Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadioTalk: a large-scale corpus of talk radio transcripts
Paper and Code

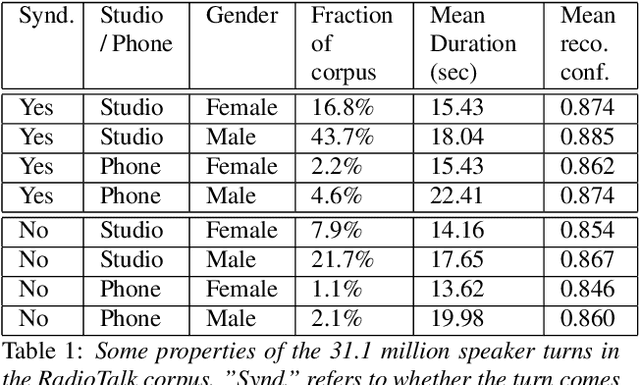
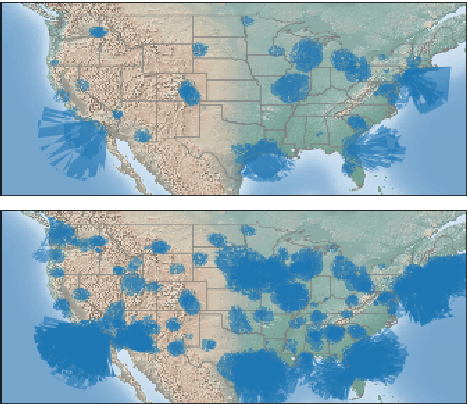
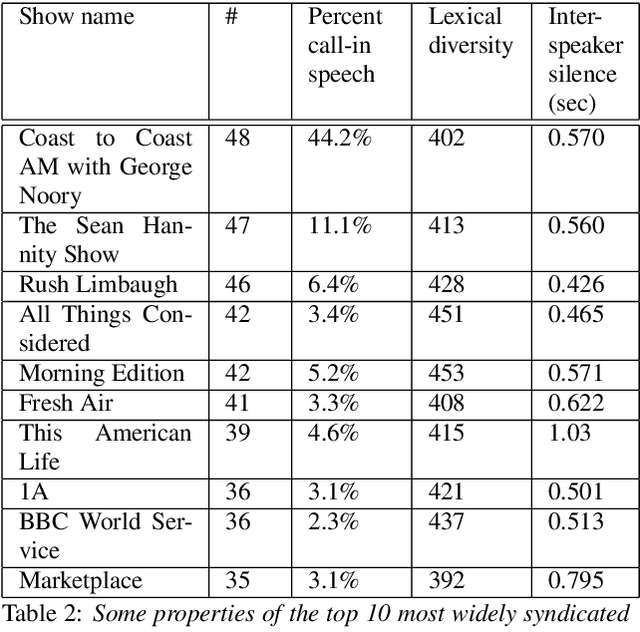
We introduce RadioTalk, a corpus of speech recognition transcripts sampled from talk radio broadcasts in the United States between October of 2018 and March of 2019. The corpus is intended for use by researchers in the fields of natural language processing, conversational analysis, and the social sciences. The corpus encompasses approximately 2.8 billion words of automatically transcribed speech from 284,000 hours of radio, together with metadata about the speech, such as geographical location, speaker turn boundaries, gender, and radio program information. In this paper we summarize why and how we prepared the corpus, give some descriptive statistics on stations, shows and speakers, and carry out a few high-level analyses.
* 5 pages, 4 figures, accepted by Interspeech 2019
View paper on