 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudienceView: AI-Assisted Interpretation of Audience Feedback in Journalism
Jul 17, 2024

Understanding and making use of audience feedback is important but difficult for journalists, who now face an impractically large volume of audience comments online. We introduce AudienceView, an online tool to help journalists categorize and interpret this feedback by leveraging large language models (LLMs). AudienceView identifies themes and topics, connects them back to specific comments, provides ways to visualize the sentiment and distribution of the comments, and helps users develop ideas for subsequent reporting projects. We consider how such tools can be useful in a journalist's workflow, and emphasize the importance of contextual awareness and human judgment.
Bridging Dictionary: AI-Generated Dictionary of Partisan Language Use
Jul 12, 2024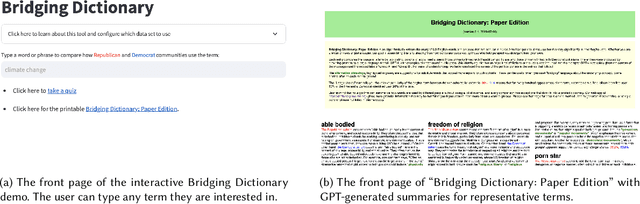

Words often carry different meanings for people from diverse backgrounds. Today's era of social polarization demands that we choose words carefully to prevent miscommunication, especially in political communication and journalism. To address this issue, we introduce the Bridging Dictionary, an interactive tool designed to illuminate how words are perceived by people with different political views. The Bridging Dictionary includes a static, printable document featuring 796 terms with summaries generated by a large language model. These summaries highlight how the terms are used distinctively by Republicans and Democrats. Additionally, the Bridging Dictionary offers an interactive interface that lets users explore selected words, visualizing their frequency, sentiment, summaries, and examples across political divides. We present a use case for journalists and emphasize the importance of human agency and trust in further enhancing this tool. The deployed version of Bridging Dictionary is available at https://dictionary.ccc-mit.org/.
FeedbackMap: a tool for making sense of open-ended survey responses
Jun 26, 2023

Analyzing open-ended survey responses is a crucial yet challenging task for social scientists, non-profit organizations, and educational institutions, as they often face the trade-off between obtaining rich data and the burden of reading and coding textual responses. This demo introduces FeedbackMap, a web-based tool that uses natural language processing techniques to facilitate the analysis of open-ended survey responses. FeedbackMap lets researchers generate summaries at multiple levels, identify interesting response examples, and visualize the response space through embeddings. We discuss the importance of examining survey results from multiple perspectives and the potential biases introduced by summarization methods, emphasizing the need for critical evaluation of the representation and omission of respondent voices.
Redrawing attendance boundaries to promote racial and ethnic diversity in elementary schools
Mar 14, 2023



Most US school districts draw "attendance boundaries" to define catchment areas that assign students to schools near their homes, often recapitulating neighborhood demographic segregation in schools. Focusing on elementary schools, we ask: how much might we reduce school segregation by redrawing attendance boundaries? Combining parent preference data with methods from combinatorial optimization, we simulate alternative boundaries for 98 US school districts serving over 3 million elementary-aged students, minimizing White/non-White segregation while mitigating changes to travel times and school sizes. Across districts, we observe a median 14% relative decrease in segregation, which we estimate would require approximately 20\% of students to switch schools and, surprisingly, a slight reduction in travel times. We release a public dashboard depicting these alternative boundaries (https://www.schooldiversity.org/) and invite both school boards and their constituents to evaluate their viability. Our results show the possibility of greater integration without significant disruptions for families.
CommunityLM: Probing Partisan Worldviews from Language Models
Sep 15, 2022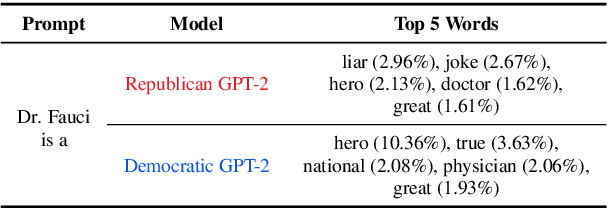
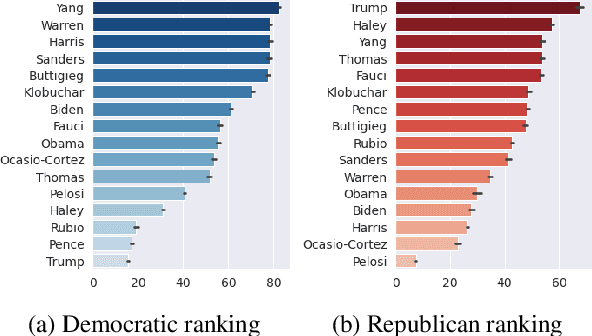
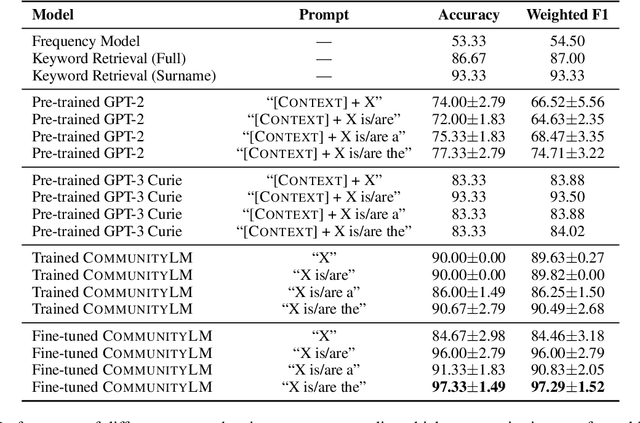
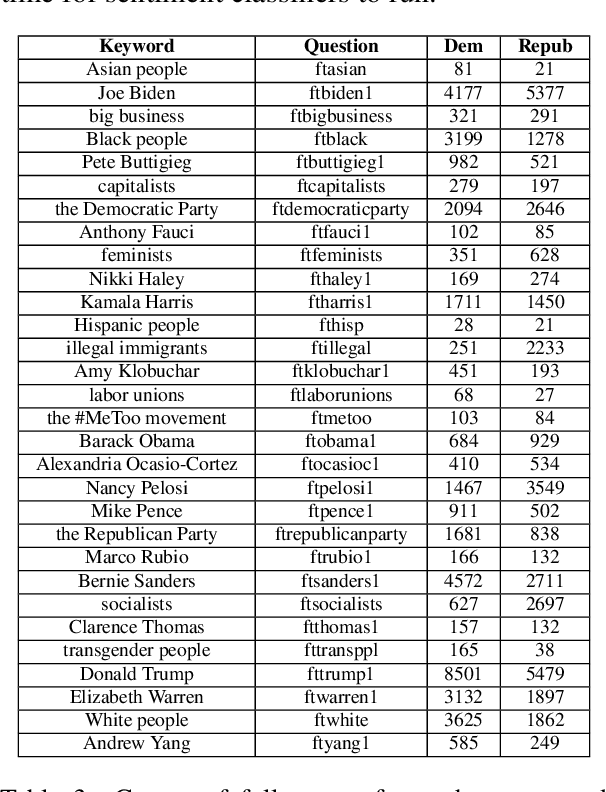
As political attitudes have diverged ideologically in the United States, political speech has diverged lingusitically. The ever-widening polarization between the US political parties is accelerated by an erosion of mutual understanding between them. We aim to make these communities more comprehensible to each other with a framework that probes community-specific responses to the same survey questions using community language models CommunityLM. In our framework we identify committed partisan members for each community on Twitter and fine-tune LMs on the tweets authored by them. We then assess the worldviews of the two groups using prompt-based probing of their corresponding LMs, with prompts that elicit opinions about public figures and groups surveyed by the American National Election Studies (ANES) 2020 Exploratory Testing Survey. We compare the responses generated by the LMs to the ANES survey results, and find a level of alignment that greatly exceeds several baseline methods. Our work aims to show that we can use community LMs to query the worldview of any group of people given a sufficiently large sample of their social media discussions or media diet.
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
Jan 18, 2022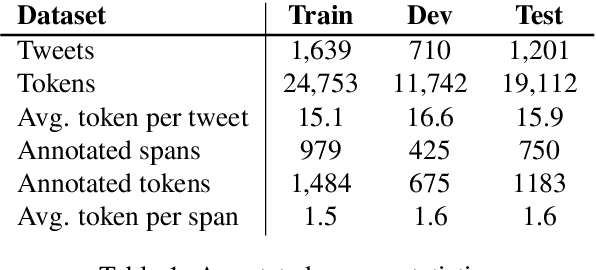
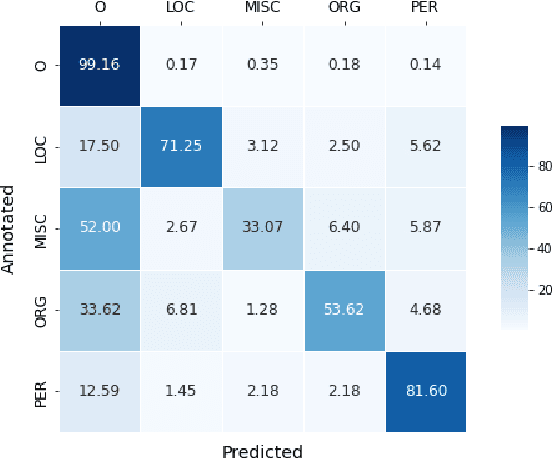
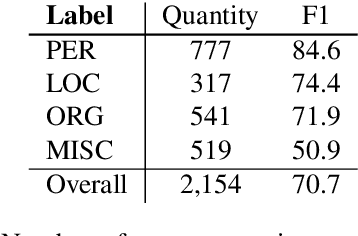

Social media data such as Twitter messages ("tweets") pose a particular challenge to NLP systems because of their short, noisy, and colloquial nature. Tasks such as Named Entity Recognition (NER) and syntactic parsing require highly domain-matched training data for good performance. While there are some publicly available annotated datasets of tweets, they are all purpose-built for solving one task at a time. As yet there is no complete training corpus for both syntactic analysis (e.g., part of speech tagging, dependency parsing) and NER of tweets. In this study, we aim to create Tweebank-NER, an NER corpus based on Tweebank V2 (TB2), and we use these datasets to train state-of-the-art NLP models. We first annotate named entities in TB2 using Amazon Mechanical Turk and measure the quality of our annotations. We train a Stanza NER model on the new benchmark, achieving competitive performance against other non-transformer NER systems. Finally, we train other Twitter NLP models (a tokenizer, lemmatizer, part of speech tagger, and dependency parser) on TB2 based on Stanza, and achieve state-of-the-art or competitive performance on these tasks. We release the dataset and make the models available to use in an "off-the-shelf" manner for future Tweet NLP research. Our source code, data, and pre-trained models are available at: \url{https://github.com/social-machines/TweebankNLP}.
Topic Detection and Tracking with Time-Aware Document Embeddings
Dec 12, 2021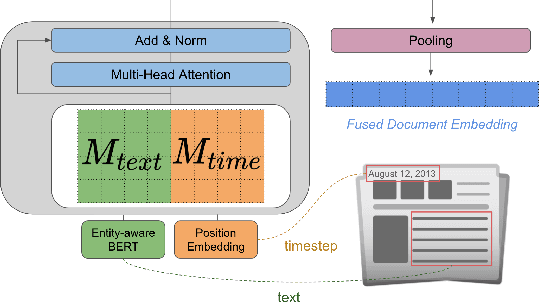

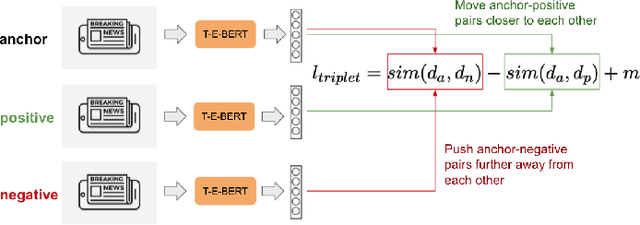
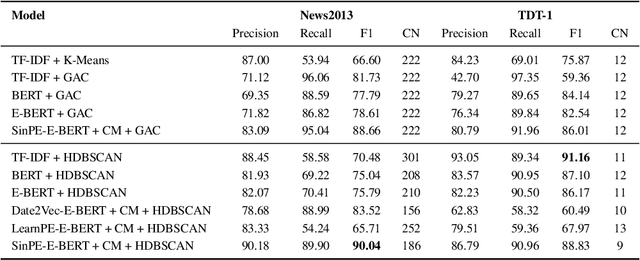
The time at which a message is communicated is a vital piece of metadata in many real-world natural language processing tasks such as Topic Detection and Tracking (TDT). TDT systems aim to cluster a corpus of news articles by event, and in that context, stories that describe the same event are likely to have been written at around the same time. Prior work on time modeling for TDT takes this into account, but does not well capture how time interacts with the semantic nature of the event. For example, stories about a tropical storm are likely to be written within a short time interval, while stories about a movie release may appear over weeks or months. In our work, we design a neural method that fuses temporal and textual information into a single representation of news documents for event detection. We fine-tune these time-aware document embeddings with a triplet loss architecture, integrate the model into downstream TDT systems, and evaluate the systems on two benchmark TDT data sets in English. In the retrospective setting, we apply clustering algorithms to the time-aware embeddings and show substantial improvements over baselines on the News2013 data set. In the online streaming setting, we add our document encoder to an existing state-of-the-art TDT pipeline and demonstrate that it can benefit the overall performance. We conduct ablation studies on the time representation and fusion algorithm strategies, showing that our proposed model outperforms alternative strategies. Finally, we probe the model to examine how it handles recurring events more effectively than previous TDT systems.
Topic-time Heatmaps for Human-in-the-loop Topic Detection and Tracking
Oct 12, 2021
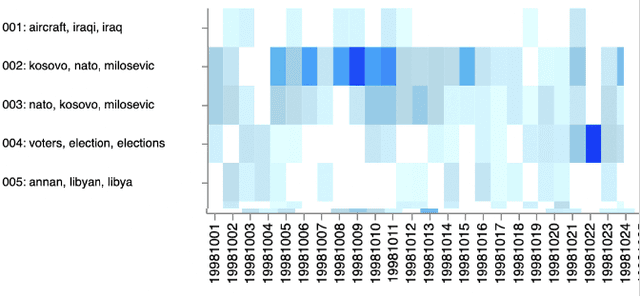
The essential task of Topic Detection and Tracking (TDT) is to organize a collection of news media into clusters of stories that pertain to the same real-world event. To apply TDT models to practical applications such as search engines and discovery tools, human guidance is needed to pin down the scope of an "event" for the corpus of interest. In this work in progress, we explore a human-in-the-loop method that helps users iteratively fine-tune TDT algorithms so that both the algorithms and the users themselves better understand the nature of the events. We generate a visual overview of the entire corpus, allowing the user to select regions of interest from the overview, and then ask a series of questions to affirm (or reject) that the selected documents belong to the same event. The answers to these questions supplement the training data for the event similarity model that underlies the system.
RadioTalk: a large-scale corpus of talk radio transcripts
Jul 16, 2019
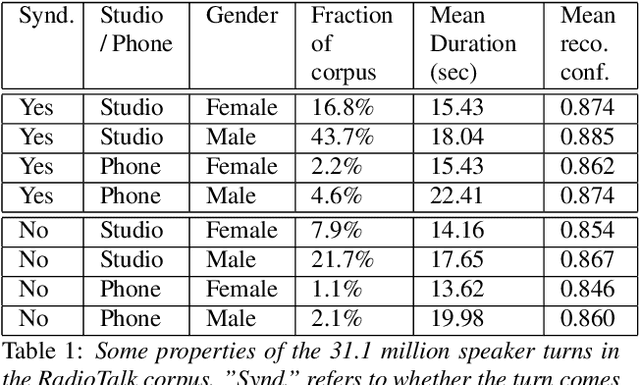
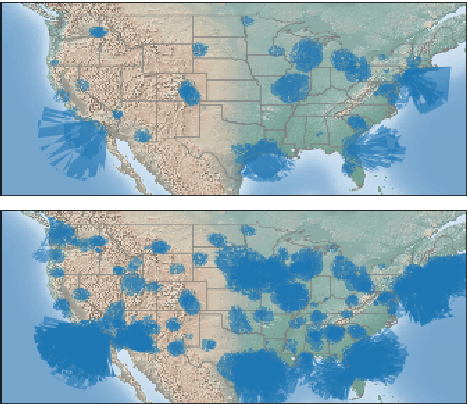
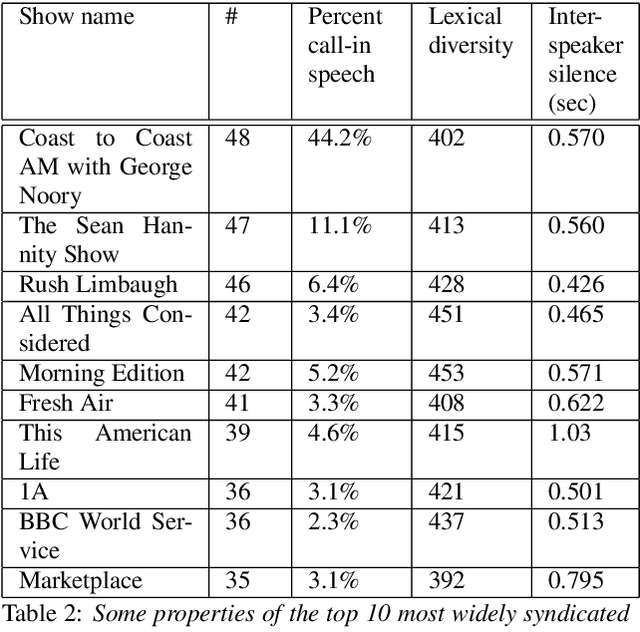
We introduce RadioTalk, a corpus of speech recognition transcripts sampled from talk radio broadcasts in the United States between October of 2018 and March of 2019. The corpus is intended for use by researchers in the fields of natural language processing, conversational analysis, and the social sciences. The corpus encompasses approximately 2.8 billion words of automatically transcribed speech from 284,000 hours of radio, together with metadata about the speech, such as geographical location, speaker turn boundaries, gender, and radio program information. In this paper we summarize why and how we prepared the corpus, give some descriptive statistics on stations, shows and speakers, and carry out a few high-level analyses.
A Model of Lexical Attraction and Repulsion
Jun 16, 1997
This paper introduces new methods based on exponential families for modeling the correlations between words in text and speech. While previous work assumed the effects of word co-occurrence statistics to be constant over a window of several hundred words, we show that their influence is nonstationary on a much smaller time scale. Empirical data drawn from English and Japanese text, as well as conversational speech, reveals that the ``attraction'' between words decays exponentially, while stylistic and syntactic contraints create a ``repulsion'' between words that discourages close co-occurrence. We show that these characteristics are well described by simple mixture models based on two-stage exponential distributions which can be trained using the EM algorithm. The resulting distance distributions can then be incorporated as penalizing features in an exponential language model.