 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Prompt Sensitivity
Apr 20, 2026Prompt sensitivity, which refers to how strongly the output of a large language model (LLM) depends on the exact wording of its input prompt, raises concerns among users about the LLM's stability and reliability. In this work, we consider LLMs as multivariate functions and perform a first-order Taylor expansion, thereby analyzing the relationship between meaning-preserving prompts, their gradients, and the log probabilities of the model's next token. We derive an upper bound on the difference between log probabilities using the Cauchy-Schwarz inequality. We show that LLMs do not internally cluster similar inputs like smaller neural networks do, but instead disperse them. This dispersing behavior leads to an excessively high upper bound on the difference of log probabilities between two meaning-preserving prompts, making it difficult to effectively reduce to 0. In our analysis, we also show which types of meaning-preserving prompt variants are more likely to introduce prompt sensitivity risks in LLMs. In addition, we demonstrate that the upper bound is strongly correlated with an existing prompt sensitivity metric, PromptSensiScore. Moreover, by analyzing the logit variance, we find that prompt templates typically exert a greater influence on logits than the questions themselves. Overall, our results provide a general interpretation for why current LLMs can be highly sensitive to prompts with the same meaning, offering crucial evidence for understanding the prompt sensitivity of LLMs. Code for experiments is available at https://github.com/ku-nlp/Understanding_the_Prompt_Sensitivity.
When and Why Does Unsupervised RL Succeed in Mathematical Reasoning? A Manifold Envelopment Perspective
Mar 17, 2026Although outcome-based reinforcement learning (RL) significantly advances the mathematical reasoning capabilities of Large Language Models (LLMs), its reliance on computationally expensive ground-truth annotations imposes a severe scalability bottleneck. Unsupervised RL guided by intrinsic rewards offers a scalable alternative, yet it suffers from opaque training dynamics and catastrophic instability, such as policy collapse and reward hacking. In this paper, we first design and evaluate a suite of intrinsic rewards that explicitly enforce concise and certain generation. Second, to discover the boundaries of this approach, we test base models across a spectrum of intrinsic reasoning capabilities, revealing how a model's foundational logical prior dictates its success or failure. Finally, to demystify why certain configurations stabilize while others collapse, we introduce a novel geometric diagnostic lens, showing that successful cases are enveloped by manifolds. Ultimately, our work goes beyond merely demonstrating that enforcing concise and certain responses successfully boosts mathematical reasoning; we reveal when this unsupervised approach breaks down and geometrically diagnose why.
Speech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
Guiding Perception-Reasoning Closer to Human in Blind Image Quality Assessment
Dec 18, 2025Humans assess image quality through a perception-reasoning cascade, integrating sensory cues with implicit reasoning to form self-consistent judgments. In this work, we investigate how a model can acquire both human-like and self-consistent reasoning capability for blind image quality assessment (BIQA). We first collect human evaluation data that capture several aspects of human perception-reasoning pipeline. Then, we adopt reinforcement learning, using human annotations as reward signals to guide the model toward human-like perception and reasoning. To enable the model to internalize self-consistent reasoning capability, we design a reward that drives the model to infer the image quality purely from self-generated descriptions. Empirically, our approach achieves score prediction performance comparable to state-of-the-art BIQA systems under general metrics, including Pearson and Spearman correlation coefficients. In addition to the rating score, we assess human-model alignment using ROUGE-1 to measure the similarity between model-generated and human perception-reasoning chains. On over 1,000 human-annotated samples, our model reaches a ROUGE-1 score of 0.512 (cf. 0.443 for baseline), indicating substantial coverage of human explanations and marking a step toward human-like interpretable reasoning in BIQA.
Language Lives in Sparse Dimensions: Toward Interpretable and Efficient Multilingual Control for Large Language Models
Oct 08, 2025Large language models exhibit strong multilingual capabilities despite limited exposure to non-English data. Prior studies show that English-centric large language models map multilingual content into English-aligned representations at intermediate layers and then project them back into target-language token spaces in the final layer. From this observation, we hypothesize that this cross-lingual transition is governed by a small and sparse set of dimensions, which occur at consistent indices across the intermediate to final layers. Building on this insight, we introduce a simple, training-free method to identify and manipulate these dimensions, requiring only as few as 50 sentences of either parallel or monolingual data. Experiments on a multilingual generation control task reveal the interpretability of these dimensions, demonstrating that the interventions in these dimensions can switch the output language while preserving semantic content, and that it surpasses the performance of prior neuron-based approaches at a substantially lower cost.
Do LLMs Align Human Values Regarding Social Biases? Judging and Explaining Social Biases with LLMs
Sep 17, 2025Large language models (LLMs) can lead to undesired consequences when misaligned with human values, especially in scenarios involving complex and sensitive social biases. Previous studies have revealed the misalignment of LLMs with human values using expert-designed or agent-based emulated bias scenarios. However, it remains unclear whether the alignment of LLMs with human values differs across different types of scenarios (e.g., scenarios containing negative vs. non-negative questions). In this study, we investigate the alignment of LLMs with human values regarding social biases (HVSB) in different types of bias scenarios. Through extensive analysis of 12 LLMs from four model families and four datasets, we demonstrate that LLMs with large model parameter scales do not necessarily have lower misalignment rate and attack success rate. Moreover, LLMs show a certain degree of alignment preference for specific types of scenarios and the LLMs from the same model family tend to have higher judgment consistency. In addition, we study the understanding capacity of LLMs with their explanations of HVSB. We find no significant differences in the understanding of HVSB across LLMs. We also find LLMs prefer their own generated explanations. Additionally, we endow smaller language models (LMs) with the ability to explain HVSB. The generation results show that the explanations generated by the fine-tuned smaller LMs are more readable, but have a relatively lower model agreeability.
How Does Cognitive Bias Affect Large Language Models? A Case Study on the Anchoring Effect in Price Negotiation Simulations
Aug 28, 2025Cognitive biases, well-studied in humans, can also be observed in LLMs, affecting their reliability in real-world applications. This paper investigates the anchoring effect in LLM-driven price negotiations. To this end, we instructed seller LLM agents to apply the anchoring effect and evaluated negotiations using not only an objective metric but also a subjective metric. Experimental results show that LLMs are influenced by the anchoring effect like humans. Additionally, we investigated the relationship between the anchoring effect and factors such as reasoning and personality. It was shown that reasoning models are less prone to the anchoring effect, suggesting that the long chain of thought mitigates the effect. However, we found no significant correlation between personality traits and susceptibility to the anchoring effect. These findings contribute to a deeper understanding of cognitive biases in LLMs and to the realization of safe and responsible application of LLMs in society.
Bridging Speech Emotion Recognition and Personality: Dataset and Temporal Interaction Condition Network
May 20, 2025This study investigates the interaction between personality traits and emotional expression, exploring how personality information can improve speech emotion recognition (SER). We collected personality annotation for the IEMOCAP dataset, and the statistical analysis identified significant correlations between personality traits and emotional expressions. To extract finegrained personality features, we propose a temporal interaction condition network (TICN), in which personality features are integrated with Hubert-based acoustic features for SER. Experiments show that incorporating ground-truth personality traits significantly enhances valence recognition, improving the concordance correlation coefficient (CCC) from 0.698 to 0.785 compared to the baseline without personality information. For practical applications in dialogue systems where personality information about the user is unavailable, we develop a front-end module of automatic personality recognition. Using these automatically predicted traits as inputs to our proposed TICN model, we achieve a CCC of 0.776 for valence recognition, representing an 11.17% relative improvement over the baseline. These findings confirm the effectiveness of personality-aware SER and provide a solid foundation for further exploration in personality-aware speech processing applications.
When Large Language Models Meet Speech: A Survey on Integration Approaches
Feb 26, 2025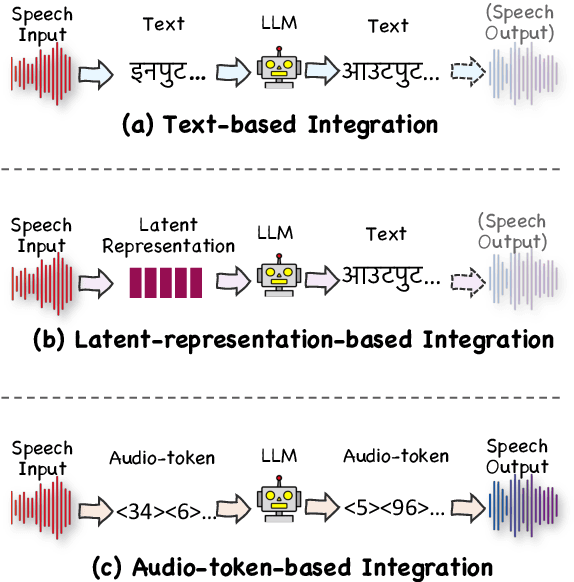
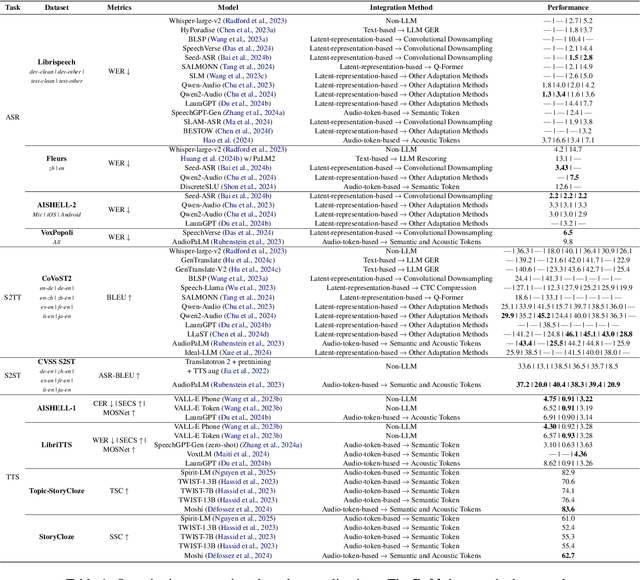
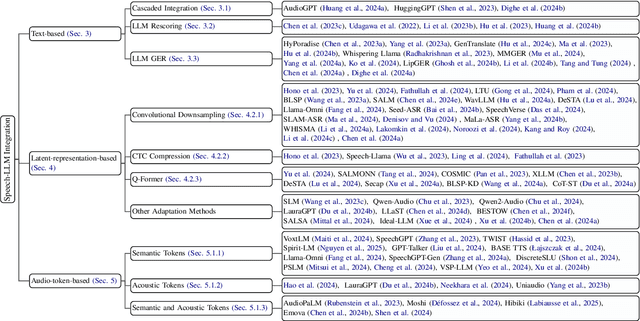
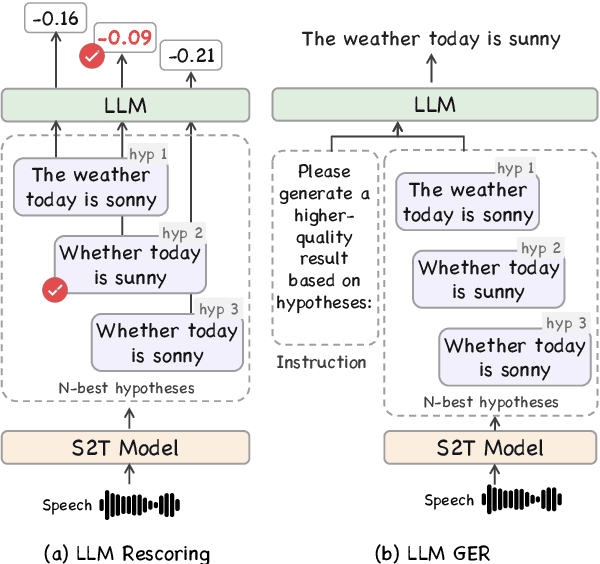
Recent advancements in large language models (LLMs) have spurred interest in expanding their application beyond text-based tasks. A large number of studies have explored integrating other modalities with LLMs, notably speech modality, which is naturally related to text. This paper surveys the integration of speech with LLMs, categorizing the methodologies into three primary approaches: text-based, latent-representation-based, and audio-token-based integration. We also demonstrate how these methods are applied across various speech-related applications and highlight the challenges in this field to offer inspiration for
Cross-lingual Embedding Clustering for Hierarchical Softmax in Low-Resource Multilingual Speech Recognition
Jan 29, 2025



We present a novel approach centered on the decoding stage of Automatic Speech Recognition (ASR) that enhances multilingual performance, especially for low-resource languages. It utilizes a cross-lingual embedding clustering method to construct a hierarchical Softmax (H-Softmax) decoder, which enables similar tokens across different languages to share similar decoder representations. It addresses the limitations of the previous Huffman-based H-Softmax method, which relied on shallow features in token similarity assessments. Through experiments on a downsampled dataset of 15 languages, we demonstrate the effectiveness of our approach in improving low-resource multilingual ASR accuracy.