 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmplifAI: a Fine-grained Dataset for Japanese Empathetic Medical Dialogues in 28 Emotion Labels
Jan 15, 2026This paper introduces EmplifAI, a Japanese empathetic dialogue dataset designed to support patients coping with chronic medical conditions. They often experience a wide range of positive and negative emotions (e.g., hope and despair) that shift across different stages of disease management. EmplifAI addresses this complexity by providing situation-based dialogues grounded in 28 fine-grained emotion categories, adapted and validated from the GoEmotions taxonomy. The dataset includes 280 medically contextualized situations and 4125 two-turn dialogues, collected through crowdsourcing and expert review. To evaluate emotional alignment in empathetic dialogues, we assessed model predictions on situation--dialogue pairs using BERTScore across multiple large language models (LLMs), achieving F1 scores of 0.83. Fine-tuning a baseline Japanese LLM (LLM-jp-3.1-13b-instruct4) with EmplifAI resulted in notable improvements in fluency, general empathy, and emotion-specific empathy. Furthermore, we compared the scores assigned by LLM-as-a-Judge and human raters on dialogues generated by multiple LLMs to validate our evaluation pipeline and discuss the insights and potential risks derived from the correlation analysis.
Causal Tree Extraction from Medical Case Reports: A Novel Task for Experts-like Text Comprehension
Mar 03, 2025Extracting causal relationships from a medical case report is essential for comprehending the case, particularly its diagnostic process. Since the diagnostic process is regarded as a bottom-up inference, causal relationships in cases naturally form a multi-layered tree structure. The existing tasks, such as medical relation extraction, are insufficient for capturing the causal relationships of an entire case, as they treat all relations equally without considering the hierarchical structure inherent in the diagnostic process. Thus, we propose a novel task, Causal Tree Extraction (CTE), which receives a case report and generates a causal tree with the primary disease as the root, providing an intuitive understanding of a case's diagnostic process. Subsequently, we construct a Japanese case report CTE dataset, J-Casemap, propose a generation-based CTE method that outperforms the baseline by 20.2 points in the human evaluation, and introduce evaluation metrics that reflect clinician preferences. Further experiments also show that J-Casemap enhances the performance of solving other medical tasks, such as question answering.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
MELD-ST: An Emotion-aware Speech Translation Dataset
May 21, 2024Emotion plays a crucial role in human conversation. This paper underscores the significance of considering emotion in speech translation. We present the MELD-ST dataset for the emotion-aware speech translation task, comprising English-to-Japanese and English-to-German language pairs. Each language pair includes about 10,000 utterances annotated with emotion labels from the MELD dataset. Baseline experiments using the SeamlessM4T model on the dataset indicate that fine-tuning with emotion labels can enhance translation performance in some settings, highlighting the need for further research in emotion-aware speech translation systems.
Rapidly Developing High-quality Instruction Data and Evaluation Benchmark for Large Language Models with Minimal Human Effort: A Case Study on Japanese
Mar 06, 2024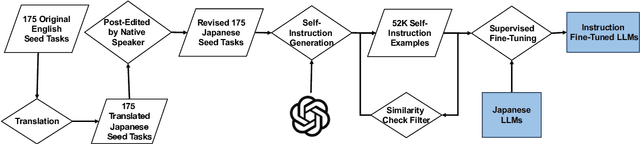
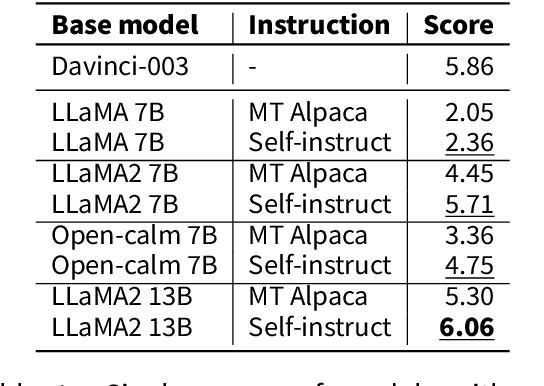
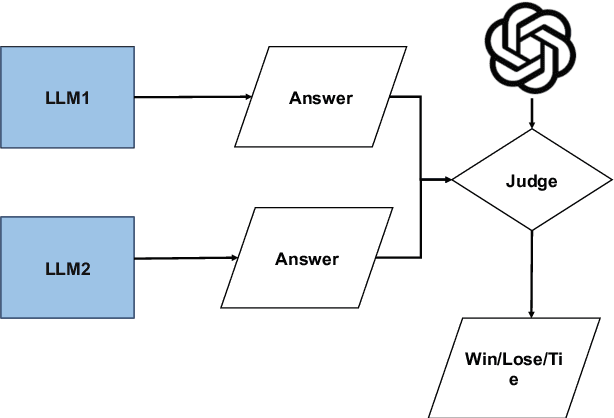

The creation of instruction data and evaluation benchmarks for serving Large language models often involves enormous human annotation. This issue becomes particularly pronounced when rapidly developing such resources for a non-English language like Japanese. Instead of following the popular practice of directly translating existing English resources into Japanese (e.g., Japanese-Alpaca), we propose an efficient self-instruct method based on GPT-4. We first translate a small amount of English instructions into Japanese and post-edit them to obtain native-level quality. GPT-4 then utilizes them as demonstrations to automatically generate Japanese instruction data. We also construct an evaluation benchmark containing 80 questions across 8 categories, using GPT-4 to automatically assess the response quality of LLMs without human references. The empirical results suggest that the models fine-tuned on our GPT-4 self-instruct data significantly outperformed the Japanese-Alpaca across all three base pre-trained models. Our GPT-4 self-instruct data allowed the LLaMA 13B model to defeat GPT-3.5 (Davinci-003) with a 54.37\% win-rate. The human evaluation exhibits the consistency between GPT-4's assessments and human preference. Our high-quality instruction data and evaluation benchmark have been released here.