 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and Collective Decisions: Strengthening Legitimacy and Losers' Consent
Apr 07, 2026AI is increasingly used to scale collective decision-making, but far less attention has been paid to how such systems can support procedural legitimacy, particularly the conditions shaping losers' consent: whether participants who do not get their preferred outcome still accept it as fair. We ask: (1) how can AI help ground collective decisions in participants' different experiences and beliefs, and (2) whether exposure to these experiences can increase trust, understanding, and social cohesion even when people disagree with the outcome. We built a system that uses a semi-structured AI interviewer to elicit personal experiences on policy topics and an interactive visualization that displays predicted policy support alongside those voiced experiences. In a randomized experiment (n = 181), interacting with the visualization increased perceived legitimacy, trust in outcomes, and understanding of others' perspectives, even though all participants encountered decisions that went against their stated preferences. Our hope is that the design and evaluation of this tool spurs future researchers to focus on how AI can help not only achieve scale and efficiency in democratic processes, but also increase trust and connection between participants.
Applying Large Language Models to Characterize Public Narratives
Nov 17, 2025
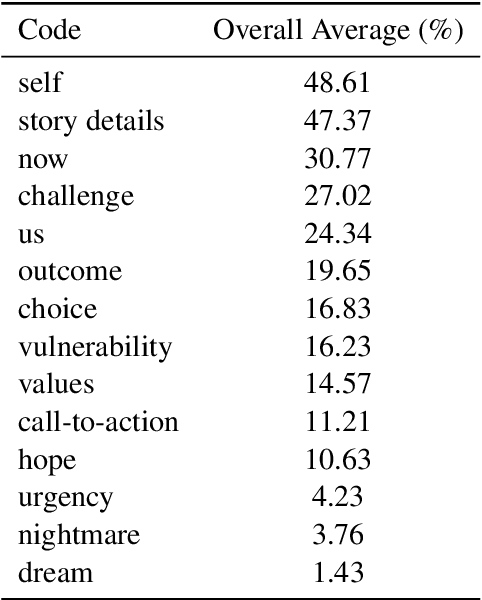

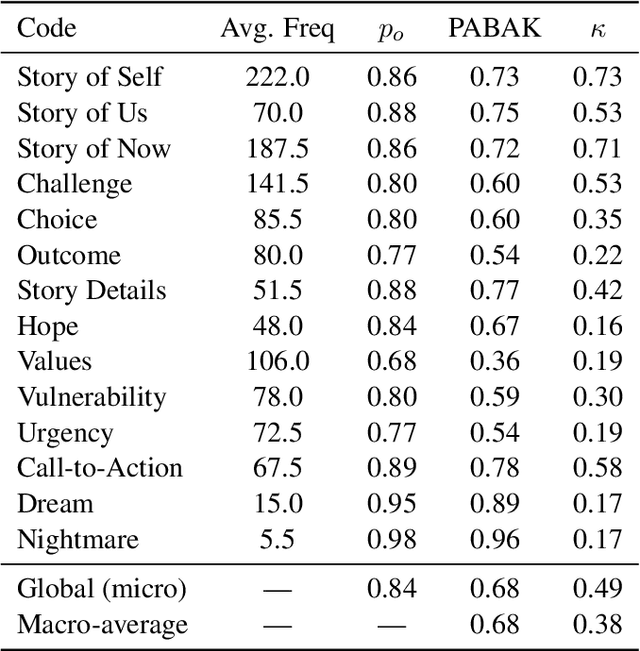
Public Narratives (PNs) are key tools for leadership development and civic mobilization, yet their systematic analysis remains challenging due to their subjective interpretation and the high cost of expert annotation. In this work, we propose a novel computational framework that leverages large language models (LLMs) to automate the qualitative annotation of public narratives. Using a codebook we co-developed with subject-matter experts, we evaluate LLM performance against that of expert annotators. Our work reveals that LLMs can achieve near-human-expert performance, achieving an average F1 score of 0.80 across 8 narratives and 14 codes. We then extend our analysis to empirically explore how PN framework elements manifest across a larger dataset of 22 stories. Lastly, we extrapolate our analysis to a set of political speeches, establishing a novel lens in which to analyze political rhetoric in civic spaces. This study demonstrates the potential of LLM-assisted annotation for scalable narrative analysis and highlights key limitations and directions for future research in computational civic storytelling.
The Empty Chair: Using LLMs to Raise Missing Perspectives in Policy Deliberations
Mar 18, 2025Deliberation is essential to well-functioning democracies, yet physical, economic, and social barriers often exclude certain groups, reducing representativeness and contributing to issues like group polarization. In this work, we explore the use of large language model (LLM) personas to introduce missing perspectives in policy deliberations. We develop and evaluate a tool that transcribes conversations in real-time and simulates input from relevant but absent stakeholders. We deploy this tool in a 19-person student citizens' assembly on campus sustainability. Participants and facilitators found that the tool sparked new discussions and surfaced valuable perspectives they had not previously considered. However, they also noted that AI-generated responses were sometimes overly general. They raised concerns about overreliance on AI for perspective-taking. Our findings highlight both the promise and potential risks of using LLMs to raise missing points of view in group deliberation settings.
Bridging Context Gaps: Enhancing Comprehension in Long-Form Social Conversations Through Contextualized Excerpts
Dec 28, 2024We focus on enhancing comprehension in small-group recorded conversations, which serve as a medium to bring people together and provide a space for sharing personal stories and experiences on crucial social matters. One way to parse and convey information from these conversations is by sharing highlighted excerpts in subsequent conversations. This can help promote a collective understanding of relevant issues, by highlighting perspectives and experiences to other groups of people who might otherwise be unfamiliar with and thus unable to relate to these experiences. The primary challenge that arises then is that excerpts taken from one conversation and shared in another setting might be missing crucial context or key elements that were previously introduced in the original conversation. This problem is exacerbated when conversations become lengthier and richer in themes and shared experiences. To address this, we explore how Large Language Models (LLMs) can enrich these excerpts by providing socially relevant context. We present approaches for effective contextualization to improve comprehension, readability, and empathy. We show significant improvements in understanding, as assessed through subjective and objective evaluations. While LLMs can offer valuable context, they struggle with capturing key social aspects. We release the Human-annotated Salient Excerpts (HSE) dataset to support future work. Additionally, we show how context-enriched excerpts can provide more focused and comprehensive conversation summaries.
On the Relationship between Truth and Political Bias in Language Models
Sep 09, 2024



Language model alignment research often attempts to ensure that models are not only helpful and harmless, but also truthful and unbiased. However, optimizing these objectives simultaneously can obscure how improving one aspect might impact the others. In this work, we focus on analyzing the relationship between two concepts essential in both language model alignment and political science: \textit{truthfulness} and \textit{political bias}. We train reward models on various popular truthfulness datasets and subsequently evaluate their political bias. Our findings reveal that optimizing reward models for truthfulness on these datasets tends to result in a left-leaning political bias. We also find that existing open-source reward models (i.e. those trained on standard human preference datasets) already show a similar bias and that the bias is larger for larger models. These results raise important questions about both the datasets used to represent truthfulness and what language models capture about the relationship between truth and politics.
AudienceView: AI-Assisted Interpretation of Audience Feedback in Journalism
Jul 17, 2024

Understanding and making use of audience feedback is important but difficult for journalists, who now face an impractically large volume of audience comments online. We introduce AudienceView, an online tool to help journalists categorize and interpret this feedback by leveraging large language models (LLMs). AudienceView identifies themes and topics, connects them back to specific comments, provides ways to visualize the sentiment and distribution of the comments, and helps users develop ideas for subsequent reporting projects. We consider how such tools can be useful in a journalist's workflow, and emphasize the importance of contextual awareness and human judgment.
Bridging Dictionary: AI-Generated Dictionary of Partisan Language Use
Jul 12, 2024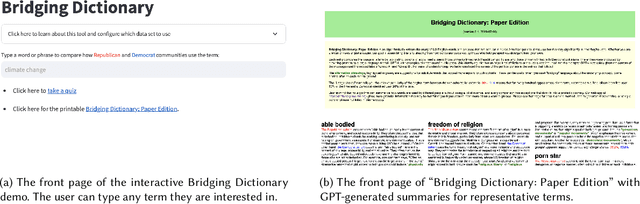

Words often carry different meanings for people from diverse backgrounds. Today's era of social polarization demands that we choose words carefully to prevent miscommunication, especially in political communication and journalism. To address this issue, we introduce the Bridging Dictionary, an interactive tool designed to illuminate how words are perceived by people with different political views. The Bridging Dictionary includes a static, printable document featuring 796 terms with summaries generated by a large language model. These summaries highlight how the terms are used distinctively by Republicans and Democrats. Additionally, the Bridging Dictionary offers an interactive interface that lets users explore selected words, visualizing their frequency, sentiment, summaries, and examples across political divides. We present a use case for journalists and emphasize the importance of human agency and trust in further enhancing this tool. The deployed version of Bridging Dictionary is available at https://dictionary.ccc-mit.org/.
LLM Targeted Underperformance Disproportionately Impacts Vulnerable Users
Jun 25, 2024While state-of-the-art Large Language Models (LLMs) have shown impressive performance on many tasks, there has been extensive research on undesirable model behavior such as hallucinations and bias. In this work, we investigate how the quality of LLM responses changes in terms of information accuracy, truthfulness, and refusals depending on three user traits: English proficiency, education level, and country of origin. We present extensive experimentation on three state-of-the-art LLMs and two different datasets targeting truthfulness and factuality. Our findings suggest that undesirable behaviors in state-of-the-art LLMs occur disproportionately more for users with lower English proficiency, of lower education status, and originating from outside the US, rendering these models unreliable sources of information towards their most vulnerable users.
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Jun 10, 2024In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
Leveraging Large Language Models for Learning Complex Legal Concepts through Storytelling
Feb 26, 2024



Making legal knowledge accessible to non-experts is crucial for enhancing general legal literacy and encouraging civic participation in democracy. However, legal documents are often challenging to understand for people without legal backgrounds. In this paper, we present a novel application of large language models (LLMs) in legal education to help non-experts learn intricate legal concepts through storytelling, an effective pedagogical tool in conveying complex and abstract concepts. We also introduce a new dataset LegalStories, which consists of 295 complex legal doctrines, each accompanied by a story and a set of multiple-choice questions generated by LLMs. To construct the dataset, we experiment with various LLMs to generate legal stories explaining these concepts. Furthermore, we use an expert-in-the-loop method to iteratively design multiple-choice questions. Then, we evaluate the effectiveness of storytelling with LLMs through an RCT experiment with legal novices on 10 samples from the dataset. We find that LLM-generated stories enhance comprehension of legal concepts and interest in law among non-native speakers compared to only definitions. Moreover, stories consistently help participants relate legal concepts to their lives. Finally, we find that learning with stories shows a higher retention rate for non-native speakers in the follow-up assessment. Our work has strong implications for using LLMs in promoting teaching and learning in the legal field and beyond.