 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmplifAI: a Fine-grained Dataset for Japanese Empathetic Medical Dialogues in 28 Emotion Labels
Jan 15, 2026This paper introduces EmplifAI, a Japanese empathetic dialogue dataset designed to support patients coping with chronic medical conditions. They often experience a wide range of positive and negative emotions (e.g., hope and despair) that shift across different stages of disease management. EmplifAI addresses this complexity by providing situation-based dialogues grounded in 28 fine-grained emotion categories, adapted and validated from the GoEmotions taxonomy. The dataset includes 280 medically contextualized situations and 4125 two-turn dialogues, collected through crowdsourcing and expert review. To evaluate emotional alignment in empathetic dialogues, we assessed model predictions on situation--dialogue pairs using BERTScore across multiple large language models (LLMs), achieving F1 scores of 0.83. Fine-tuning a baseline Japanese LLM (LLM-jp-3.1-13b-instruct4) with EmplifAI resulted in notable improvements in fluency, general empathy, and emotion-specific empathy. Furthermore, we compared the scores assigned by LLM-as-a-Judge and human raters on dialogues generated by multiple LLMs to validate our evaluation pipeline and discuss the insights and potential risks derived from the correlation analysis.
Enhancing In-Context Learning with Semantic Representations for Relation Extraction
Jun 14, 2024

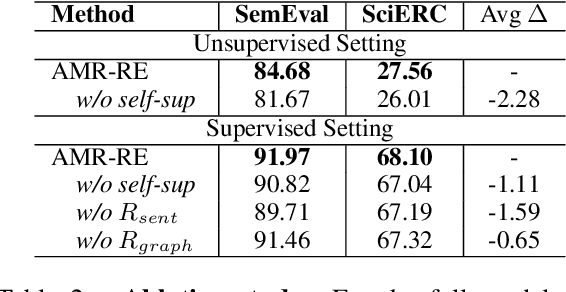
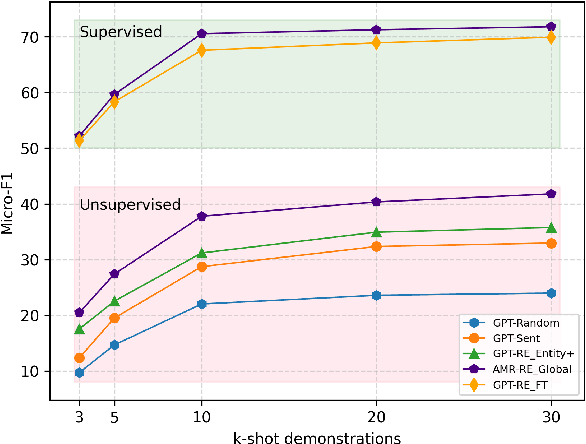
In this work, we employ two AMR-enhanced semantic representations for ICL on RE: one that explores the AMR structure generated for a sentence at the subgraph level (shortest AMR path), and another that explores the full AMR structure generated for a sentence. In both cases, we demonstrate that all settings benefit from the fine-grained AMR's semantic structure. We evaluate our model on four RE datasets. Our results show that our model can outperform the GPT-based baselines, and achieve SOTA performance on two of the datasets, and competitive performance on the other two.