 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthGenie: Empowering Users with Healthy Dietary Guidance through Knowledge Graph and Large Language Models
Apr 20, 2025Seeking dietary guidance often requires navigating complex professional knowledge while accommodating individual health conditions. Knowledge Graphs (KGs) offer structured and interpretable nutritional information, whereas Large Language Models (LLMs) naturally facilitate conversational recommendation delivery. In this paper, we present HealthGenie, an interactive system that combines the strengths of LLMs and KGs to provide personalized dietary recommendations along with hierarchical information visualization for a quick and intuitive overview. Upon receiving a user query, HealthGenie performs query refinement and retrieves relevant information from a pre-built KG. The system then visualizes and highlights pertinent information, organized by defined categories, while offering detailed, explainable recommendation rationales. Users can further tailor these recommendations by adjusting preferences interactively. Our evaluation, comprising a within-subject comparative experiment and an open-ended discussion, demonstrates that HealthGenie effectively supports users in obtaining personalized dietary guidance based on their health conditions while reducing interaction effort and cognitive load. These findings highlight the potential of LLM-KG integration in supporting decision-making through explainable and visualized information. We examine the system's usefulness and effectiveness with an N=12 within-subject study and provide design considerations for future systems that integrate conversational LLM and KG.
Automatic Detection of Research Values from Scientific Abstracts Across Computer Science Subfields
Feb 26, 2025The field of Computer science (CS) has rapidly evolved over the past few decades, providing computational tools and methodologies to various fields and forming new interdisciplinary communities. This growth in CS has significantly impacted institutional practices and relevant research communities. Therefore, it is crucial to explore what specific research values, known as basic and fundamental beliefs that guide or motivate research attitudes or actions, CS-related research communities promote. Prior research has manually analyzed research values from a small sample of machine learning papers. No prior work has studied the automatic detection of research values in CS from large-scale scientific texts across different research subfields. This paper introduces a detailed annotation scheme featuring ten research values that guide CS-related research. Based on the scheme, we build value classifiers to scale up the analysis and present a systematic study over 226,600 paper abstracts from 32 CS-related subfields and 86 popular publishing venues over ten years.
AudienceView: AI-Assisted Interpretation of Audience Feedback in Journalism
Jul 17, 2024

Understanding and making use of audience feedback is important but difficult for journalists, who now face an impractically large volume of audience comments online. We introduce AudienceView, an online tool to help journalists categorize and interpret this feedback by leveraging large language models (LLMs). AudienceView identifies themes and topics, connects them back to specific comments, provides ways to visualize the sentiment and distribution of the comments, and helps users develop ideas for subsequent reporting projects. We consider how such tools can be useful in a journalist's workflow, and emphasize the importance of contextual awareness and human judgment.
Bridging Dictionary: AI-Generated Dictionary of Partisan Language Use
Jul 12, 2024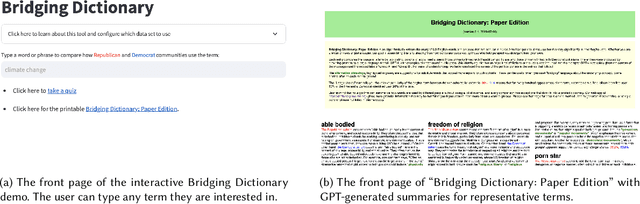

Words often carry different meanings for people from diverse backgrounds. Today's era of social polarization demands that we choose words carefully to prevent miscommunication, especially in political communication and journalism. To address this issue, we introduce the Bridging Dictionary, an interactive tool designed to illuminate how words are perceived by people with different political views. The Bridging Dictionary includes a static, printable document featuring 796 terms with summaries generated by a large language model. These summaries highlight how the terms are used distinctively by Republicans and Democrats. Additionally, the Bridging Dictionary offers an interactive interface that lets users explore selected words, visualizing their frequency, sentiment, summaries, and examples across political divides. We present a use case for journalists and emphasize the importance of human agency and trust in further enhancing this tool. The deployed version of Bridging Dictionary is available at https://dictionary.ccc-mit.org/.
Leveraging Large Language Models for Learning Complex Legal Concepts through Storytelling
Feb 26, 2024



Making legal knowledge accessible to non-experts is crucial for enhancing general legal literacy and encouraging civic participation in democracy. However, legal documents are often challenging to understand for people without legal backgrounds. In this paper, we present a novel application of large language models (LLMs) in legal education to help non-experts learn intricate legal concepts through storytelling, an effective pedagogical tool in conveying complex and abstract concepts. We also introduce a new dataset LegalStories, which consists of 295 complex legal doctrines, each accompanied by a story and a set of multiple-choice questions generated by LLMs. To construct the dataset, we experiment with various LLMs to generate legal stories explaining these concepts. Furthermore, we use an expert-in-the-loop method to iteratively design multiple-choice questions. Then, we evaluate the effectiveness of storytelling with LLMs through an RCT experiment with legal novices on 10 samples from the dataset. We find that LLM-generated stories enhance comprehension of legal concepts and interest in law among non-native speakers compared to only definitions. Moreover, stories consistently help participants relate legal concepts to their lives. Finally, we find that learning with stories shows a higher retention rate for non-native speakers in the follow-up assessment. Our work has strong implications for using LLMs in promoting teaching and learning in the legal field and beyond.
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Sep 06, 2023Large Language Models (LLMs) have achieved significant success across various natural language processing (NLP) tasks, encompassing question-answering, summarization, and machine translation, among others. While LLMs excel in general tasks, their efficacy in domain-specific applications remains under exploration. Additionally, LLM-generated text sometimes exhibits issues like hallucination and disinformation. In this study, we assess LLMs' capability of producing concise survey articles within the computer science-NLP domain, focusing on 20 chosen topics. Automated evaluations indicate that GPT-4 outperforms GPT-3.5 when benchmarked against the ground truth. Furthermore, four human evaluators provide insights from six perspectives across four model configurations. Through case studies, we demonstrate that while GPT often yields commendable results, there are instances of shortcomings, such as incomplete information and the exhibition of lapses in factual accuracy.
ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings
May 23, 2023We propose ConGraT(Contrastive Graph-Text pretraining), a general, self-supervised method for jointly learning separate representations of texts and nodes in a parent (or ``supervening'') graph, where each text is associated with one of the nodes. Datasets fitting this paradigm are common, from social media (users and posts), to citation networks over articles, to link graphs over web pages. We expand on prior work by providing a general, self-supervised, joint pretraining method, one which does not depend on particular dataset structure or a specific task. Our method uses two separate encoders for graph nodes and texts, which are trained to align their representations within a common latent space. Training uses a batch-wise contrastive learning objective inspired by prior work on joint text and image encoding. As graphs are more structured objects than images, we also extend the training objective to incorporate information about node similarity and plausible next guesses in matching nodes and texts. Experiments on various datasets reveal that ConGraT outperforms strong baselines on various downstream tasks, including node and text category classification and link prediction. Code and certain datasets are available at https://github.com/wwbrannon/congrat.
PersonaLLM: Investigating the Ability of GPT-3.5 to Express Personality Traits and Gender Differences
May 04, 2023



Despite the many use cases for large language models (LLMs) in the design of chatbots in various industries and the research showing the importance of personalizing chatbots to cater to different personality traits, little work has been done to evaluate whether the behaviors of personalized LLMs can reflect certain personality traits accurately and consistently. We consider studying the behavior of LLM-based simulated agents which refer to as LLM personas and present a case study with GPT-3.5 (text-davinci-003) to investigate whether LLMs can generate content with consistent, personalized traits when assigned Big Five personality types and gender roles. We created 320 LLM personas (5 females and 5 males for each of the 32 Big Five personality types) and prompted them to complete the classic 44-item Big Five Inventory (BFI) and then write an 800-word story about their childhood. Results showed that LLM personas' self-reported BFI scores are consistent with their assigned personality types, with large effect sizes found on all five traits. Moreover, significant correlations were found between assigned personality types and some Linguistic Inquiry and Word Count (LIWC) psycholinguistic features of their writings. For instance, extroversion is associated with pro-social and active words, and neuroticism is associated with words related to negative emotions and mental health. Besides, we only found significant differences in using technological and cultural words in writing between LLM-generated female and male personas. This work provides a first step for further research on personalized LLMs and their applications in Human-AI conversation.
PCB-RandNet: Rethinking Random Sampling for LIDAR Semantic Segmentation in Autonomous Driving Scene
Sep 28, 2022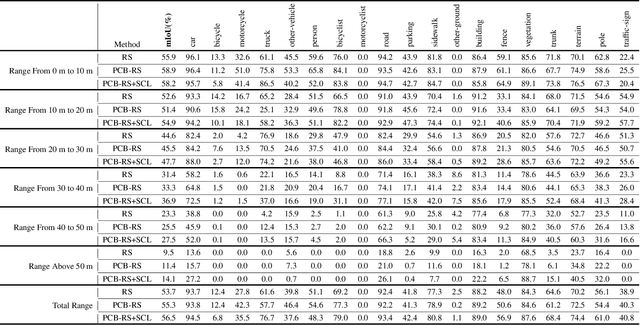
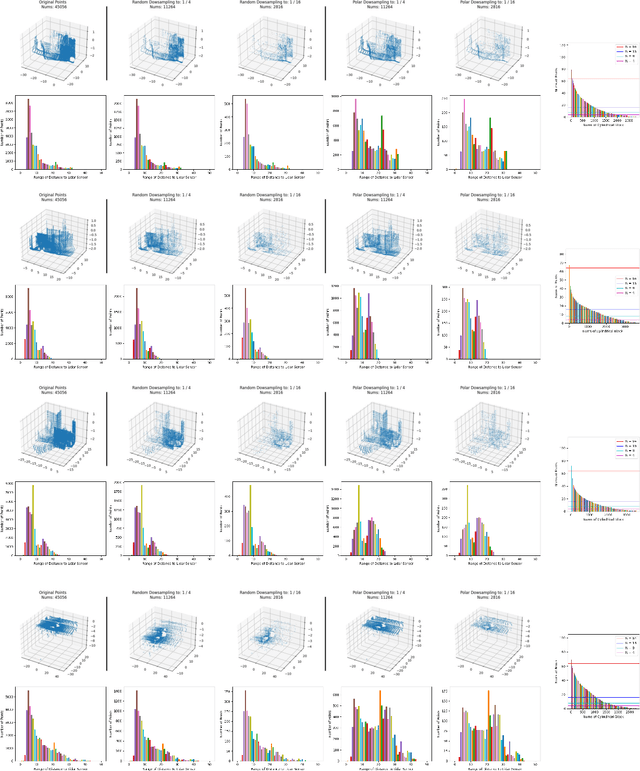
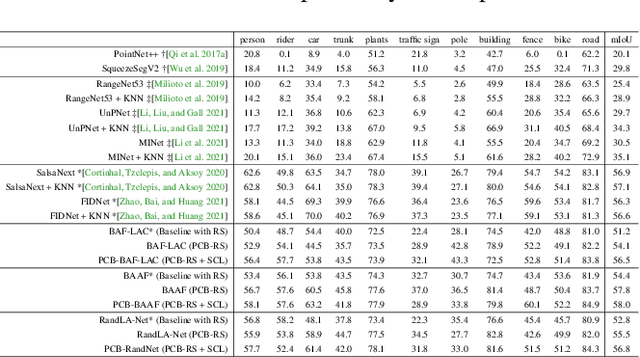
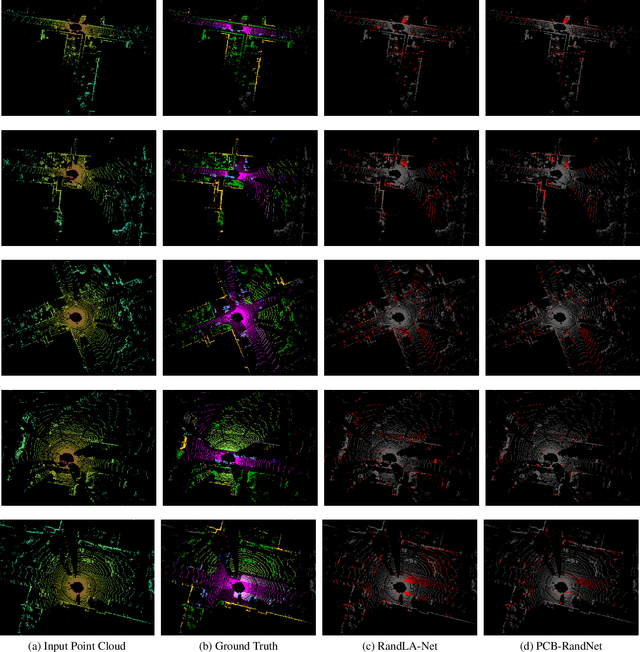
Fast and efficient semantic segmentation of large-scale LiDAR point clouds is a fundamental problem in autonomous driving. To achieve this goal, the existing point-based methods mainly choose to adopt Random Sampling strategy to process large-scale point clouds. However, our quantative and qualitative studies have found that Random Sampling may be less suitable for the autonomous driving scenario, since the LiDAR points follow an uneven or even long-tailed distribution across the space, which prevents the model from capturing sufficient information from points in different distance ranges and reduces the model's learning capability. To alleviate this problem, we propose a new Polar Cylinder Balanced Random Sampling method that enables the downsampled point clouds to maintain a more balanced distribution and improve the segmentation performance under different spatial distributions. In addition, a sampling consistency loss is introduced to further improve the segmentation performance and reduce the model's variance under different sampling methods. Extensive experiments confirm that our approach produces excellent performance on both SemanticKITTI and SemanticPOSS benchmarks, achieving a 2.8% and 4.0% improvement, respectively.
CommunityLM: Probing Partisan Worldviews from Language Models
Sep 15, 2022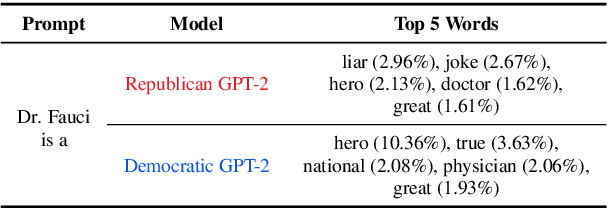
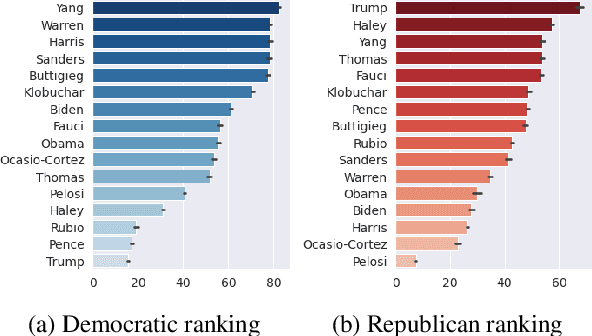
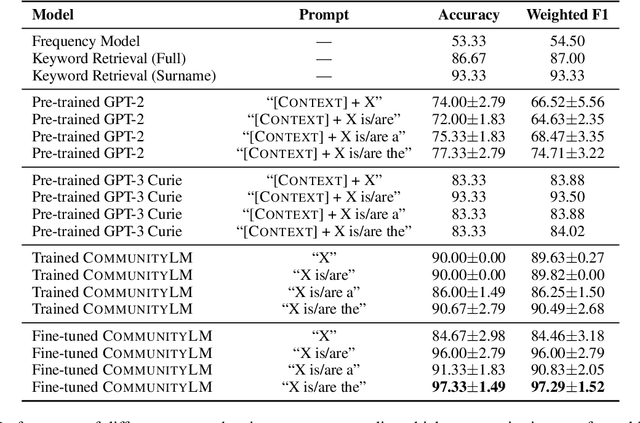
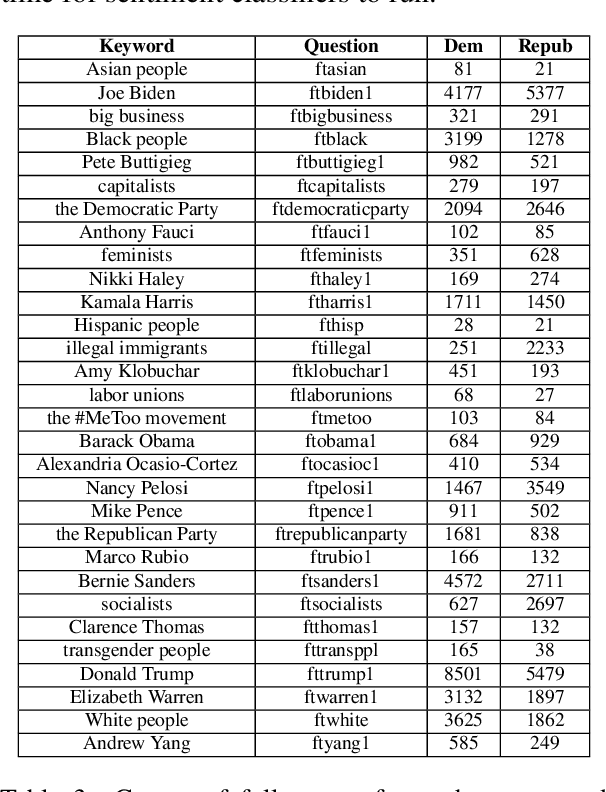
As political attitudes have diverged ideologically in the United States, political speech has diverged lingusitically. The ever-widening polarization between the US political parties is accelerated by an erosion of mutual understanding between them. We aim to make these communities more comprehensible to each other with a framework that probes community-specific responses to the same survey questions using community language models CommunityLM. In our framework we identify committed partisan members for each community on Twitter and fine-tune LMs on the tweets authored by them. We then assess the worldviews of the two groups using prompt-based probing of their corresponding LMs, with prompts that elicit opinions about public figures and groups surveyed by the American National Election Studies (ANES) 2020 Exploratory Testing Survey. We compare the responses generated by the LMs to the ANES survey results, and find a level of alignment that greatly exceeds several baseline methods. Our work aims to show that we can use community LMs to query the worldview of any group of people given a sufficiently large sample of their social media discussions or media diet.