 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmplifAI: a Fine-grained Dataset for Japanese Empathetic Medical Dialogues in 28 Emotion Labels
Jan 15, 2026This paper introduces EmplifAI, a Japanese empathetic dialogue dataset designed to support patients coping with chronic medical conditions. They often experience a wide range of positive and negative emotions (e.g., hope and despair) that shift across different stages of disease management. EmplifAI addresses this complexity by providing situation-based dialogues grounded in 28 fine-grained emotion categories, adapted and validated from the GoEmotions taxonomy. The dataset includes 280 medically contextualized situations and 4125 two-turn dialogues, collected through crowdsourcing and expert review. To evaluate emotional alignment in empathetic dialogues, we assessed model predictions on situation--dialogue pairs using BERTScore across multiple large language models (LLMs), achieving F1 scores of 0.83. Fine-tuning a baseline Japanese LLM (LLM-jp-3.1-13b-instruct4) with EmplifAI resulted in notable improvements in fluency, general empathy, and emotion-specific empathy. Furthermore, we compared the scores assigned by LLM-as-a-Judge and human raters on dialogues generated by multiple LLMs to validate our evaluation pipeline and discuss the insights and potential risks derived from the correlation analysis.
Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors
Feb 27, 2025



This paper investigates how LLMs encode inputs with typos. We hypothesize that specific neurons and attention heads recognize typos and fix them internally using local and global contexts. We introduce a method to identify typo neurons and typo heads that work actively when inputs contain typos. Our experimental results suggest the following: 1) LLMs can fix typos with local contexts when the typo neurons in either the early or late layers are activated, even if those in the other are not. 2) Typo neurons in the middle layers are responsible for the core of typo-fixing with global contexts. 3) Typo heads fix typos by widely considering the context not focusing on specific tokens. 4) Typo neurons and typo heads work not only for typo-fixing but also for understanding general contexts.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Enhancing In-Context Learning with Semantic Representations for Relation Extraction
Jun 14, 2024

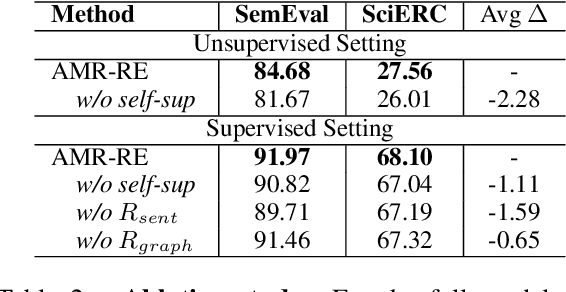
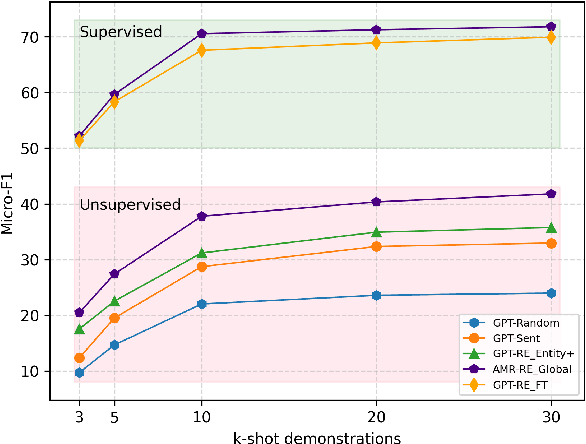
In this work, we employ two AMR-enhanced semantic representations for ICL on RE: one that explores the AMR structure generated for a sentence at the subgraph level (shortest AMR path), and another that explores the full AMR structure generated for a sentence. In both cases, we demonstrate that all settings benefit from the fine-grained AMR's semantic structure. We evaluate our model on four RE datasets. Our results show that our model can outperform the GPT-based baselines, and achieve SOTA performance on two of the datasets, and competitive performance on the other two.
A Dataset for Pharmacovigilance in German, French, and Japanese: Annotating Adverse Drug Reactions across Languages
Mar 27, 2024



User-generated data sources have gained significance in uncovering Adverse Drug Reactions (ADRs), with an increasing number of discussions occurring in the digital world. However, the existing clinical corpora predominantly revolve around scientific articles in English. This work presents a multilingual corpus of texts concerning ADRs gathered from diverse sources, including patient fora, social media, and clinical reports in German, French, and Japanese. Our corpus contains annotations covering 12 entity types, four attribute types, and 13 relation types. It contributes to the development of real-world multilingual language models for healthcare. We provide statistics to highlight certain challenges associated with the corpus and conduct preliminary experiments resulting in strong baselines for extracting entities and relations between these entities, both within and across languages.
Annotation-Scheme Reconstruction for "Fake News" and Japanese Fake News Dataset
Apr 06, 2022



Fake news provokes many societal problems; therefore, there has been extensive research on fake news detection tasks to counter it. Many fake news datasets were constructed as resources to facilitate this task. Contemporary research focuses almost exclusively on the factuality aspect of the news. However, this aspect alone is insufficient to explain "fake news," which is a complex phenomenon that involves a wide range of issues. To fully understand the nature of each instance of fake news, it is important to observe it from various perspectives, such as the intention of the false news disseminator, the harmfulness of the news to our society, and the target of the news. We propose a novel annotation scheme with fine-grained labeling based on detailed investigations of existing fake news datasets to capture these various aspects of fake news. Using the annotation scheme, we construct and publish the first Japanese fake news dataset. The annotation scheme is expected to provide an in-depth understanding of fake news. We plan to build datasets for both Japanese and other languages using our scheme. Our Japanese dataset is published at https://hkefka385.github.io/dataset/fakenews-japanese/.
JaMIE: A Pipeline Japanese Medical Information Extraction System
Nov 08, 2021

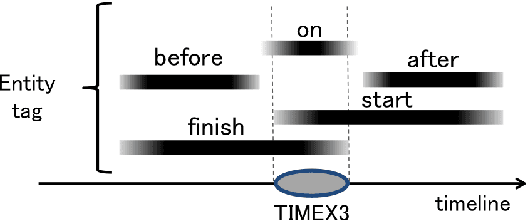
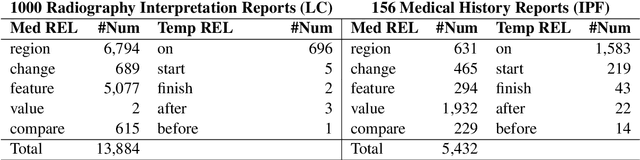
We present an open-access natural language processing toolkit for Japanese medical information extraction. We first propose a novel relation annotation schema for investigating the medical and temporal relations between medical entities in Japanese medical reports. We experiment with the practical annotation scenarios by separately annotating two different types of reports. We design a pipeline system with three components for recognizing medical entities, classifying entity modalities, and extracting relations. The empirical results show accurate analyzing performance and suggest the satisfactory annotation quality, the effective annotation strategy for targeting report types, and the superiority of the latest contextual embedding models.
Mitigation of Diachronic Bias in Fake News Detection Dataset
Aug 28, 2021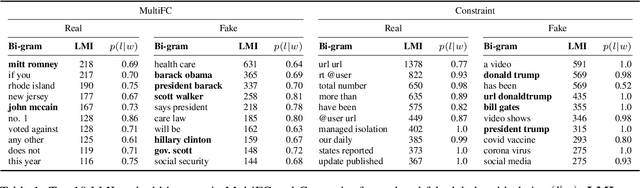
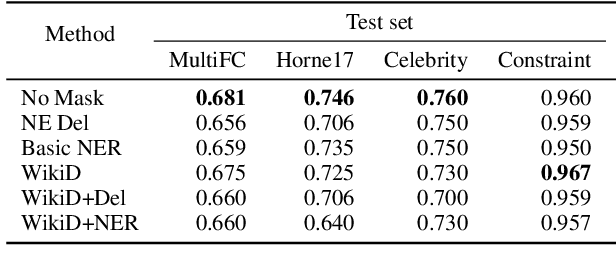
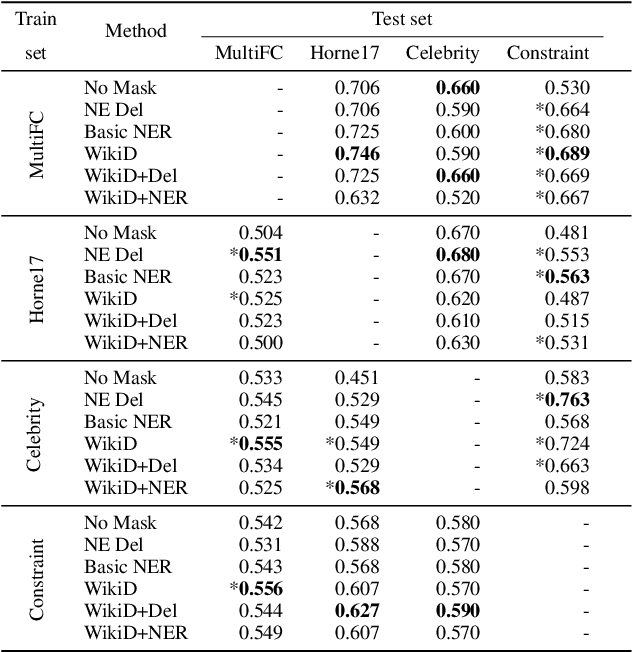
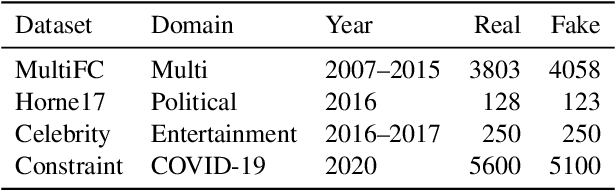
Fake news causes significant damage to society.To deal with these fake news, several studies on building detection models and arranging datasets have been conducted. Most of the fake news datasets depend on a specific time period. Consequently, the detection models trained on such a dataset have difficulty detecting novel fake news generated by political changes and social changes; they may possibly result in biased output from the input, including specific person names and organizational names. We refer to this problem as \textbf{Diachronic Bias} because it is caused by the creation date of news in each dataset. In this study, we confirm the bias, especially proper nouns including person names, from the deviation of phrase appearances in each dataset. Based on these findings, we propose masking methods using Wikidata to mitigate the influence of person names and validate whether they make fake news detection models robust through experiments with in-domain and out-of-domain data.
Single Model for Influenza Forecasting of Multiple Countries by Multi-task Learning
Jul 07, 2021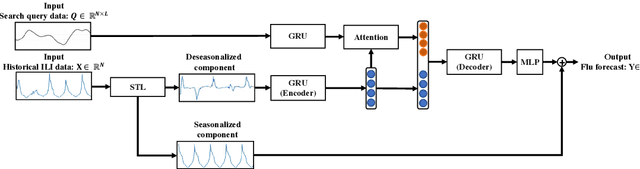
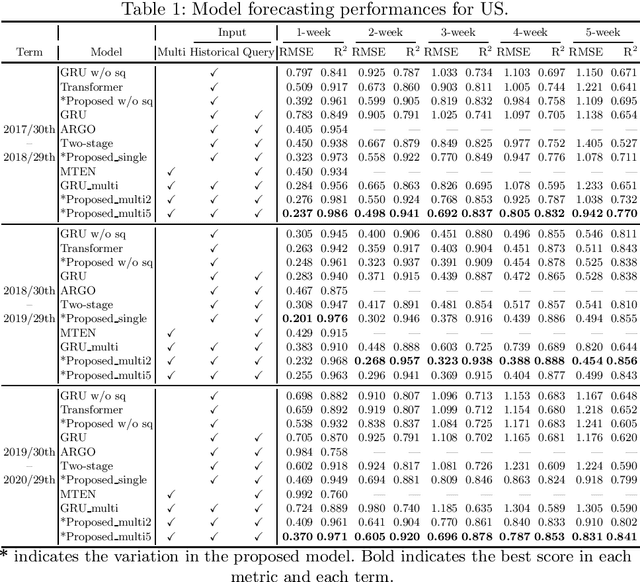
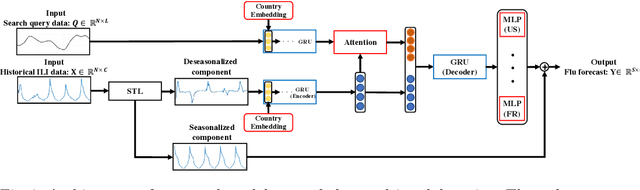
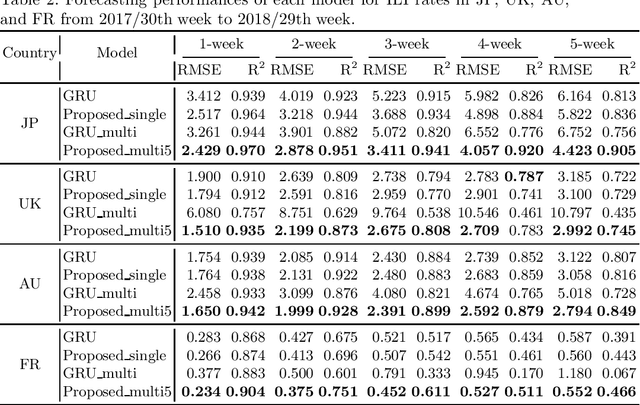
The accurate forecasting of infectious epidemic diseases such as influenza is a crucial task undertaken by medical institutions. Although numerous flu forecasting methods and models based mainly on historical flu activity data and online user-generated contents have been proposed in previous studies, no flu forecasting model targeting multiple countries using two types of data exists at present. Our paper leverages multi-task learning to tackle the challenge of building one flu forecasting model targeting multiple countries; each country as each task. Also, to develop the flu prediction model with higher performance, we solved two issues; finding suitable search queries, which are part of the user-generated contents, and how to leverage search queries efficiently in the model creation. For the first issue, we propose the transfer approaches from English to other languages. For the second issue, we propose a novel flu forecasting model that takes advantage of search queries using an attention mechanism and extend the model to a multi-task model for multiple countries' flu forecasts. Experiments on forecasting flu epidemics in five countries demonstrate that our model significantly improved the performance by leveraging the search queries and multi-task learning compared to the baselines.
Biomedical Entity Linking with Contrastive Context Matching
Jun 15, 2021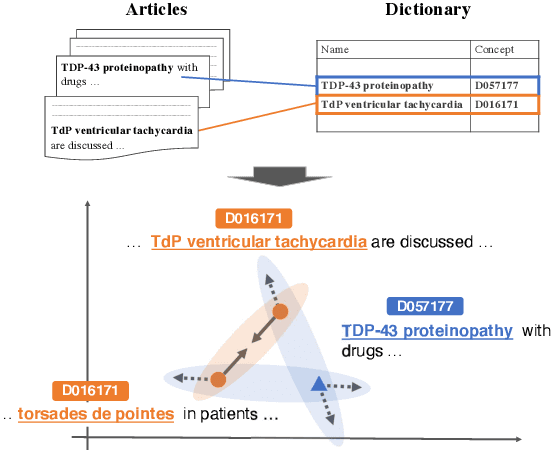

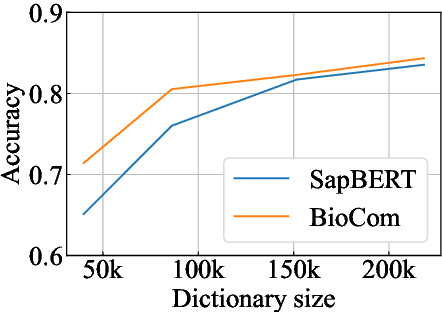
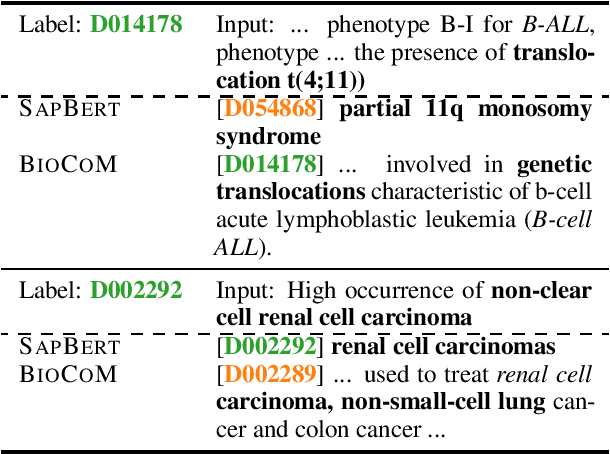
We introduce BioCoM, a contrastive learning framework for biomedical entity linking that uses only two resources: a small-sized dictionary and a large number of raw biomedical articles. Specifically, we build the training instances from raw PubMed articles by dictionary matching and use them to train a context-aware entity linking model with contrastive learning. We predict the normalized biomedical entity at inference time through a nearest-neighbor search. Results found that BioCoM substantially outperforms state-of-the-art models, especially in low-resource settings, by effectively using the context of the entities.