 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Diagnostics of Spatial Lexical Bias in Multimodal Large Language Model Spatial Reasoning
Jun 01, 2026Multimodal large language models (MLLMs) remain unreliable on spatial multiple-choice questions, and their failures are often attributed to poorly attended visual information. In this work, we identify a complementary failure mode, spatial lexical bias: adding a spatial relation word to the answer options can attract the model's decision and make the newly added option likely to be selected. Using nine open-weight MLLMs, we show that this phenomenon is widely observed. In particular, models can answer a binary spatial question correctly, yet consistently select an incorrect third spatial option once it is added to the answer set. We isolate such binary-stable but ternary-fragile cases as diagnostic examples and leverage mechanistic interpretability tools, revealing that a substantial part of the failure instead originates on the language side rather than the visual side: visual attention analyses and residual-stream probes show the correct spatial relation remains internally available on these failures, while irrelevant-option controls, activation patching, and sparse component interventions trace the bias to specific LLM-side channels and neurons. Based on this finding, we show that a lightweight LLM-only DPO update on tiny single-object-pair synthetic data mitigates the bias, lifting four-way robust accuracy by up to 100 points on synthetic data, and by 68.0, 32.6, and 20.1 points on broader evaluation datasets WhatsUp, SpatialMQA-Direct, and VSR.
Reasoning Depth and Environment Complexity: A Controlled Study of RLVR Data Allocation across Logical Reasoning Tasks
May 26, 2026Reinforcement learning with verifiable rewards (RLVR) has become central to post-training reasoning models, yet a key limitation of existing studies is their narrow view of the reasoning space: difficulty is treated as reasoning depth alone, and reward is concentrated on forward deductive state tracking. We instead characterize the reasoning space along two dimensions. Difficulty. Beyond reasoning depth, we study environment complexity, where models must identify the correct path amid distractors and interacting structures. Rewarded reasoning form. We consider four abilities core to real-world reasoning: deductive state tracking, abductive recovery of hidden events or facts, inductive rule induction, and analogical transfer. To disentangle these factors, we construct a synthetic knowledge-graph environment with controlled pre- and post-training distributions, where each instance varies along depth, complexity, and task family. Three findings emerge: joint depth-complexity coverage outperforms single-axis recipes; reasoning families respond non-uniformly, with abductive reasoning degrading outside the RL-covered region and task correlations clustering into deductive-abductive and inductive-analogy pairs; and uniform mixing outperforms staged curricula under a fixed budget. We also find that recent off-the-shelf models exhibit the same deductive-over-abductive asymmetry, suggesting that this gap is not merely an artifact of our controlled setup.
ShapleyLaw: A Game-Theoretic Approach to Multilingual Scaling Laws
Mar 18, 2026In multilingual pretraining, the test loss of a pretrained model is heavily influenced by the proportion of each language in the pretraining data, namely the \textit{language mixture ratios}. Multilingual scaling laws can predict the test loss under different language mixture ratios and can therefore be used to estimate the optimal ratios. However, the current approaches to multilingual scaling laws do not measure the \textit{cross-lingual transfer} effect, resulting in suboptimal mixture ratios. In this paper, we consider multilingual pretraining as a cooperative game in which each language acts as a player that jointly contributes to pretraining, gaining the resulting reduction in test loss as the payoff. Consequently, from the perspective of cooperative game theory, we quantify the cross-lingual transfer from each language by its contribution in the game, and propose a game-theoretic multilingual scaling law called \textit{ShapleyLaw}. Our experiments show that ShapleyLaw outperforms baseline methods in model performance prediction and language mixture optimization.
Memorization, Emergence, and Explaining Reversal Failures: A Controlled Study of Relational Semantics in LLMs
Jan 06, 2026Autoregressive LLMs perform well on relational tasks that require linking entities via relational words (e.g., father/son, friend), but it is unclear whether they learn the logical semantics of such relations (e.g., symmetry and inversion logic) and, if so, whether reversal-type failures arise from missing relational semantics or left-to-right order bias. We propose a controlled Knowledge Graph-based synthetic framework that generates text from symmetric/inverse triples, train GPT-style autoregressive models from scratch, and evaluate memorization, logical inference, and in-context generalization to unseen entities to address these questions. We find a sharp phase transition in which relational semantics emerge with sufficient logic-bearing supervision, even in shallow (2-3 layer) models, and that successful generalization aligns with stable intermediate-layer signals. Finally, order-matched forward/reverse tests and a diffusion baseline indicate that reversal failures are primarily driven by autoregressive order bias rather than deficient inversion semantics.
A Convolutional Neural Deferred Shader for Physics Based Rendering
Dec 22, 2025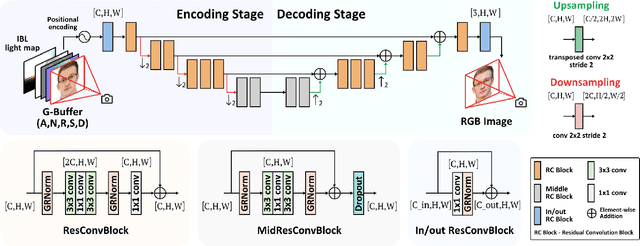
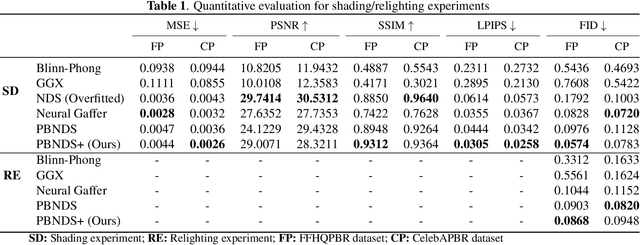


Recent advances in neural rendering have achieved impressive results on photorealistic shading and relighting, by using a multilayer perceptron (MLP) as a regression model to learn the rendering equation from a real-world dataset. Such methods show promise for photorealistically relighting real-world objects, which is difficult to classical rendering, as there is no easy-obtained material ground truth. However, significant challenges still remain the dense connections in MLPs result in a large number of parameters, which requires high computation resources, complicating the training, and reducing performance during rendering. Data driven approaches require large amounts of training data for generalization; unbalanced data might bias the model to ignore the unusual illumination conditions, e.g. dark scenes. This paper introduces pbnds+: a novel physics-based neural deferred shading pipeline utilizing convolution neural networks to decrease the parameters and improve the performance in shading and relighting tasks; Energy regularization is also proposed to restrict the model reflection during dark illumination. Extensive experiments demonstrate that our approach outperforms classical baselines, a state-of-the-art neural shading model, and a diffusion-based method.
Language Lives in Sparse Dimensions: Toward Interpretable and Efficient Multilingual Control for Large Language Models
Oct 08, 2025Large language models exhibit strong multilingual capabilities despite limited exposure to non-English data. Prior studies show that English-centric large language models map multilingual content into English-aligned representations at intermediate layers and then project them back into target-language token spaces in the final layer. From this observation, we hypothesize that this cross-lingual transition is governed by a small and sparse set of dimensions, which occur at consistent indices across the intermediate to final layers. Building on this insight, we introduce a simple, training-free method to identify and manipulate these dimensions, requiring only as few as 50 sentences of either parallel or monolingual data. Experiments on a multilingual generation control task reveal the interpretability of these dimensions, demonstrating that the interventions in these dimensions can switch the output language while preserving semantic content, and that it surpasses the performance of prior neuron-based approaches at a substantially lower cost.
Credit Risk Analysis for SMEs Using Graph Neural Networks in Supply Chain
Jul 10, 2025Small and Medium-sized Enterprises (SMEs) are vital to the modern economy, yet their credit risk analysis often struggles with scarce data, especially for online lenders lacking direct credit records. This paper introduces a Graph Neural Network (GNN)-based framework, leveraging SME interactions from transaction and social data to map spatial dependencies and predict loan default risks. Tests on real-world datasets from Discover and Ant Credit (23.4M nodes for supply chain analysis, 8.6M for default prediction) show the GNN surpasses traditional and other GNN baselines, with AUCs of 0.995 and 0.701 for supply chain mining and default prediction, respectively. It also helps regulators model supply chain disruption impacts on banks, accurately forecasting loan defaults from material shortages, and offers Federal Reserve stress testers key data for CCAR risk buffers. This approach provides a scalable, effective tool for assessing SME credit risk.
BIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Jun 08, 2025We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
Beyond Chains: Bridging Large Language Models and Knowledge Bases in Complex Question Answering
May 20, 2025Knowledge Base Question Answering (KBQA) aims to answer natural language questions using structured knowledge from KBs. While LLM-only approaches offer generalization, they suffer from outdated knowledge, hallucinations, and lack of transparency. Chain-based KG-RAG methods address these issues by incorporating external KBs, but are limited to simple chain-structured questions due to the absence of planning and logical structuring. Inspired by semantic parsing methods, we propose PDRR: a four-stage framework consisting of Predict, Decompose, Retrieve, and Reason. Our method first predicts the question type and decomposes the question into structured triples. Then retrieves relevant information from KBs and guides the LLM as an agent to reason over and complete the decomposed triples. Experimental results demonstrate that PDRR consistently outperforms existing methods across various LLM backbones and achieves superior performance on both chain-structured and non-chain complex questions.
Assessing Large Language Models in Agentic Multilingual National Bias
Feb 25, 2025Large Language Models have garnered significant attention for their capabilities in multilingual natural language processing, while studies on risks associated with cross biases are limited to immediate context preferences. Cross-language disparities in reasoning-based recommendations remain largely unexplored, with a lack of even descriptive analysis. This study is the first to address this gap. We test LLM's applicability and capability in providing personalized advice across three key scenarios: university applications, travel, and relocation. We investigate multilingual bias in state-of-the-art LLMs by analyzing their responses to decision-making tasks across multiple languages. We quantify bias in model-generated scores and assess the impact of demographic factors and reasoning strategies (e.g., Chain-of-Thought prompting) on bias patterns. Our findings reveal that local language bias is prevalent across different tasks, with GPT-4 and Sonnet reducing bias for English-speaking countries compared to GPT-3.5 but failing to achieve robust multilingual alignment, highlighting broader implications for multilingual AI agents and applications such as education.