 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuouSP: Generative Model for Crystal Structure Prediction with Invariance and Continuity
Feb 04, 2025


The discovery of new materials using crystal structure prediction (CSP) based on generative machine learning models has become a significant research topic in recent years. In this paper, we study invariance and continuity in the generative machine learning for CSP. We propose a new model, called ContinuouSP, which effectively handles symmetry and periodicity in crystals. We clearly formulate the invariance and the continuity, and construct a model based on the energy-based model. Our preliminary evaluation demonstrates the effectiveness of this model with the CSP task.
Revisiting Mobility Modeling with Graph: A Graph Transformer Model for Next Point-of-Interest Recommendation
Oct 02, 2023Next Point-of-Interest (POI) recommendation plays a crucial role in urban mobility applications. Recently, POI recommendation models based on Graph Neural Networks (GNN) have been extensively studied and achieved, however, the effective incorporation of both spatial and temporal information into such GNN-based models remains challenging. Extracting distinct fine-grained features unique to each piece of information is difficult since temporal information often includes spatial information, as users tend to visit nearby POIs. To address the challenge, we propose \textbf{\underline{Mob}}ility \textbf{\underline{G}}raph \textbf{\underline{T}}ransformer (MobGT) that enables us to fully leverage graphs to capture both the spatial and temporal features in users' mobility patterns. MobGT combines individual spatial and temporal graph encoders to capture unique features and global user-location relations. Additionally, it incorporates a mobility encoder based on Graph Transformer to extract higher-order information between POIs. To address the long-tailed problem in spatial-temporal data, MobGT introduces a novel loss function, Tail Loss. Experimental results demonstrate that MobGT outperforms state-of-the-art models on various datasets and metrics, achieving 24\% improvement on average. Our codes are available at \url{https://github.com/Yukayo/MobGT}.
On Data Imbalance in Molecular Property Prediction with Pre-training
Aug 17, 2023Revealing and analyzing the various properties of materials is an essential and critical issue in the development of materials, including batteries, semiconductors, catalysts, and pharmaceuticals. Traditionally, these properties have been determined through theoretical calculations and simulations. However, it is not practical to perform such calculations on every single candidate material. Recently, a combination method of the theoretical calculation and machine learning has emerged, that involves training machine learning models on a subset of theoretical calculation results to construct a surrogate model that can be applied to the remaining materials. On the other hand, a technique called pre-training is used to improve the accuracy of machine learning models. Pre-training involves training the model on pretext task, which is different from the target task, before training the model on the target task. This process aims to extract the input data features, stabilizing the learning process and improving its accuracy. However, in the case of molecular property prediction, there is a strong imbalance in the distribution of input data and features, which may lead to biased learning towards frequently occurring data during pre-training. In this study, we propose an effective pre-training method that addresses the imbalance in input data. We aim to improve the final accuracy by modifying the loss function of the existing representative pre-training method, node masking, to compensate the imbalance. We have investigated and assessed the impact of our proposed imbalance compensation on pre-training and the final prediction accuracy through experiments and evaluations using benchmark of molecular property prediction models.
Is Self-Supervised Pretraining Good for Extrapolation in Molecular Property Prediction?
Aug 16, 2023The prediction of material properties plays a crucial role in the development and discovery of materials in diverse applications, such as batteries, semiconductors, catalysts, and pharmaceuticals. Recently, there has been a growing interest in employing data-driven approaches by using machine learning technologies, in combination with conventional theoretical calculations. In material science, the prediction of unobserved values, commonly referred to as extrapolation, is particularly critical for property prediction as it enables researchers to gain insight into materials beyond the limits of available data. However, even with the recent advancements in powerful machine learning models, accurate extrapolation is still widely recognized as a significantly challenging problem. On the other hand, self-supervised pretraining is a machine learning technique where a model is first trained on unlabeled data using relatively simple pretext tasks before being trained on labeled data for target tasks. As self-supervised pretraining can effectively utilize material data without observed property values, it has the potential to improve the model's extrapolation ability. In this paper, we clarify how such self-supervised pretraining can enhance extrapolation performance.We propose an experimental framework for the demonstration and empirically reveal that while models were unable to accurately extrapolate absolute property values, self-supervised pretraining enables them to learn relative tendencies of unobserved property values and improve extrapolation performance.
mdx: A Cloud Platform for Supporting Data Science and Cross-Disciplinary Research Collaborations
Mar 27, 2022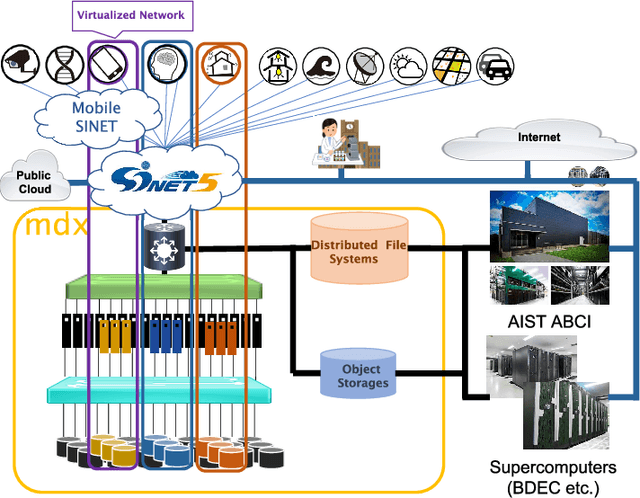
The growing amount of data and advances in data science have created a need for a new kind of cloud platform that provides users with flexibility, strong security, and the ability to couple with supercomputers and edge devices through high-performance networks. We have built such a nation-wide cloud platform, called "mdx" to meet this need. The mdx platform's virtualization service, jointly operated by 9 national universities and 2 national research institutes in Japan, launched in 2021, and more features are in development. Currently mdx is used by researchers in a wide variety of domains, including materials informatics, geo-spatial information science, life science, astronomical science, economics, social science, and computer science. This paper provides an the overview of the mdx platform, details the motivation for its development, reports its current status, and outlines its future plans.
Global Data Science Project for COVID-19 Summary Report
Jun 10, 2020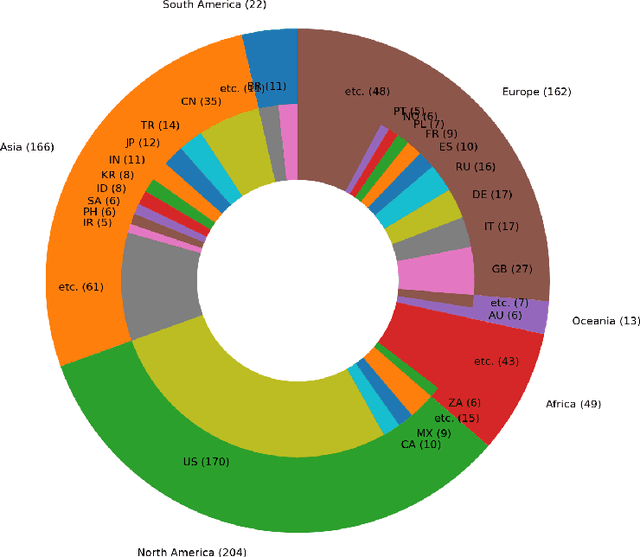
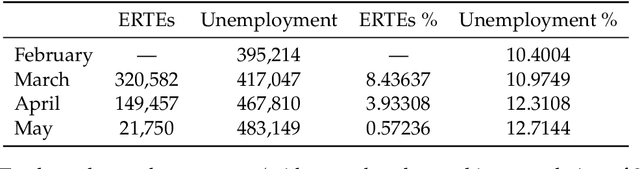
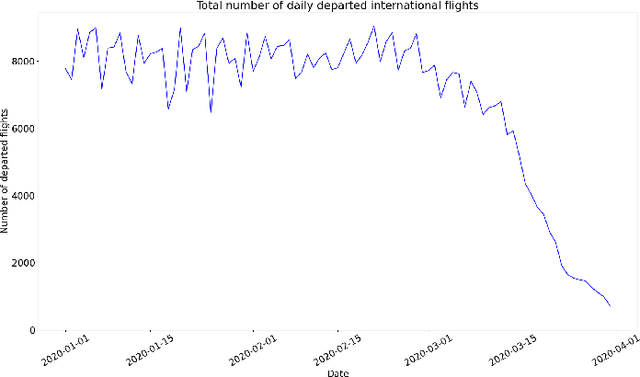
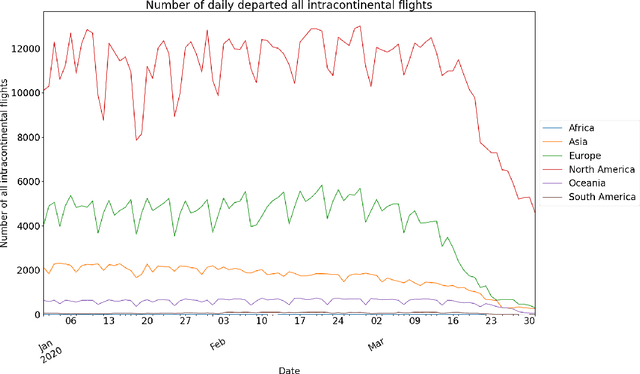
This paper aims at providing the summary of the Global Data Science Project (GDSC) for COVID-19. as on May 31 2020. COVID-19 has largely impacted on our societies through both direct and indirect effects transmitted by the policy measures to counter the spread of viruses. We quantitatively analysed the multifaceted impacts of the COVID-19 pandemic on our societies including people's mobility, health, and social behaviour changes. People's mobility has changed significantly due to the implementation of travel restriction and quarantine measurements. Indeed, the physical distance has widened at international (cross-border), national and regional level. At international level, due to the travel restrictions, the number of international flights has plunged overall at around 88 percent during March. In particular, the number of flights connecting Europe dropped drastically in mid of March after the United States announced travel restrictions to Europe and the EU and participating countries agreed to close borders, at 84 percent decline compared to March 10th. Similarly, we examined the impacts of quarantine measures in the major city: Tokyo (Japan), New York City (the United States), and Barcelona (Spain). Within all three cities, we found the significant decline in traffic volume. We also identified the increased concern for mental health through the analysis of posts on social networking services such as Twitter and Instagram. Notably, in the beginning of April 2020, the number of post with #depression on Instagram doubled, which might reflect the rise in mental health awareness among Instagram users. Besides, we identified the changes in a wide range of people's social behaviors, as well as economic impacts through the analysis of Instagram data and primary survey data.