 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Role of Knowledge Graph-Based RAG in Japanese Medical Question Answering with Small-Scale LLMs
Apr 16, 2025Large language models (LLMs) perform well in medical QA, but their effectiveness in Japanese contexts is limited due to privacy constraints that prevent the use of commercial models like GPT-4 in clinical settings. As a result, recent efforts focus on instruction-tuning open-source LLMs, though the potential of combining them with retrieval-augmented generation (RAG) remains underexplored. To bridge this gap, we are the first to explore a knowledge graph-based (KG) RAG framework for Japanese medical QA small-scale open-source LLMs. Experimental results show that KG-based RAG has only a limited impact on Japanese medical QA using small-scale open-source LLMs. Further case studies reveal that the effectiveness of the RAG is sensitive to the quality and relevance of the external retrieved content. These findings offer valuable insights into the challenges and potential of applying RAG in Japanese medical QA, while also serving as a reference for other low-resource languages.
JiraiBench: A Bilingual Benchmark for Evaluating Large Language Models' Detection of Human Self-Destructive Behavior Content in Jirai Community
Mar 27, 2025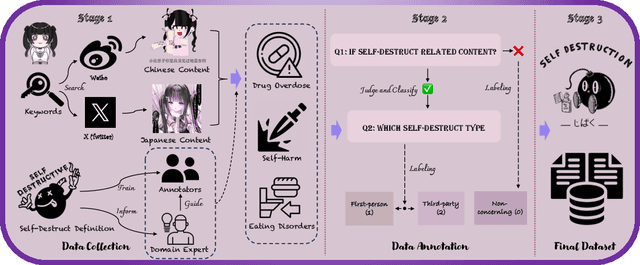
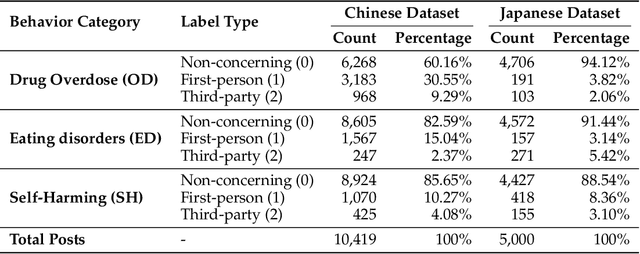


This paper introduces JiraiBench, the first bilingual benchmark for evaluating large language models' effectiveness in detecting self-destructive content across Chinese and Japanese social media communities. Focusing on the transnational "Jirai" (landmine) online subculture that encompasses multiple forms of self-destructive behaviors including drug overdose, eating disorders, and self-harm, we present a comprehensive evaluation framework incorporating both linguistic and cultural dimensions. Our dataset comprises 10,419 Chinese posts and 5,000 Japanese posts with multidimensional annotation along three behavioral categories, achieving substantial inter-annotator agreement. Experimental evaluations across four state-of-the-art models reveal significant performance variations based on instructional language, with Japanese prompts unexpectedly outperforming Chinese prompts when processing Chinese content. This emergent cross-cultural transfer suggests that cultural proximity can sometimes outweigh linguistic similarity in detection tasks. Cross-lingual transfer experiments with fine-tuned models further demonstrate the potential for knowledge transfer between these language systems without explicit target language training. These findings highlight the need for culturally-informed approaches to multilingual content moderation and provide empirical evidence for the importance of cultural context in developing more effective detection systems for vulnerable online communities.
Quater-GCN: Enhancing 3D Human Pose Estimation with Orientation and Semi-supervised Training
Apr 30, 2024



3D human pose estimation is a vital task in computer vision, involving the prediction of human joint positions from images or videos to reconstruct a skeleton of a human in three-dimensional space. This technology is pivotal in various fields, including animation, security, human-computer interaction, and automotive safety, where it promotes both technological progress and enhanced human well-being. The advent of deep learning significantly advances the performance of 3D pose estimation by incorporating temporal information for predicting the spatial positions of human joints. However, traditional methods often fall short as they primarily focus on the spatial coordinates of joints and overlook the orientation and rotation of the connecting bones, which are crucial for a comprehensive understanding of human pose in 3D space. To address these limitations, we introduce Quater-GCN (Q-GCN), a directed graph convolutional network tailored to enhance pose estimation by orientation. Q-GCN excels by not only capturing the spatial dependencies among node joints through their coordinates but also integrating the dynamic context of bone rotations in 2D space. This approach enables a more sophisticated representation of human poses by also regressing the orientation of each bone in 3D space, moving beyond mere coordinate prediction. Furthermore, we complement our model with a semi-supervised training strategy that leverages unlabeled data, addressing the challenge of limited orientation ground truth data. Through comprehensive evaluations, Q-GCN has demonstrated outstanding performance against current state-of-the-art methods.
An Animation-based Augmentation Approach for Action Recognition from Discontinuous Video
Apr 10, 2024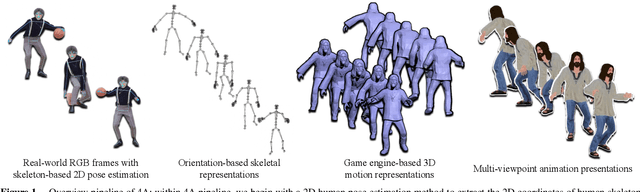
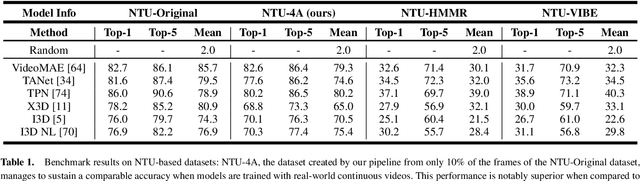
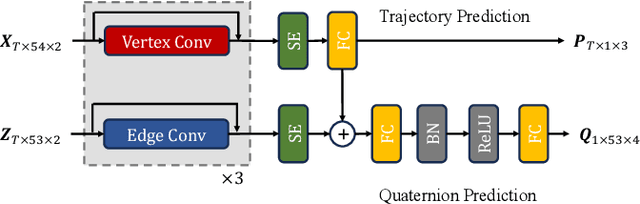
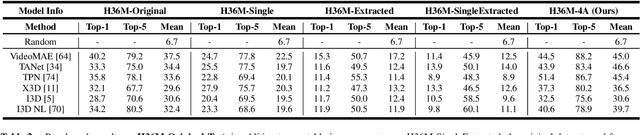
The study of action recognition has attracted considerable attention recently due to its broad applications in multiple areas. However, with the issue of discontinuous training video, which not only decreases the performance of action recognition model, but complicates the data augmentation process as well, still remains under-exploration. In this study, we introduce the 4A (Action Animation-based Augmentation Approach), an innovative pipeline for data augmentation to address the problem. The main contributions remain in our work includes: (1) we investigate the problem of severe decrease on performance of action recognition task training by discontinuous video, and the limitation of existing augmentation methods on solving this problem. (2) we propose a novel augmentation pipeline, 4A, to address the problem of discontinuous video for training, while achieving a smoother and natural-looking action representation than the latest data augmentation methodology. (3) We achieve the same performance with only 10% of the original data for training as with all of the original data from the real-world dataset, and a better performance on In-the-wild videos, by employing our data augmentation techniques.
GTAutoAct: An Automatic Datasets Generation Framework Based on Game Engine Redevelopment for Action Recognition
Jan 24, 2024Current datasets for action recognition tasks face limitations stemming from traditional collection and generation methods, including the constrained range of action classes, absence of multi-viewpoint recordings, limited diversity, poor video quality, and labor-intensive manually collection. To address these challenges, we introduce GTAutoAct, a innovative dataset generation framework leveraging game engine technology to facilitate advancements in action recognition. GTAutoAct excels in automatically creating large-scale, well-annotated datasets with extensive action classes and superior video quality. Our framework's distinctive contributions encompass: (1) it innovatively transforms readily available coordinate-based 3D human motion into rotation-orientated representation with enhanced suitability in multiple viewpoints; (2) it employs dynamic segmentation and interpolation of rotation sequences to create smooth and realistic animations of action; (3) it offers extensively customizable animation scenes; (4) it implements an autonomous video capture and processing pipeline, featuring a randomly navigating camera, with auto-trimming and labeling functionalities. Experimental results underscore the framework's robustness and highlights its potential to significantly improve action recognition model training.