 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed-CoReasoner: Reducing Language Disparities in Medical Reasoning via Language-Informed Co-Reasoning
Jan 13, 2026While reasoning-enhanced large language models perform strongly on English medical tasks, a persistent multilingual gap remains, with substantially weaker reasoning in local languages, limiting equitable global medical deployment. To bridge this gap, we introduce Med-CoReasoner, a language-informed co-reasoning framework that elicits parallel English and local-language reasoning, abstracts them into structured concepts, and integrates local clinical knowledge into an English logical scaffold via concept-level alignment and retrieval. This design combines the structural robustness of English reasoning with the practice-grounded expertise encoded in local languages. To evaluate multilingual medical reasoning beyond multiple-choice settings, we construct MultiMed-X, a benchmark covering seven languages with expert-annotated long-form question answering and natural language inference tasks, comprising 350 instances per language. Experiments across three benchmarks show that Med-CoReasoner improves multilingual reasoning performance by an average of 5%, with particularly substantial gains in low-resource languages. Moreover, model distillation and expert evaluation analysis further confirm that Med-CoReasoner produces clinically sound and culturally grounded reasoning traces.
From Chains to Graphs: Self-Structured Reasoning for General-Domain LLMs
Jan 07, 2026Large Language Models (LLMs) show strong reasoning ability in open-domain question answering, yet their reasoning processes are typically linear and often logically inconsistent. In contrast, real-world reasoning requires integrating multiple premises and solving subproblems in parallel. Existing methods, such as Chain-of-Thought (CoT), express reasoning in a linear textual form, which may appear coherent but frequently leads to inconsistent conclusions. Recent approaches rely on externally provided graphs and do not explore how LLMs can construct and use their own graph-structured reasoning, particularly in open-domain QA. To fill this gap, we novelly explore graph-structured reasoning of LLMs in general-domain question answering. We propose Self-Graph Reasoning (SGR), a framework that enables LLMs to explicitly represent their reasoning process as a structured graph before producing the final answer. We further construct a graph-structured reasoning dataset that merges multiple candidate reasoning graphs into refined graph structures for model training. Experiments on five QA benchmarks across both general and specialized domains show that SGR consistently improves reasoning consistency and yields a 17.74% gain over the base model. The LLaMA-3.3-70B model fine-tuned with SGR performs comparably to GPT-4o and surpasses Claude-3.5-Haiku, demonstrating the effectiveness of graph-structured reasoning.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Investigating the Multilingual Calibration Effects of Language Model Instruction-Tuning
Jan 04, 2026Ensuring that deep learning models are well-calibrated in terms of their predictive uncertainty is essential in maintaining their trustworthiness and reliability, yet despite increasing advances in foundation model research, the relationship between such large language models (LLMs) and their calibration remains an open area of research. In this work, we look at a critical gap in the calibration of LLMs within multilingual settings, in an attempt to better understand how the data scarcity can potentially lead to different calibration effects and how commonly used techniques can apply in these settings. Our analysis on two multilingual benchmarks, over 29 and 42 languages respectively, reveals that even in low-resource languages, model confidence can increase significantly after instruction-tuning on high-resource language SFT datasets. However, improvements in accuracy are marginal or non-existent, resulting in mis-calibration, highlighting a critical shortcoming of standard SFT for multilingual languages. Furthermore, we observe that the use of label smoothing to be a reasonable method alleviate this concern, again without any need for low-resource SFT data, maintaining better calibration across all languages. Overall, this highlights the importance of multilingual considerations for both training and tuning LLMs in order to improve their reliability and fairness in downstream use.
The Evolving Landscape of Generative Large Language Models and Traditional Natural Language Processing in Medicine
May 15, 2025Natural language processing (NLP) has been traditionally applied to medicine, and generative large language models (LLMs) have become prominent recently. However, the differences between them across different medical tasks remain underexplored. We analyzed 19,123 studies, finding that generative LLMs demonstrate advantages in open-ended tasks, while traditional NLP dominates in information extraction and analysis tasks. As these technologies advance, ethical use of them is essential to ensure their potential in medical applications.
HealthGenie: Empowering Users with Healthy Dietary Guidance through Knowledge Graph and Large Language Models
Apr 20, 2025Seeking dietary guidance often requires navigating complex professional knowledge while accommodating individual health conditions. Knowledge Graphs (KGs) offer structured and interpretable nutritional information, whereas Large Language Models (LLMs) naturally facilitate conversational recommendation delivery. In this paper, we present HealthGenie, an interactive system that combines the strengths of LLMs and KGs to provide personalized dietary recommendations along with hierarchical information visualization for a quick and intuitive overview. Upon receiving a user query, HealthGenie performs query refinement and retrieves relevant information from a pre-built KG. The system then visualizes and highlights pertinent information, organized by defined categories, while offering detailed, explainable recommendation rationales. Users can further tailor these recommendations by adjusting preferences interactively. Our evaluation, comprising a within-subject comparative experiment and an open-ended discussion, demonstrates that HealthGenie effectively supports users in obtaining personalized dietary guidance based on their health conditions while reducing interaction effort and cognitive load. These findings highlight the potential of LLM-KG integration in supporting decision-making through explainable and visualized information. We examine the system's usefulness and effectiveness with an N=12 within-subject study and provide design considerations for future systems that integrate conversational LLM and KG.
Exploring the Role of Knowledge Graph-Based RAG in Japanese Medical Question Answering with Small-Scale LLMs
Apr 16, 2025Large language models (LLMs) perform well in medical QA, but their effectiveness in Japanese contexts is limited due to privacy constraints that prevent the use of commercial models like GPT-4 in clinical settings. As a result, recent efforts focus on instruction-tuning open-source LLMs, though the potential of combining them with retrieval-augmented generation (RAG) remains underexplored. To bridge this gap, we are the first to explore a knowledge graph-based (KG) RAG framework for Japanese medical QA small-scale open-source LLMs. Experimental results show that KG-based RAG has only a limited impact on Japanese medical QA using small-scale open-source LLMs. Further case studies reveal that the effectiveness of the RAG is sensitive to the quality and relevance of the external retrieved content. These findings offer valuable insights into the challenges and potential of applying RAG in Japanese medical QA, while also serving as a reference for other low-resource languages.
JiraiBench: A Bilingual Benchmark for Evaluating Large Language Models' Detection of Human Self-Destructive Behavior Content in Jirai Community
Mar 27, 2025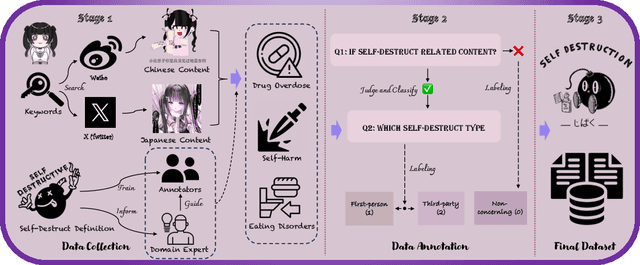
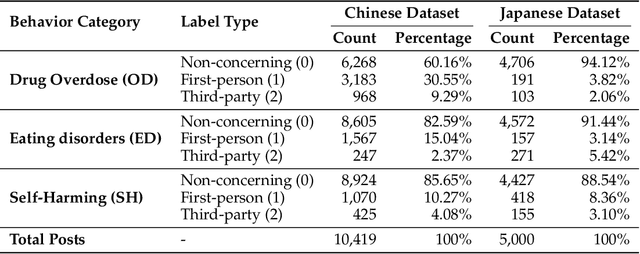


This paper introduces JiraiBench, the first bilingual benchmark for evaluating large language models' effectiveness in detecting self-destructive content across Chinese and Japanese social media communities. Focusing on the transnational "Jirai" (landmine) online subculture that encompasses multiple forms of self-destructive behaviors including drug overdose, eating disorders, and self-harm, we present a comprehensive evaluation framework incorporating both linguistic and cultural dimensions. Our dataset comprises 10,419 Chinese posts and 5,000 Japanese posts with multidimensional annotation along three behavioral categories, achieving substantial inter-annotator agreement. Experimental evaluations across four state-of-the-art models reveal significant performance variations based on instructional language, with Japanese prompts unexpectedly outperforming Chinese prompts when processing Chinese content. This emergent cross-cultural transfer suggests that cultural proximity can sometimes outweigh linguistic similarity in detection tasks. Cross-lingual transfer experiments with fine-tuned models further demonstrate the potential for knowledge transfer between these language systems without explicit target language training. These findings highlight the need for culturally-informed approaches to multilingual content moderation and provide empirical evidence for the importance of cultural context in developing more effective detection systems for vulnerable online communities.
MKG-Rank: Enhancing Large Language Models with Knowledge Graph for Multilingual Medical Question Answering
Mar 21, 2025Large Language Models (LLMs) have shown remarkable progress in medical question answering (QA), yet their effectiveness remains predominantly limited to English due to imbalanced multilingual training data and scarce medical resources for low-resource languages. To address this critical language gap in medical QA, we propose Multilingual Knowledge Graph-based Retrieval Ranking (MKG-Rank), a knowledge graph-enhanced framework that enables English-centric LLMs to perform multilingual medical QA. Through a word-level translation mechanism, our framework efficiently integrates comprehensive English-centric medical knowledge graphs into LLM reasoning at a low cost, mitigating cross-lingual semantic distortion and achieving precise medical QA across language barriers. To enhance efficiency, we introduce caching and multi-angle ranking strategies to optimize the retrieval process, significantly reducing response times and prioritizing relevant medical knowledge. Extensive evaluations on multilingual medical QA benchmarks across Chinese, Japanese, Korean, and Swahili demonstrate that MKG-Rank consistently outperforms zero-shot LLMs, achieving maximum 35.03% increase in accuracy, while maintaining an average retrieval time of only 0.0009 seconds.
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
Mar 13, 2025

Traditional benchmarks struggle to evaluate increasingly sophisticated language models in multilingual and culturally diverse contexts. To address this gap, we introduce MMLU-ProX, a comprehensive multilingual benchmark covering 13 typologically diverse languages with approximately 11,829 questions per language. Building on the challenging reasoning-focused design of MMLU-Pro, our framework employs a semi-automatic translation process: translations generated by state-of-the-art large language models (LLMs) are rigorously evaluated by expert annotators to ensure conceptual accuracy, terminological consistency, and cultural relevance. We comprehensively evaluate 25 state-of-the-art LLMs using 5-shot chain-of-thought (CoT) and zero-shot prompting strategies, analyzing their performance across linguistic and cultural boundaries. Our experiments reveal consistent performance degradation from high-resource languages to lower-resource ones, with the best models achieving over 70% accuracy on English but dropping to around 40% for languages like Swahili, highlighting persistent gaps in multilingual capabilities despite recent advances. MMLU-ProX is an ongoing project; we are expanding our benchmark by incorporating additional languages and evaluating more language models to provide a more comprehensive assessment of multilingual capabilities.