 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance-Aware Data Selection for Efficient LLM Instruction Tuning
Nov 10, 2025Instruction tuning plays a critical role in enhancing the performance and efficiency of Large Language Models (LLMs). Its success depends not only on the quality of the instruction data but also on the inherent capabilities of the LLM itself. Some studies suggest that even a small amount of high-quality data can achieve instruction fine-tuning results that are on par with, or even exceed, those from using a full-scale dataset. However, rather than focusing solely on calculating data quality scores to evaluate instruction data, there is a growing need to select high-quality data that maximally enhances the performance of instruction tuning for a given LLM. In this paper, we propose the Model Instruction Weakness Value (MIWV) as a novel metric to quantify the importance of instruction data in enhancing model's capabilities. The MIWV metric is derived from the discrepancies in the model's responses when using In-Context Learning (ICL), helping identify the most beneficial data for enhancing instruction tuning performance. Our experimental results demonstrate that selecting only the top 1\% of data based on MIWV can outperform training on the full dataset. Furthermore, this approach extends beyond existing research that focuses on data quality scoring for data selection, offering strong empirical evidence supporting the effectiveness of our proposed method.
How Different from the Past? Spatio-Temporal Time Series Forecasting with Self-Supervised Deviation Learning
Oct 06, 2025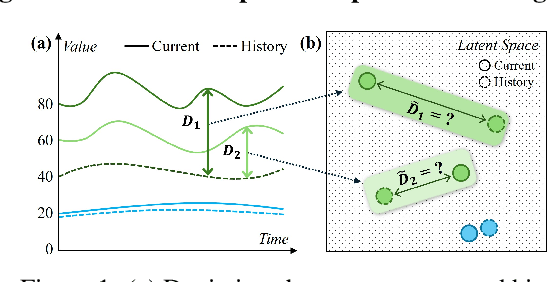
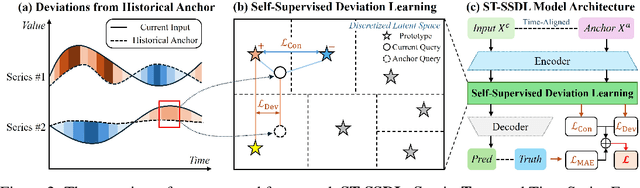
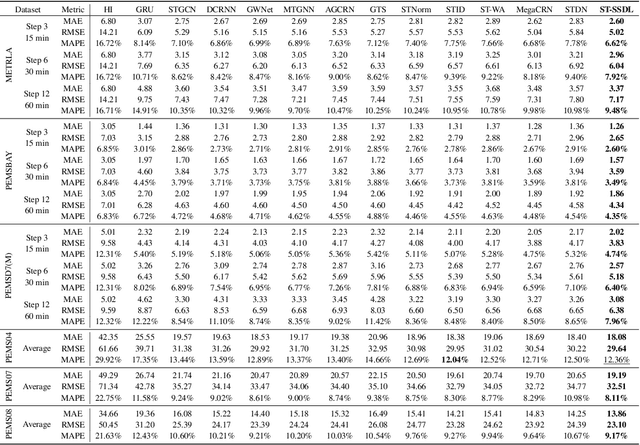
Spatio-temporal forecasting is essential for real-world applications such as traffic management and urban computing. Although recent methods have shown improved accuracy, they often fail to account for dynamic deviations between current inputs and historical patterns. These deviations contain critical signals that can significantly affect model performance. To fill this gap, we propose ST-SSDL, a Spatio-Temporal time series forecasting framework that incorporates a Self-Supervised Deviation Learning scheme to capture and utilize such deviations. ST-SSDL anchors each input to its historical average and discretizes the latent space using learnable prototypes that represent typical spatio-temporal patterns. Two auxiliary objectives are proposed to refine this structure: a contrastive loss that enhances inter-prototype discriminability and a deviation loss that regularizes the distance consistency between input representations and corresponding prototypes to quantify deviation. Optimized jointly with the forecasting objective, these components guide the model to organize its hidden space and improve generalization across diverse input conditions. Experiments on six benchmark datasets show that ST-SSDL consistently outperforms state-of-the-art baselines across multiple metrics. Visualizations further demonstrate its ability to adaptively respond to varying levels of deviation in complex spatio-temporal scenarios. Our code and datasets are available at https://github.com/Jimmy-7664/ST-SSDL.
ContinuouSP: Generative Model for Crystal Structure Prediction with Invariance and Continuity
Feb 04, 2025


The discovery of new materials using crystal structure prediction (CSP) based on generative machine learning models has become a significant research topic in recent years. In this paper, we study invariance and continuity in the generative machine learning for CSP. We propose a new model, called ContinuouSP, which effectively handles symmetry and periodicity in crystals. We clearly formulate the invariance and the continuity, and construct a model based on the energy-based model. Our preliminary evaluation demonstrates the effectiveness of this model with the CSP task.
Extracting Spatiotemporal Data from Gradients with Large Language Models
Oct 21, 2024



Recent works show that sensitive user data can be reconstructed from gradient updates, breaking the key privacy promise of federated learning. While success was demonstrated primarily on image data, these methods do not directly transfer to other domains, such as spatiotemporal data. To understand privacy risks in spatiotemporal federated learning, we first propose Spatiotemporal Gradient Inversion Attack (ST-GIA), a gradient attack algorithm tailored to spatiotemporal data that successfully reconstructs the original location from gradients. Furthermore, the absence of priors in attacks on spatiotemporal data has hindered the accurate reconstruction of real client data. To address this limitation, we propose ST-GIA+, which utilizes an auxiliary language model to guide the search for potential locations, thereby successfully reconstructing the original data from gradients. In addition, we design an adaptive defense strategy to mitigate gradient inversion attacks in spatiotemporal federated learning. By dynamically adjusting the perturbation levels, we can offer tailored protection for varying rounds of training data, thereby achieving a better trade-off between privacy and utility than current state-of-the-art methods. Through intensive experimental analysis on three real-world datasets, we reveal that the proposed defense strategy can well preserve the utility of spatiotemporal federated learning with effective security protection.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
On Data Imbalance in Molecular Property Prediction with Pre-training
Aug 17, 2023Revealing and analyzing the various properties of materials is an essential and critical issue in the development of materials, including batteries, semiconductors, catalysts, and pharmaceuticals. Traditionally, these properties have been determined through theoretical calculations and simulations. However, it is not practical to perform such calculations on every single candidate material. Recently, a combination method of the theoretical calculation and machine learning has emerged, that involves training machine learning models on a subset of theoretical calculation results to construct a surrogate model that can be applied to the remaining materials. On the other hand, a technique called pre-training is used to improve the accuracy of machine learning models. Pre-training involves training the model on pretext task, which is different from the target task, before training the model on the target task. This process aims to extract the input data features, stabilizing the learning process and improving its accuracy. However, in the case of molecular property prediction, there is a strong imbalance in the distribution of input data and features, which may lead to biased learning towards frequently occurring data during pre-training. In this study, we propose an effective pre-training method that addresses the imbalance in input data. We aim to improve the final accuracy by modifying the loss function of the existing representative pre-training method, node masking, to compensate the imbalance. We have investigated and assessed the impact of our proposed imbalance compensation on pre-training and the final prediction accuracy through experiments and evaluations using benchmark of molecular property prediction models.
Is Self-Supervised Pretraining Good for Extrapolation in Molecular Property Prediction?
Aug 16, 2023The prediction of material properties plays a crucial role in the development and discovery of materials in diverse applications, such as batteries, semiconductors, catalysts, and pharmaceuticals. Recently, there has been a growing interest in employing data-driven approaches by using machine learning technologies, in combination with conventional theoretical calculations. In material science, the prediction of unobserved values, commonly referred to as extrapolation, is particularly critical for property prediction as it enables researchers to gain insight into materials beyond the limits of available data. However, even with the recent advancements in powerful machine learning models, accurate extrapolation is still widely recognized as a significantly challenging problem. On the other hand, self-supervised pretraining is a machine learning technique where a model is first trained on unlabeled data using relatively simple pretext tasks before being trained on labeled data for target tasks. As self-supervised pretraining can effectively utilize material data without observed property values, it has the potential to improve the model's extrapolation ability. In this paper, we clarify how such self-supervised pretraining can enhance extrapolation performance.We propose an experimental framework for the demonstration and empirically reveal that while models were unable to accurately extrapolate absolute property values, self-supervised pretraining enables them to learn relative tendencies of unobserved property values and improve extrapolation performance.
mdx: A Cloud Platform for Supporting Data Science and Cross-Disciplinary Research Collaborations
Mar 27, 2022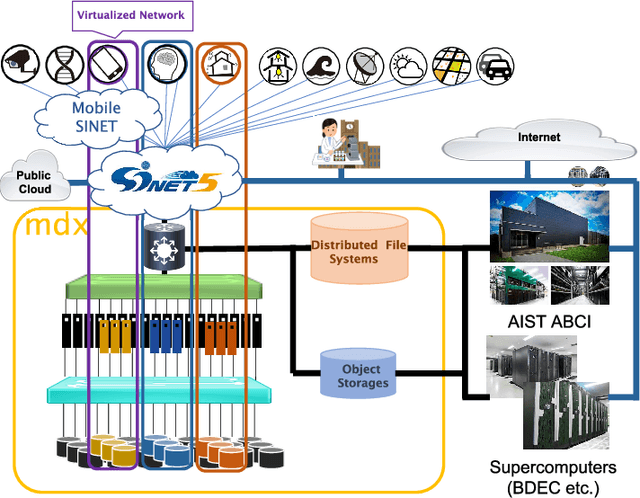
The growing amount of data and advances in data science have created a need for a new kind of cloud platform that provides users with flexibility, strong security, and the ability to couple with supercomputers and edge devices through high-performance networks. We have built such a nation-wide cloud platform, called "mdx" to meet this need. The mdx platform's virtualization service, jointly operated by 9 national universities and 2 national research institutes in Japan, launched in 2021, and more features are in development. Currently mdx is used by researchers in a wide variety of domains, including materials informatics, geo-spatial information science, life science, astronomical science, economics, social science, and computer science. This paper provides an the overview of the mdx platform, details the motivation for its development, reports its current status, and outlines its future plans.
Automatic Graph Partitioning for Very Large-scale Deep Learning
Mar 30, 2021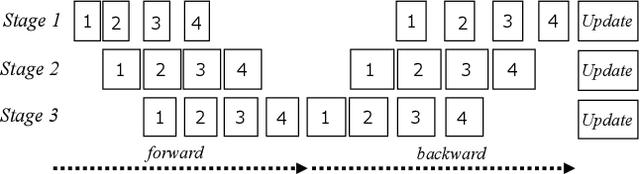
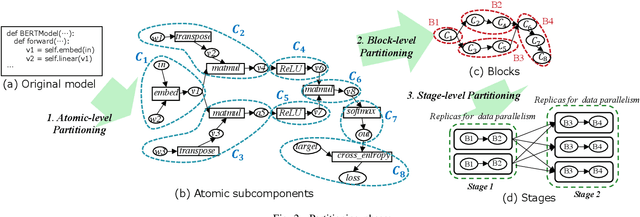
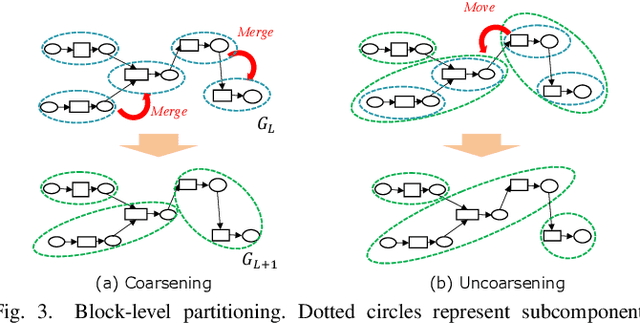
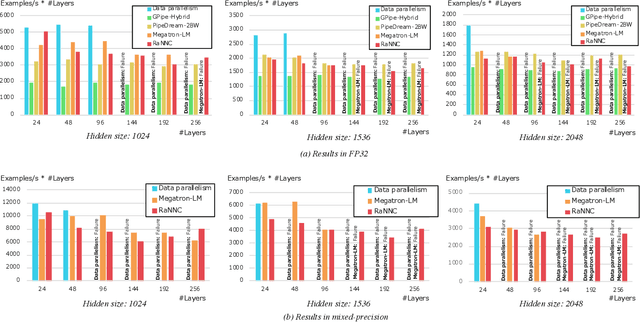
This work proposes RaNNC (Rapid Neural Network Connector) as middleware for automatic hybrid parallelism. In recent deep learning research, as exemplified by T5 and GPT-3, the size of neural network models continues to grow. Since such models do not fit into the memory of accelerator devices, they need to be partitioned by model parallelism techniques. Moreover, to accelerate training for huge training data, we need a combination of model and data parallelisms, i.e., hybrid parallelism. Given a model description for PyTorch without any specification for model parallelism, RaNNC automatically partitions the model into a set of subcomponents so that (1) each subcomponent fits a device memory and (2) a high training throughput for pipeline parallelism is achieved by balancing the computation times of the subcomponents. In our experiments, we compared RaNNC with two popular frameworks, Megatron-LM (hybrid parallelism) and GPipe (originally proposed for model parallelism, but a version allowing hybrid parallelism also exists), for training models with increasingly greater numbers of parameters. In the pre-training of enlarged BERT models, RaNNC successfully trained models five times larger than those Megatron-LM could, and RaNNC's training throughputs were comparable to Megatron-LM's when pre-training the same models. RaNNC also achieved better training throughputs than GPipe on both the enlarged BERT model pre-training (GPipe with hybrid parallelism) and the enlarged ResNet models (GPipe with model parallelism) in all of the settings we tried. These results are remarkable, since RaNNC automatically partitions models without any modification to their descriptions; Megatron-LM and GPipe require users to manually rewrite the models' descriptions.