 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Learning Complex Legal Concepts through Storytelling
Feb 26, 2024



Making legal knowledge accessible to non-experts is crucial for enhancing general legal literacy and encouraging civic participation in democracy. However, legal documents are often challenging to understand for people without legal backgrounds. In this paper, we present a novel application of large language models (LLMs) in legal education to help non-experts learn intricate legal concepts through storytelling, an effective pedagogical tool in conveying complex and abstract concepts. We also introduce a new dataset LegalStories, which consists of 295 complex legal doctrines, each accompanied by a story and a set of multiple-choice questions generated by LLMs. To construct the dataset, we experiment with various LLMs to generate legal stories explaining these concepts. Furthermore, we use an expert-in-the-loop method to iteratively design multiple-choice questions. Then, we evaluate the effectiveness of storytelling with LLMs through an RCT experiment with legal novices on 10 samples from the dataset. We find that LLM-generated stories enhance comprehension of legal concepts and interest in law among non-native speakers compared to only definitions. Moreover, stories consistently help participants relate legal concepts to their lives. Finally, we find that learning with stories shows a higher retention rate for non-native speakers in the follow-up assessment. Our work has strong implications for using LLMs in promoting teaching and learning in the legal field and beyond.
PersonaLLM: Investigating the Ability of GPT-3.5 to Express Personality Traits and Gender Differences
May 04, 2023



Despite the many use cases for large language models (LLMs) in the design of chatbots in various industries and the research showing the importance of personalizing chatbots to cater to different personality traits, little work has been done to evaluate whether the behaviors of personalized LLMs can reflect certain personality traits accurately and consistently. We consider studying the behavior of LLM-based simulated agents which refer to as LLM personas and present a case study with GPT-3.5 (text-davinci-003) to investigate whether LLMs can generate content with consistent, personalized traits when assigned Big Five personality types and gender roles. We created 320 LLM personas (5 females and 5 males for each of the 32 Big Five personality types) and prompted them to complete the classic 44-item Big Five Inventory (BFI) and then write an 800-word story about their childhood. Results showed that LLM personas' self-reported BFI scores are consistent with their assigned personality types, with large effect sizes found on all five traits. Moreover, significant correlations were found between assigned personality types and some Linguistic Inquiry and Word Count (LIWC) psycholinguistic features of their writings. For instance, extroversion is associated with pro-social and active words, and neuroticism is associated with words related to negative emotions and mental health. Besides, we only found significant differences in using technological and cultural words in writing between LLM-generated female and male personas. This work provides a first step for further research on personalized LLMs and their applications in Human-AI conversation.
Representing Affect Information in Word Embeddings
Sep 21, 2022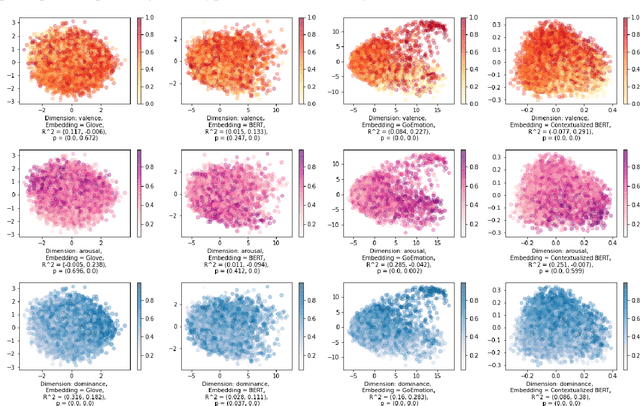
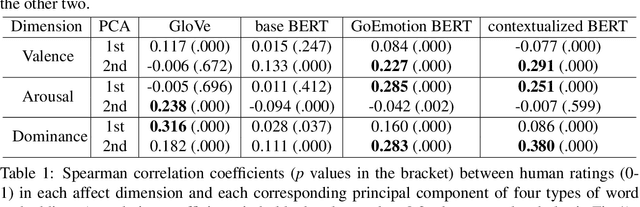

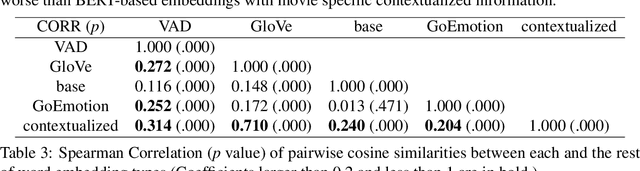
A growing body of research in natural language processing (NLP) and natural language understanding (NLU) is investigating human-like knowledge learned or encoded in the word embeddings from large language models. This is a step towards understanding what knowledge language models capture that resembles human understanding of language and communication. Here, we investigated whether and how the affect meaning of a word (i.e., valence, arousal, dominance) is encoded in word embeddings pre-trained in large neural networks. We used the human-labeled dataset as the ground truth and performed various correlational and classification tests on four types of word embeddings. The embeddings varied in being static or contextualized, and how much affect specific information was prioritized during the pre-training and fine-tuning phase. Our analyses show that word embedding from the vanilla BERT model did not saliently encode the affect information of English words. Only when the BERT model was fine-tuned on emotion-related tasks or contained extra contextualized information from emotion-rich contexts could the corresponding embedding encode more relevant affect information.
FastHand: Fast Hand Pose Estimation From A Monocular Camera
Feb 14, 2021

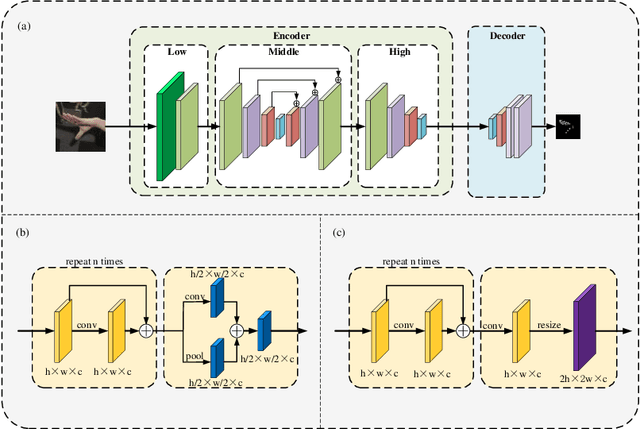

Hand gesture recognition constitutes the initial step in most methods related to human-robot interaction. There are two key challenges in this task. The first one corresponds to the difficulty of achieving stable and accurate hand landmark predictions in real-world scenarios, while the second to the decreased time of forward inference. In this paper, we propose a fast and accurate framework for hand pose estimation, dubbed as "FastHand". Using a lightweight encoder-decoder network architecture, we achieve to fulfil the requirements of practical applications running on embedded devices. The encoder consists of deep layers with a small number of parameters, while the decoder makes use of spatial location information to obtain more accurate results. The evaluation took place on two publicly available datasets demonstrating the improved performance of the proposed pipeline compared to other state-of-the-art approaches. FastHand offers high accuracy scores while reaching a speed of 25 frames per second on an NVIDIA Jetson TX2 graphics processing unit.