 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmplifAI: a Fine-grained Dataset for Japanese Empathetic Medical Dialogues in 28 Emotion Labels
Jan 15, 2026This paper introduces EmplifAI, a Japanese empathetic dialogue dataset designed to support patients coping with chronic medical conditions. They often experience a wide range of positive and negative emotions (e.g., hope and despair) that shift across different stages of disease management. EmplifAI addresses this complexity by providing situation-based dialogues grounded in 28 fine-grained emotion categories, adapted and validated from the GoEmotions taxonomy. The dataset includes 280 medically contextualized situations and 4125 two-turn dialogues, collected through crowdsourcing and expert review. To evaluate emotional alignment in empathetic dialogues, we assessed model predictions on situation--dialogue pairs using BERTScore across multiple large language models (LLMs), achieving F1 scores of 0.83. Fine-tuning a baseline Japanese LLM (LLM-jp-3.1-13b-instruct4) with EmplifAI resulted in notable improvements in fluency, general empathy, and emotion-specific empathy. Furthermore, we compared the scores assigned by LLM-as-a-Judge and human raters on dialogues generated by multiple LLMs to validate our evaluation pipeline and discuss the insights and potential risks derived from the correlation analysis.
Which Way Does Time Flow? A Psychophysics-Grounded Evaluation for Vision-Language Models
Oct 30, 2025Modern vision-language models (VLMs) excel at many multimodal tasks, yet their grasp of temporal information in video remains weak and, crucially, under-evaluated. We probe this gap with a deceptively simple but revealing challenge: judging the arrow of time (AoT)-whether a short clip is played forward or backward. We introduce AoT-PsyPhyBENCH, a psychophysically validated benchmark that tests whether VLMs can infer temporal direction in natural videos using the same stimuli and behavioral baselines established for humans. Our comprehensive evaluation of open-weight and proprietary, reasoning and non-reasoning VLMs reveals that most models perform near chance, and even the best lag far behind human accuracy on physically irreversible processes (e.g., free fall, diffusion/explosion) and causal manual actions (division/addition) that humans recognize almost instantly. These results highlight a fundamental gap in current multimodal systems: while they capture rich visual-semantic correlations, they lack the inductive biases required for temporal continuity and causal understanding. We release the code and data for AoT-PsyPhyBENCH to encourage further progress in the physical and temporal reasoning capabilities of VLMs.
Enhancing In-Context Learning with Semantic Representations for Relation Extraction
Jun 14, 2024

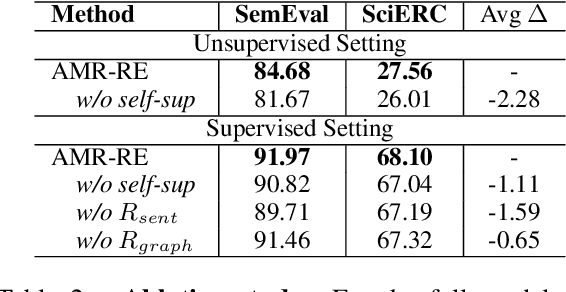
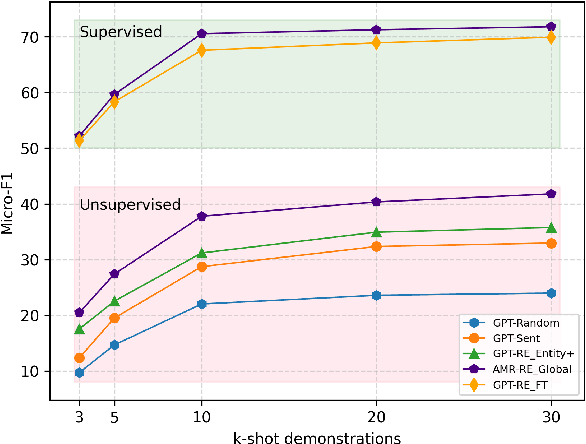
In this work, we employ two AMR-enhanced semantic representations for ICL on RE: one that explores the AMR structure generated for a sentence at the subgraph level (shortest AMR path), and another that explores the full AMR structure generated for a sentence. In both cases, we demonstrate that all settings benefit from the fine-grained AMR's semantic structure. We evaluate our model on four RE datasets. Our results show that our model can outperform the GPT-based baselines, and achieve SOTA performance on two of the datasets, and competitive performance on the other two.
AcTED: Automatic Acquisition of Typical Event Duration for Semi-supervised Temporal Commonsense QA
Mar 27, 2024



We propose a voting-driven semi-supervised approach to automatically acquire the typical duration of an event and use it as pseudo-labeled data. The human evaluation demonstrates that our pseudo labels exhibit surprisingly high accuracy and balanced coverage. In the temporal commonsense QA task, experimental results show that using only pseudo examples of 400 events, we achieve performance comparable to the existing BERT-based weakly supervised approaches that require a significant amount of training examples. When compared to the RoBERTa baselines, our best approach establishes state-of-the-art performance with a 7% improvement in Exact Match.
OCHADAI at SemEval-2022 Task 2: Adversarial Training for Multilingual Idiomaticity Detection
Jun 07, 2022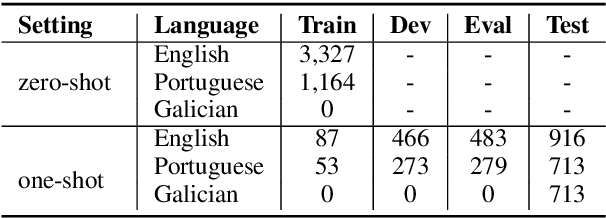

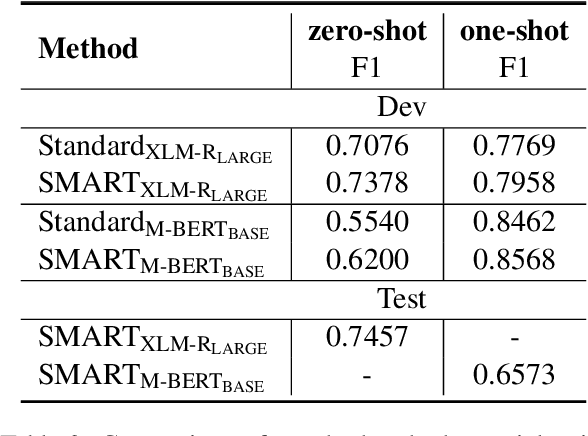
We propose a multilingual adversarial training model for determining whether a sentence contains an idiomatic expression. Given that a key challenge with this task is the limited size of annotated data, our model relies on pre-trained contextual representations from different multi-lingual state-of-the-art transformer-based language models (i.e., multilingual BERT and XLM-RoBERTa), and on adversarial training, a training method for further enhancing model generalization and robustness. Without relying on any human-crafted features, knowledge bases, or additional datasets other than the target datasets, our model achieved competitive results and ranked 6th place in SubTask A (zero-shot) setting and 15th place in SubTask A (one-shot) setting.
* arXiv admin note: substantial text overlap with arXiv:2105.05535
OCHADAI-KYODAI at SemEval-2021 Task 1: Enhancing Model Generalization and Robustness for Lexical Complexity Prediction
May 13, 2021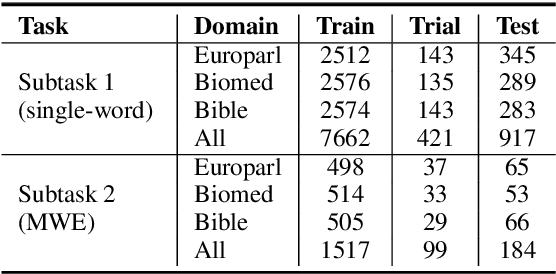
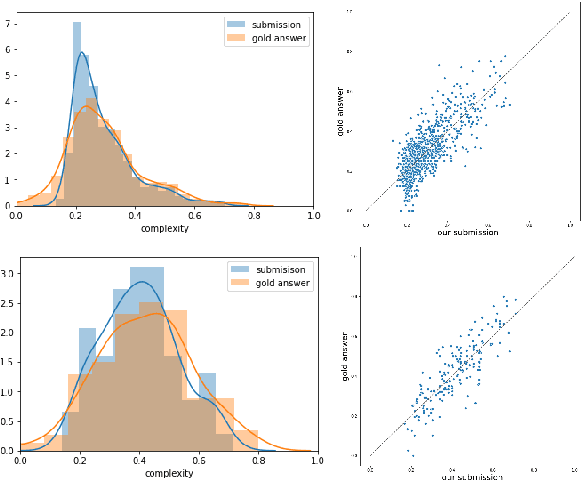

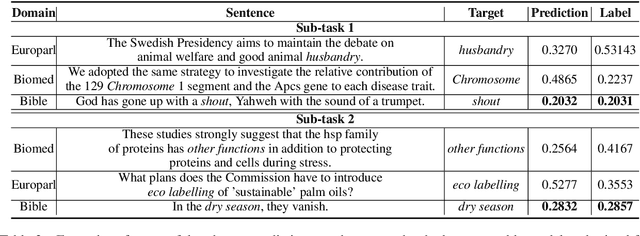
We propose an ensemble model for predicting the lexical complexity of words and multiword expressions (MWEs). The model receives as input a sentence with a target word or MWEand outputs its complexity score. Given that a key challenge with this task is the limited size of annotated data, our model relies on pretrained contextual representations from different state-of-the-art transformer-based language models (i.e., BERT and RoBERTa), and on a variety of training methods for further enhancing model generalization and robustness:multi-step fine-tuning and multi-task learning, and adversarial training. Additionally, we propose to enrich contextual representations by adding hand-crafted features during training. Our model achieved competitive results and ranked among the top-10 systems in both sub-tasks.