 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee2Refine: Vision-Language Feedback Improves LLM-Based eHMI Action Designers
Feb 02, 2026Automated vehicles lack natural communication channels with other road users, making external Human-Machine Interfaces (eHMIs) essential for conveying intent and maintaining trust in shared environments. However, most eHMI studies rely on developer-crafted message-action pairs, which are difficult to adapt to diverse and dynamic traffic contexts. A promising alternative is to use Large Language Models (LLMs) as action designers that generate context-conditioned eHMI actions, yet such designers lack perceptual verification and typically depend on fixed prompts or costly human-annotated feedback for improvement. We present See2Refine, a human-free, closed-loop framework that uses vision-language model (VLM) perceptual evaluation as automated visual feedback to improve an LLM-based eHMI action designer. Given a driving context and a candidate eHMI action, the VLM evaluates the perceived appropriateness of the action, and this feedback is used to iteratively revise the designer's outputs, enabling systematic refinement without human supervision. We evaluate our framework across three eHMI modalities (lightbar, eyes, and arm) and multiple LLM model sizes. Across settings, our framework consistently outperforms prompt-only LLM designers and manually specified baselines in both VLM-based metrics and human-subject evaluations. Results further indicate that the improvements generalize across modalities and that VLM evaluations are well aligned with human preferences, supporting the robustness and effectiveness of See2Refine for scalable action design.
Med-CoReasoner: Reducing Language Disparities in Medical Reasoning via Language-Informed Co-Reasoning
Jan 13, 2026While reasoning-enhanced large language models perform strongly on English medical tasks, a persistent multilingual gap remains, with substantially weaker reasoning in local languages, limiting equitable global medical deployment. To bridge this gap, we introduce Med-CoReasoner, a language-informed co-reasoning framework that elicits parallel English and local-language reasoning, abstracts them into structured concepts, and integrates local clinical knowledge into an English logical scaffold via concept-level alignment and retrieval. This design combines the structural robustness of English reasoning with the practice-grounded expertise encoded in local languages. To evaluate multilingual medical reasoning beyond multiple-choice settings, we construct MultiMed-X, a benchmark covering seven languages with expert-annotated long-form question answering and natural language inference tasks, comprising 350 instances per language. Experiments across three benchmarks show that Med-CoReasoner improves multilingual reasoning performance by an average of 5%, with particularly substantial gains in low-resource languages. Moreover, model distillation and expert evaluation analysis further confirm that Med-CoReasoner produces clinically sound and culturally grounded reasoning traces.
Tibetan Language and AI: A Comprehensive Survey of Resources, Methods and Challenges
Oct 22, 2025Tibetan, one of the major low-resource languages in Asia, presents unique linguistic and sociocultural characteristics that pose both challenges and opportunities for AI research. Despite increasing interest in developing AI systems for underrepresented languages, Tibetan has received limited attention due to a lack of accessible data resources, standardized benchmarks, and dedicated tools. This paper provides a comprehensive survey of the current state of Tibetan AI in the AI domain, covering textual and speech data resources, NLP tasks, machine translation, speech recognition, and recent developments in LLMs. We systematically categorize existing datasets and tools, evaluate methods used across different tasks, and compare performance where possible. We also identify persistent bottlenecks such as data sparsity, orthographic variation, and the lack of unified evaluation metrics. Additionally, we discuss the potential of cross-lingual transfer, multi-modal learning, and community-driven resource creation. This survey aims to serve as a foundational reference for future work on Tibetan AI research and encourages collaborative efforts to build an inclusive and sustainable AI ecosystem for low-resource languages.
Automating eHMI Action Design with LLMs for Automated Vehicle Communication
May 27, 2025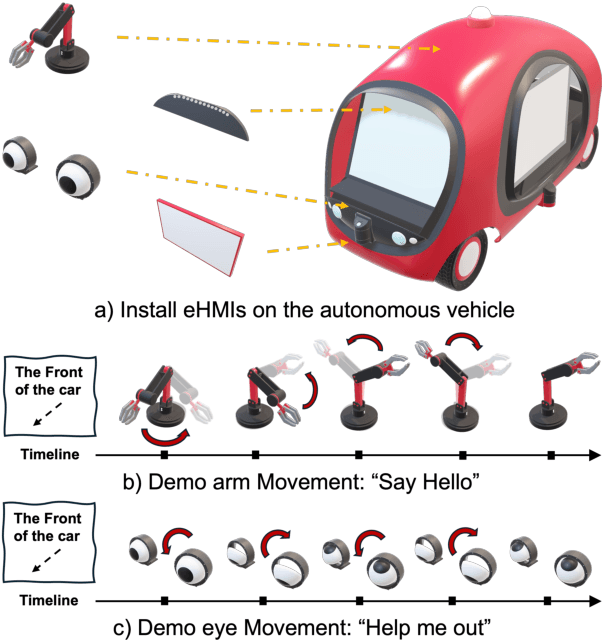
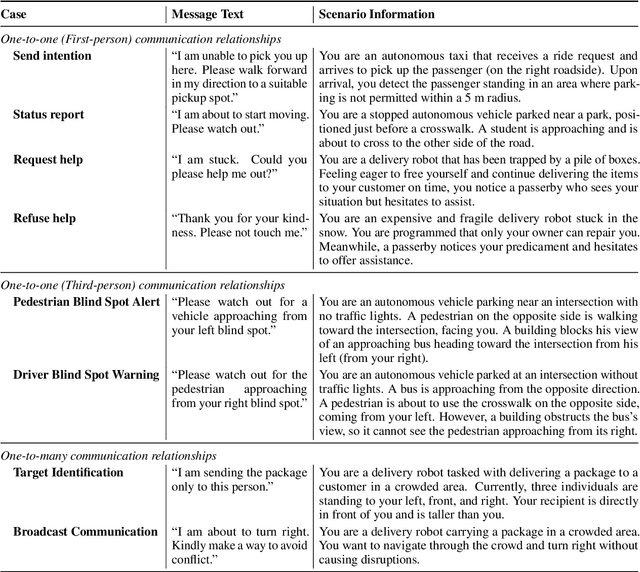
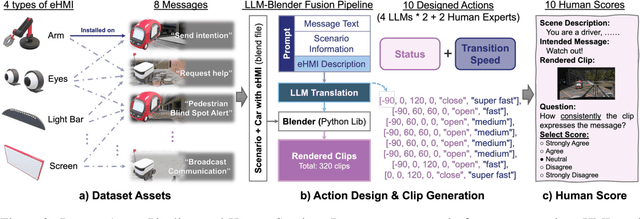

The absence of explicit communication channels between automated vehicles (AVs) and other road users requires the use of external Human-Machine Interfaces (eHMIs) to convey messages effectively in uncertain scenarios. Currently, most eHMI studies employ predefined text messages and manually designed actions to perform these messages, which limits the real-world deployment of eHMIs, where adaptability in dynamic scenarios is essential. Given the generalizability and versatility of large language models (LLMs), they could potentially serve as automated action designers for the message-action design task. To validate this idea, we make three contributions: (1) We propose a pipeline that integrates LLMs and 3D renderers, using LLMs as action designers to generate executable actions for controlling eHMIs and rendering action clips. (2) We collect a user-rated Action-Design Scoring dataset comprising a total of 320 action sequences for eight intended messages and four representative eHMI modalities. The dataset validates that LLMs can translate intended messages into actions close to a human level, particularly for reasoning-enabled LLMs. (3) We introduce two automated raters, Action Reference Score (ARS) and Vision-Language Models (VLMs), to benchmark 18 LLMs, finding that the VLM aligns with human preferences yet varies across eHMI modalities.
RetrieveAll: A Multilingual Named Entity Recognition Framework with Large Language Models
May 25, 2025The rise of large language models has led to significant performance breakthroughs in named entity recognition (NER) for high-resource languages, yet there remains substantial room for improvement in low- and medium-resource languages. Existing multilingual NER methods face severe language interference during the multi-language adaptation process, manifested in feature conflicts between different languages and the competitive suppression of low-resource language features by high-resource languages. Although training a dedicated model for each language can mitigate such interference, it lacks scalability and incurs excessive computational costs in real-world applications. To address this issue, we propose RetrieveAll, a universal multilingual NER framework based on dynamic LoRA. The framework decouples task-specific features across languages and demonstrates efficient dynamic adaptability. Furthermore, we introduce a cross-granularity knowledge augmented method that fully exploits the intrinsic potential of the data without relying on external resources. By leveraging a hierarchical prompting mechanism to guide knowledge injection, this approach advances the paradigm from "prompt-guided inference" to "prompt-driven learning." Experimental results show that RetrieveAll outperforms existing baselines; on the PAN-X dataset, it achieves an average F1 improvement of 12.1 percent.
FMSD-TTS: Few-shot Multi-Speaker Multi-Dialect Text-to-Speech Synthesis for Ü-Tsang, Amdo and Kham Speech Dataset Generation
May 20, 2025



Tibetan is a low-resource language with minimal parallel speech corpora spanning its three major dialects-\"U-Tsang, Amdo, and Kham-limiting progress in speech modeling. To address this issue, we propose FMSD-TTS, a few-shot, multi-speaker, multi-dialect text-to-speech framework that synthesizes parallel dialectal speech from limited reference audio and explicit dialect labels. Our method features a novel speaker-dialect fusion module and a Dialect-Specialized Dynamic Routing Network (DSDR-Net) to capture fine-grained acoustic and linguistic variations across dialects while preserving speaker identity. Extensive objective and subjective evaluations demonstrate that FMSD-TTS significantly outperforms baselines in both dialectal expressiveness and speaker similarity. We further validate the quality and utility of the synthesized speech through a challenging speech-to-speech dialect conversion task. Our contributions include: (1) a novel few-shot TTS system tailored for Tibetan multi-dialect speech synthesis, (2) the public release of a large-scale synthetic Tibetan speech corpus generated by FMSD-TTS, and (3) an open-source evaluation toolkit for standardized assessment of speaker similarity, dialect consistency, and audio quality.
TiSpell: A Semi-Masked Methodology for Tibetan Spelling Correction covering Multi-Level Error with Data Augmentation
May 14, 2025Multi-level Tibetan spelling correction addresses errors at both the character and syllable levels within a unified model. Existing methods focus mainly on single-level correction and lack effective integration of both levels. Moreover, there are no open-source datasets or augmentation methods tailored for this task in Tibetan. To tackle this, we propose a data augmentation approach using unlabeled text to generate multi-level corruptions, and introduce TiSpell, a semi-masked model capable of correcting both character- and syllable-level errors. Although syllable-level correction is more challenging due to its reliance on global context, our semi-masked strategy simplifies this process. We synthesize nine types of corruptions on clean sentences to create a robust training set. Experiments on both simulated and real-world data demonstrate that TiSpell, trained on our dataset, outperforms baseline models and matches the performance of state-of-the-art approaches, confirming its effectiveness.
HealthGenie: Empowering Users with Healthy Dietary Guidance through Knowledge Graph and Large Language Models
Apr 20, 2025Seeking dietary guidance often requires navigating complex professional knowledge while accommodating individual health conditions. Knowledge Graphs (KGs) offer structured and interpretable nutritional information, whereas Large Language Models (LLMs) naturally facilitate conversational recommendation delivery. In this paper, we present HealthGenie, an interactive system that combines the strengths of LLMs and KGs to provide personalized dietary recommendations along with hierarchical information visualization for a quick and intuitive overview. Upon receiving a user query, HealthGenie performs query refinement and retrieves relevant information from a pre-built KG. The system then visualizes and highlights pertinent information, organized by defined categories, while offering detailed, explainable recommendation rationales. Users can further tailor these recommendations by adjusting preferences interactively. Our evaluation, comprising a within-subject comparative experiment and an open-ended discussion, demonstrates that HealthGenie effectively supports users in obtaining personalized dietary guidance based on their health conditions while reducing interaction effort and cognitive load. These findings highlight the potential of LLM-KG integration in supporting decision-making through explainable and visualized information. We examine the system's usefulness and effectiveness with an N=12 within-subject study and provide design considerations for future systems that integrate conversational LLM and KG.
TLUE: A Tibetan Language Understanding Evaluation Benchmark
Mar 15, 2025

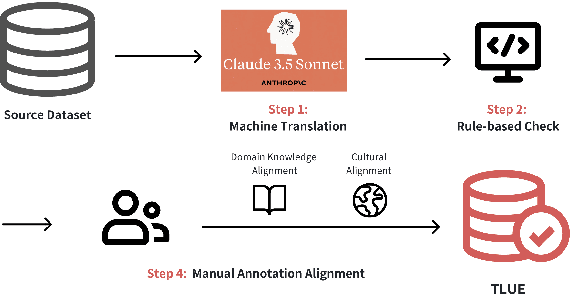

Large language models (LLMs) have made tremendous progress in recent years, but low-resource languages, such as Tibetan, remain significantly underrepresented in their evaluation. Despite Tibetan being spoken by over seven million people, it has largely been neglected in the development and assessment of LLMs. To address this gap, we present TLUE (A Tibetan Language Understanding Evaluation Benchmark), the first large-scale benchmark for assessing LLMs' capabilities in Tibetan. TLUE comprises two major components: (1) a comprehensive multi-task understanding benchmark spanning 5 domains and 67 subdomains, and (2) a safety benchmark covering 7 subdomains. We evaluate a diverse set of state-of-the-art LLMs. Experimental results demonstrate that most LLMs perform below the random baseline, highlighting the considerable challenges LLMs face in processing Tibetan, a low-resource language. TLUE provides an essential foundation for driving future research and progress in Tibetan language understanding and underscores the need for greater inclusivity in LLM development.
ReAgent: Reversible Multi-Agent Reasoning for Knowledge-Enhanced Multi-Hop QA
Mar 10, 2025



Recent advances in large language models (LLMs) have significantly improved multi-hop question answering (QA) through direct Chain-of-Thought (CoT) reasoning. However, the irreversible nature of CoT leads to error accumulation, making it challenging to correct mistakes in multi-hop reasoning. This paper introduces ReAgent: a Reversible multi-Agent collaborative framework augmented with explicit backtracking mechanisms, enabling reversible multi-hop reasoning. By incorporating text-based retrieval, information aggregation and validation, our system can detect and correct errors mid-reasoning, leading to more robust and interpretable QA outcomes. The framework and experiments serve as a foundation for future work on error-tolerant QA systems. Empirical evaluations across three benchmarks indicate ReAgent's efficacy, yielding average about 6\% improvements against baseline models.