 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization, Emergence, and Explaining Reversal Failures: A Controlled Study of Relational Semantics in LLMs
Jan 06, 2026Autoregressive LLMs perform well on relational tasks that require linking entities via relational words (e.g., father/son, friend), but it is unclear whether they learn the logical semantics of such relations (e.g., symmetry and inversion logic) and, if so, whether reversal-type failures arise from missing relational semantics or left-to-right order bias. We propose a controlled Knowledge Graph-based synthetic framework that generates text from symmetric/inverse triples, train GPT-style autoregressive models from scratch, and evaluate memorization, logical inference, and in-context generalization to unseen entities to address these questions. We find a sharp phase transition in which relational semantics emerge with sufficient logic-bearing supervision, even in shallow (2-3 layer) models, and that successful generalization aligns with stable intermediate-layer signals. Finally, order-matched forward/reverse tests and a diffusion baseline indicate that reversal failures are primarily driven by autoregressive order bias rather than deficient inversion semantics.
Language Lives in Sparse Dimensions: Toward Interpretable and Efficient Multilingual Control for Large Language Models
Oct 08, 2025Large language models exhibit strong multilingual capabilities despite limited exposure to non-English data. Prior studies show that English-centric large language models map multilingual content into English-aligned representations at intermediate layers and then project them back into target-language token spaces in the final layer. From this observation, we hypothesize that this cross-lingual transition is governed by a small and sparse set of dimensions, which occur at consistent indices across the intermediate to final layers. Building on this insight, we introduce a simple, training-free method to identify and manipulate these dimensions, requiring only as few as 50 sentences of either parallel or monolingual data. Experiments on a multilingual generation control task reveal the interpretability of these dimensions, demonstrating that the interventions in these dimensions can switch the output language while preserving semantic content, and that it surpasses the performance of prior neuron-based approaches at a substantially lower cost.
BIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Jun 08, 2025We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
Causal Tree Extraction from Medical Case Reports: A Novel Task for Experts-like Text Comprehension
Mar 03, 2025Extracting causal relationships from a medical case report is essential for comprehending the case, particularly its diagnostic process. Since the diagnostic process is regarded as a bottom-up inference, causal relationships in cases naturally form a multi-layered tree structure. The existing tasks, such as medical relation extraction, are insufficient for capturing the causal relationships of an entire case, as they treat all relations equally without considering the hierarchical structure inherent in the diagnostic process. Thus, we propose a novel task, Causal Tree Extraction (CTE), which receives a case report and generates a causal tree with the primary disease as the root, providing an intuitive understanding of a case's diagnostic process. Subsequently, we construct a Japanese case report CTE dataset, J-Casemap, propose a generation-based CTE method that outperforms the baseline by 20.2 points in the human evaluation, and introduce evaluation metrics that reflect clinician preferences. Further experiments also show that J-Casemap enhances the performance of solving other medical tasks, such as question answering.
Assessing Large Language Models in Agentic Multilingual National Bias
Feb 25, 2025Large Language Models have garnered significant attention for their capabilities in multilingual natural language processing, while studies on risks associated with cross biases are limited to immediate context preferences. Cross-language disparities in reasoning-based recommendations remain largely unexplored, with a lack of even descriptive analysis. This study is the first to address this gap. We test LLM's applicability and capability in providing personalized advice across three key scenarios: university applications, travel, and relocation. We investigate multilingual bias in state-of-the-art LLMs by analyzing their responses to decision-making tasks across multiple languages. We quantify bias in model-generated scores and assess the impact of demographic factors and reasoning strategies (e.g., Chain-of-Thought prompting) on bias patterns. Our findings reveal that local language bias is prevalent across different tasks, with GPT-4 and Sonnet reducing bias for English-speaking countries compared to GPT-3.5 but failing to achieve robust multilingual alignment, highlighting broader implications for multilingual AI agents and applications such as education.
Beyond English-Centric LLMs: What Language Do Multilingual Language Models Think in?
Aug 20, 2024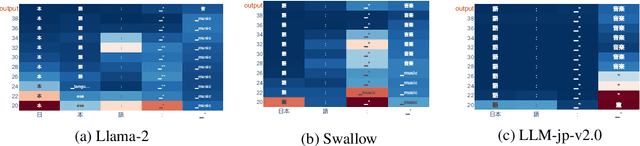

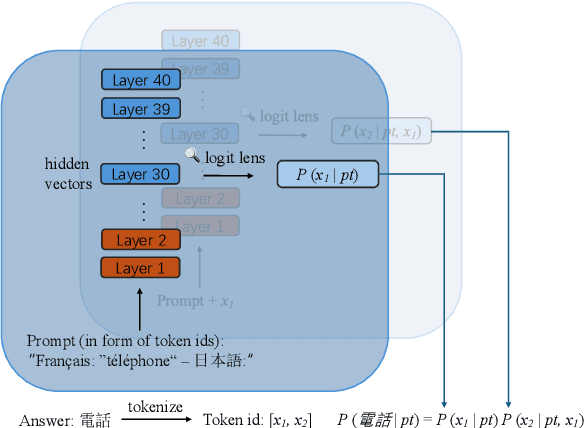
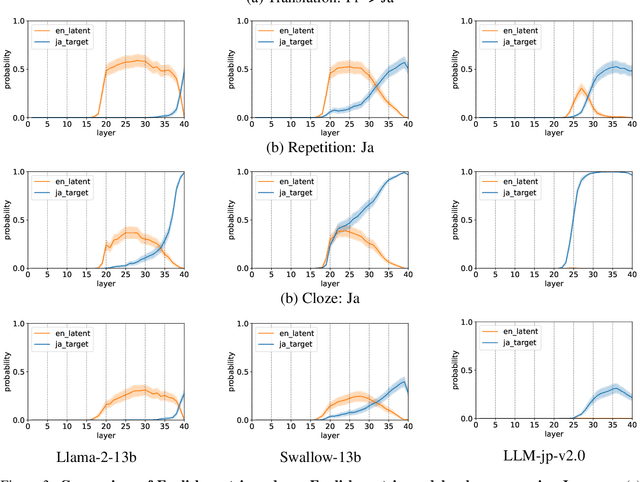
In this study, we investigate whether non-English-centric LLMs, despite their strong performance, `think' in their respective dominant language: more precisely, `think' refers to how the representations of intermediate layers, when un-embedded into the vocabulary space, exhibit higher probabilities for certain dominant languages during generation. We term such languages as internal $\textbf{latent languages}$. We examine the latent language of three typical categories of models for Japanese processing: Llama2, an English-centric model; Swallow, an English-centric model with continued pre-training in Japanese; and LLM-jp, a model pre-trained on balanced English and Japanese corpora. Our empirical findings reveal that, unlike Llama2 which relies exclusively on English as the internal latent language, Japanese-specific Swallow and LLM-jp employ both Japanese and English, exhibiting dual internal latent languages. For any given target language, the model preferentially activates the latent language most closely related to it. In addition, we explore how intermediate layers respond to questions involving cultural conflicts between latent internal and target output languages. We further explore how the language identity shifts across layers while keeping consistent semantic meaning reflected in the intermediate layer representations. This study deepens the understanding of non-English-centric large language models, highlighting the intricate dynamics of language representation within their intermediate layers.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
MELD-ST: An Emotion-aware Speech Translation Dataset
May 21, 2024Emotion plays a crucial role in human conversation. This paper underscores the significance of considering emotion in speech translation. We present the MELD-ST dataset for the emotion-aware speech translation task, comprising English-to-Japanese and English-to-German language pairs. Each language pair includes about 10,000 utterances annotated with emotion labels from the MELD dataset. Baseline experiments using the SeamlessM4T model on the dataset indicate that fine-tuning with emotion labels can enhance translation performance in some settings, highlighting the need for further research in emotion-aware speech translation systems.
J-CRe3: A Japanese Conversation Dataset for Real-world Reference Resolution
Mar 28, 2024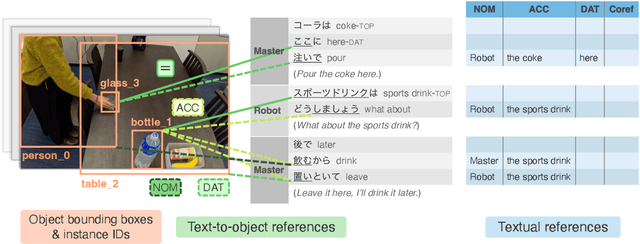
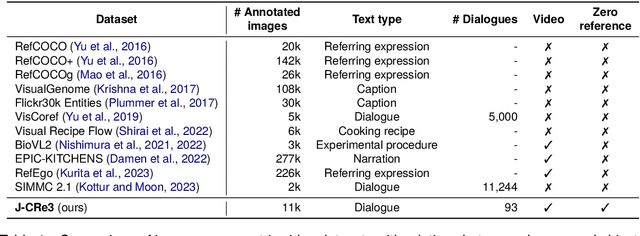

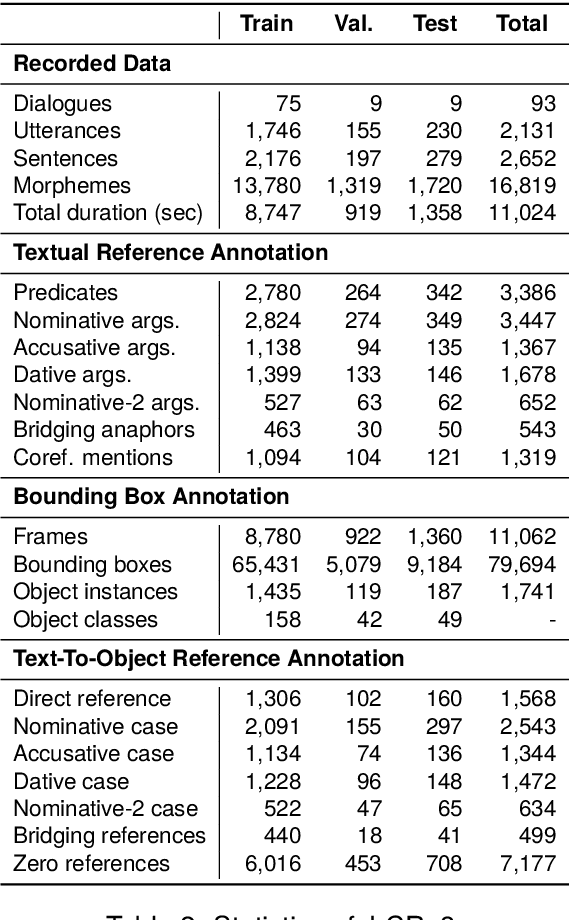
Understanding expressions that refer to the physical world is crucial for such human-assisting systems in the real world, as robots that must perform actions that are expected by users. In real-world reference resolution, a system must ground the verbal information that appears in user interactions to the visual information observed in egocentric views. To this end, we propose a multimodal reference resolution task and construct a Japanese Conversation dataset for Real-world Reference Resolution (J-CRe3). Our dataset contains egocentric video and dialogue audio of real-world conversations between two people acting as a master and an assistant robot at home. The dataset is annotated with crossmodal tags between phrases in the utterances and the object bounding boxes in the video frames. These tags include indirect reference relations, such as predicate-argument structures and bridging references as well as direct reference relations. We also constructed an experimental model and clarified the challenges in multimodal reference resolution tasks.
AcTED: Automatic Acquisition of Typical Event Duration for Semi-supervised Temporal Commonsense QA
Mar 27, 2024



We propose a voting-driven semi-supervised approach to automatically acquire the typical duration of an event and use it as pseudo-labeled data. The human evaluation demonstrates that our pseudo labels exhibit surprisingly high accuracy and balanced coverage. In the temporal commonsense QA task, experimental results show that using only pseudo examples of 400 events, we achieve performance comparable to the existing BERT-based weakly supervised approaches that require a significant amount of training examples. When compared to the RoBERTa baselines, our best approach establishes state-of-the-art performance with a 7% improvement in Exact Match.