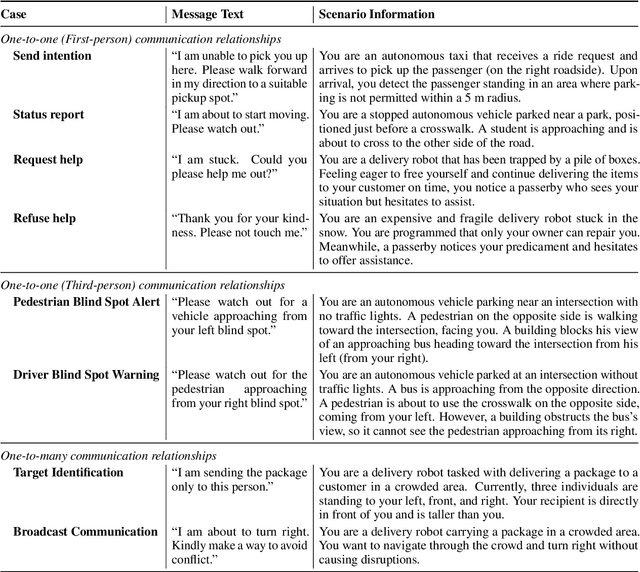
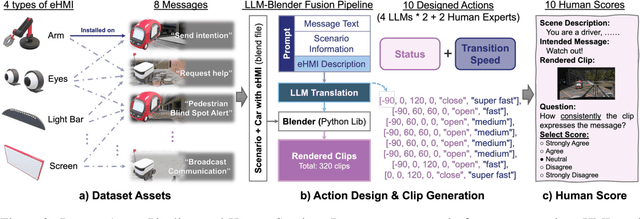

The absence of explicit communication channels between automated vehicles (AVs) and other road users requires the use of external Human-Machine Interfaces (eHMIs) to convey messages effectively in uncertain scenarios. Currently, most eHMI studies employ predefined text messages and manually designed actions to perform these messages, which limits the real-world deployment of eHMIs, where adaptability in dynamic scenarios is essential. Given the generalizability and versatility of large language models (LLMs), they could potentially serve as automated action designers for the message-action design task. To validate this idea, we make three contributions: (1) We propose a pipeline that integrates LLMs and 3D renderers, using LLMs as action designers to generate executable actions for controlling eHMIs and rendering action clips. (2) We collect a user-rated Action-Design Scoring dataset comprising a total of 320 action sequences for eight intended messages and four representative eHMI modalities. The dataset validates that LLMs can translate intended messages into actions close to a human level, particularly for reasoning-enabled LLMs. (3) We introduce two automated raters, Action Reference Score (ARS) and Vision-Language Models (VLMs), to benchmark 18 LLMs, finding that the VLM aligns with human preferences yet varies across eHMI modalities.
Introducing ROADS: A Systematic Comparison of Remote Control Interaction Concepts for Automated Vehicles at Road Works
Feb 18, 2025
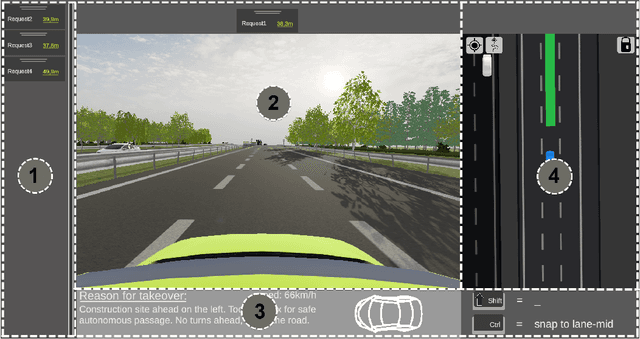
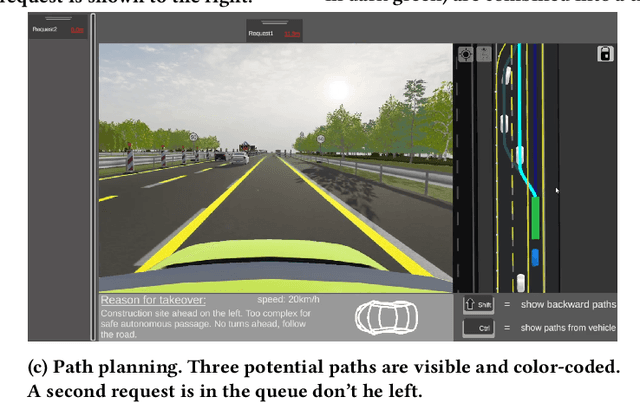
As vehicle automation technology continues to mature, there is a necessity for robust remote monitoring and intervention features. These are essential for intervening during vehicle malfunctions, challenging road conditions, or in areas that are difficult to navigate. This evolution in the role of the human operator - from a constant driver to an intermittent teleoperator - necessitates the development of suitable interaction interfaces. While some interfaces were suggested, a comparative study is missing. We designed, implemented, and evaluated three interaction concepts (path planning, trajectory guidance, and waypoint guidance) with up to four concurrent requests of automated vehicles in a within-subjects study with N=23 participants. The results showed a clear preference for the path planning concept. It also led to the highest usability but lower satisfaction. With trajectory guidance, the fewest requests were resolved. The study's findings contribute to the ongoing development of HMIs focused on the remote assistance of automated vehicles.
Field Notes on Deploying Research Robots in Public Spaces
Apr 29, 2024Human-robot interaction requires to be studied in the wild. In the summers of 2022 and 2023, we deployed two trash barrel service robots through the wizard-of-oz protocol in public spaces to study human-robot interactions in urban settings. We deployed the robots at two different public plazas in downtown Manhattan and Brooklyn for a collective of 20 hours of field time. To date, relatively few long-term human-robot interaction studies have been conducted in shared public spaces. To support researchers aiming to fill this gap, we would like to share some of our insights and learned lessons that would benefit both researchers and practitioners on how to deploy robots in public spaces. We share best practices and lessons learned with the HRI research community to encourage more in-the-wild research of robots in public spaces and call for the community to share their lessons learned to a GitHub repository.