 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELLMob: Event-Driven Human Mobility Generation with Self-Aligned LLM Framework
Mar 09, 2026Human mobility generation aims to synthesize plausible trajectory data, which is widely used in urban system research. While Large Language Model-based methods excel at generating routine trajectories, they struggle to capture deviated mobility during large-scale societal events. This limitation stems from two critical gaps: (1) the absence of event-annotated mobility datasets for design and evaluation, and (2) the inability of current frameworks to reconcile competitions between users' habitual patterns and event-imposed constraints when making trajectory decisions. This work addresses these gaps with a twofold contribution. First, we construct the first event-annotated mobility dataset covering three major events: Typhoon Hagibis, COVID-19, and the Tokyo 2021 Olympics. Second, we propose ELLMob, a self-aligned LLM framework that first extracts competing rationales between habitual patterns and event constraints, based on Fuzzy-Trace Theory, and then iteratively aligns them to generate trajectories that are both habitually grounded and event-responsive. Extensive experiments show that ELLMob wins state-of-the-art baselines across all events, demonstrating its effectiveness. Our codes and datasets are available at https://github.com/deepkashiwa20/ELLMob.
TrajGPT-R: Generating Urban Mobility Trajectory with Reinforcement Learning-Enhanced Generative Pre-trained Transformer
Feb 24, 2026Mobility trajectories are essential for understanding urban dynamics and enhancing urban planning, yet access to such data is frequently hindered by privacy concerns. This research introduces a transformative framework for generating large-scale urban mobility trajectories, employing a novel application of a transformer-based model pre-trained and fine-tuned through a two-phase process. Initially, trajectory generation is conceptualized as an offline reinforcement learning (RL) problem, with a significant reduction in vocabulary space achieved during tokenization. The integration of Inverse Reinforcement Learning (IRL) allows for the capture of trajectory-wise reward signals, leveraging historical data to infer individual mobility preferences. Subsequently, the pre-trained model is fine-tuned using the constructed reward model, effectively addressing the challenges inherent in traditional RL-based autoregressive methods, such as long-term credit assignment and handling of sparse reward environments. Comprehensive evaluations on multiple datasets illustrate that our framework markedly surpasses existing models in terms of reliability and diversity. Our findings not only advance the field of urban mobility modeling but also provide a robust methodology for simulating urban data, with significant implications for traffic management and urban development planning. The implementation is publicly available at https://github.com/Wangjw6/TrajGPT_R.
Co-EPG: A Framework for Co-Evolution of Planning and Grounding in Autonomous GUI Agents
Nov 13, 2025Graphical User Interface (GUI) task automation constitutes a critical frontier in artificial intelligence research. While effective GUI agents synergistically integrate planning and grounding capabilities, current methodologies exhibit two fundamental limitations: (1) insufficient exploitation of cross-model synergies, and (2) over-reliance on synthetic data generation without sufficient utilization. To address these challenges, we propose Co-EPG, a self-iterative training framework for Co-Evolution of Planning and Grounding. Co-EPG establishes an iterative positive feedback loop: through this loop, the planning model explores superior strategies under grounding-based reward guidance via Group Relative Policy Optimization (GRPO), generating diverse data to optimize the grounding model. Concurrently, the optimized Grounding model provides more effective rewards for subsequent GRPO training of the planning model, fostering continuous improvement. Co-EPG thus enables iterative enhancement of agent capabilities through self-play optimization and training data distillation. On the Multimodal-Mind2Web and AndroidControl benchmarks, our framework outperforms existing state-of-the-art methods after just three iterations without requiring external data. The agent consistently improves with each iteration, demonstrating robust self-enhancement capabilities. This work establishes a novel training paradigm for GUI agents, shifting from isolated optimization to an integrated, self-driven co-evolution approach.
Importance-Aware Data Selection for Efficient LLM Instruction Tuning
Nov 10, 2025Instruction tuning plays a critical role in enhancing the performance and efficiency of Large Language Models (LLMs). Its success depends not only on the quality of the instruction data but also on the inherent capabilities of the LLM itself. Some studies suggest that even a small amount of high-quality data can achieve instruction fine-tuning results that are on par with, or even exceed, those from using a full-scale dataset. However, rather than focusing solely on calculating data quality scores to evaluate instruction data, there is a growing need to select high-quality data that maximally enhances the performance of instruction tuning for a given LLM. In this paper, we propose the Model Instruction Weakness Value (MIWV) as a novel metric to quantify the importance of instruction data in enhancing model's capabilities. The MIWV metric is derived from the discrepancies in the model's responses when using In-Context Learning (ICL), helping identify the most beneficial data for enhancing instruction tuning performance. Our experimental results demonstrate that selecting only the top 1\% of data based on MIWV can outperform training on the full dataset. Furthermore, this approach extends beyond existing research that focuses on data quality scoring for data selection, offering strong empirical evidence supporting the effectiveness of our proposed method.
JiraiBench: A Bilingual Benchmark for Evaluating Large Language Models' Detection of Human Self-Destructive Behavior Content in Jirai Community
Mar 27, 2025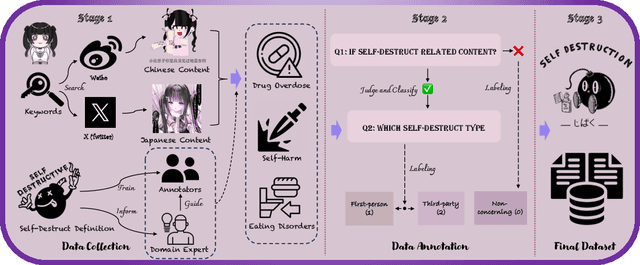
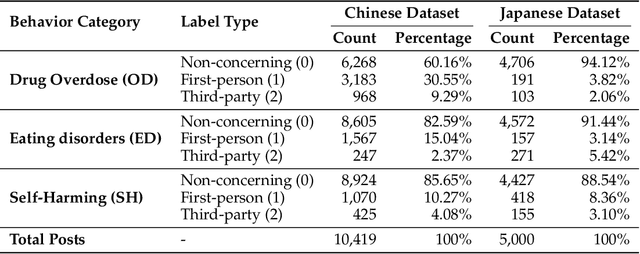


This paper introduces JiraiBench, the first bilingual benchmark for evaluating large language models' effectiveness in detecting self-destructive content across Chinese and Japanese social media communities. Focusing on the transnational "Jirai" (landmine) online subculture that encompasses multiple forms of self-destructive behaviors including drug overdose, eating disorders, and self-harm, we present a comprehensive evaluation framework incorporating both linguistic and cultural dimensions. Our dataset comprises 10,419 Chinese posts and 5,000 Japanese posts with multidimensional annotation along three behavioral categories, achieving substantial inter-annotator agreement. Experimental evaluations across four state-of-the-art models reveal significant performance variations based on instructional language, with Japanese prompts unexpectedly outperforming Chinese prompts when processing Chinese content. This emergent cross-cultural transfer suggests that cultural proximity can sometimes outweigh linguistic similarity in detection tasks. Cross-lingual transfer experiments with fine-tuned models further demonstrate the potential for knowledge transfer between these language systems without explicit target language training. These findings highlight the need for culturally-informed approaches to multilingual content moderation and provide empirical evidence for the importance of cultural context in developing more effective detection systems for vulnerable online communities.
Instruction-Tuning Llama-3-8B Excels in City-Scale Mobility Prediction
Oct 31, 2024



Human mobility prediction plays a critical role in applications such as disaster response, urban planning, and epidemic forecasting. Traditional methods often rely on designing crafted, domain-specific models, and typically focus on short-term predictions, which struggle to generalize across diverse urban environments. In this study, we introduce Llama-3-8B-Mob, a large language model fine-tuned with instruction tuning, for long-term citywide mobility prediction -- in a Q&A manner. We validate our approach using large-scale human mobility data from four metropolitan areas in Japan, focusing on predicting individual trajectories over the next 15 days. The results demonstrate that Llama-3-8B-Mob excels in modeling long-term human mobility -- surpassing the state-of-the-art on multiple prediction metrics. It also displays strong zero-shot generalization capabilities -- effectively generalizing to other cities even when fine-tuned only on limited samples from a single city. Source codes are available at https://github.com/TANGHULU6/Llama3-8B-Mob.
Taming the Long Tail in Human Mobility Prediction
Oct 19, 2024



With the popularity of location-based services, human mobility prediction plays a key role in enhancing personalized navigation, optimizing recommendation systems, and facilitating urban mobility and planning. This involves predicting a user's next POI (point-of-interest) visit using their past visit history. However, the uneven distribution of visitations over time and space, namely the long-tail problem in spatial distribution, makes it difficult for AI models to predict those POIs that are less visited by humans. In light of this issue, we propose the Long-Tail Adjusted Next POI Prediction (LoTNext) framework for mobility prediction, combining a Long-Tailed Graph Adjustment module to reduce the impact of the long-tailed nodes in the user-POI interaction graph and a novel Long-Tailed Loss Adjustment module to adjust loss by logit score and sample weight adjustment strategy. Also, we employ the auxiliary prediction task to enhance generalization and accuracy. Our experiments with two real-world trajectory datasets demonstrate that LoTNext significantly surpasses existing state-of-the-art works. Our code is available at https://github.com/Yukayo/LoTNext.
SIMformer: Single-Layer Vanilla Transformer Can Learn Free-Space Trajectory Similarity
Oct 18, 2024



Free-space trajectory similarity calculation, e.g., DTW, Hausdorff, and Frechet, often incur quadratic time complexity, thus learning-based methods have been proposed to accelerate the computation. The core idea is to train an encoder to transform trajectories into representation vectors and then compute vector similarity to approximate the ground truth. However, existing methods face dual challenges of effectiveness and efficiency: 1) they all utilize Euclidean distance to compute representation similarity, which leads to the severe curse of dimensionality issue -- reducing the distinguishability among representations and significantly affecting the accuracy of subsequent similarity search tasks; 2) most of them are trained in triplets manner and often necessitate additional information which downgrades the efficiency; 3) previous studies, while emphasizing the scalability in terms of efficiency, overlooked the deterioration of effectiveness when the dataset size grows. To cope with these issues, we propose a simple, yet accurate, fast, scalable model that only uses a single-layer vanilla transformer encoder as the feature extractor and employs tailored representation similarity functions to approximate various ground truth similarity measures. Extensive experiments demonstrate our model significantly mitigates the curse of dimensionality issue and outperforms the state-of-the-arts in effectiveness, efficiency, and scalability.
A Detailed Audio-Text Data Simulation Pipeline using Single-Event Sounds
Mar 07, 2024



Recently, there has been an increasing focus on audio-text cross-modal learning. However, most of the existing audio-text datasets contain only simple descriptions of sound events. Compared with classification labels, the advantages of such descriptions are significantly limited. In this paper, we first analyze the detailed information that human descriptions of audio may contain beyond sound event labels. Based on the analysis, we propose an automatic pipeline for curating audio-text pairs with rich details. Leveraging the property that sounds can be mixed and concatenated in the time domain, we control details in four aspects: temporal relationship, loudness, speaker identity, and occurrence number, in simulating audio mixtures. Corresponding details are transformed into captions by large language models. Audio-text pairs with rich details in text descriptions are thereby obtained. We validate the effectiveness of our pipeline with a small amount of simulated data, demonstrating that the simulated data enables models to learn detailed audio captioning.
Revisiting Mobility Modeling with Graph: A Graph Transformer Model for Next Point-of-Interest Recommendation
Oct 02, 2023Next Point-of-Interest (POI) recommendation plays a crucial role in urban mobility applications. Recently, POI recommendation models based on Graph Neural Networks (GNN) have been extensively studied and achieved, however, the effective incorporation of both spatial and temporal information into such GNN-based models remains challenging. Extracting distinct fine-grained features unique to each piece of information is difficult since temporal information often includes spatial information, as users tend to visit nearby POIs. To address the challenge, we propose \textbf{\underline{Mob}}ility \textbf{\underline{G}}raph \textbf{\underline{T}}ransformer (MobGT) that enables us to fully leverage graphs to capture both the spatial and temporal features in users' mobility patterns. MobGT combines individual spatial and temporal graph encoders to capture unique features and global user-location relations. Additionally, it incorporates a mobility encoder based on Graph Transformer to extract higher-order information between POIs. To address the long-tailed problem in spatial-temporal data, MobGT introduces a novel loss function, Tail Loss. Experimental results demonstrate that MobGT outperforms state-of-the-art models on various datasets and metrics, achieving 24\% improvement on average. Our codes are available at \url{https://github.com/Yukayo/MobGT}.