 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed-CoReasoner: Reducing Language Disparities in Medical Reasoning via Language-Informed Co-Reasoning
Jan 13, 2026While reasoning-enhanced large language models perform strongly on English medical tasks, a persistent multilingual gap remains, with substantially weaker reasoning in local languages, limiting equitable global medical deployment. To bridge this gap, we introduce Med-CoReasoner, a language-informed co-reasoning framework that elicits parallel English and local-language reasoning, abstracts them into structured concepts, and integrates local clinical knowledge into an English logical scaffold via concept-level alignment and retrieval. This design combines the structural robustness of English reasoning with the practice-grounded expertise encoded in local languages. To evaluate multilingual medical reasoning beyond multiple-choice settings, we construct MultiMed-X, a benchmark covering seven languages with expert-annotated long-form question answering and natural language inference tasks, comprising 350 instances per language. Experiments across three benchmarks show that Med-CoReasoner improves multilingual reasoning performance by an average of 5%, with particularly substantial gains in low-resource languages. Moreover, model distillation and expert evaluation analysis further confirm that Med-CoReasoner produces clinically sound and culturally grounded reasoning traces.
RadGS-Reg: Registering Spine CT with Biplanar X-rays via Joint 3D Radiative Gaussians Reconstruction and 3D/3D Registration
Aug 28, 2025Computed Tomography (CT)/X-ray registration in image-guided navigation remains challenging because of its stringent requirements for high accuracy and real-time performance. Traditional "render and compare" methods, relying on iterative projection and comparison, suffer from spatial information loss and domain gap. 3D reconstruction from biplanar X-rays supplements spatial and shape information for 2D/3D registration, but current methods are limited by dense-view requirements and struggles with noisy X-rays. To address these limitations, we introduce RadGS-Reg, a novel framework for vertebral-level CT/X-ray registration through joint 3D Radiative Gaussians (RadGS) reconstruction and 3D/3D registration. Specifically, our biplanar X-rays vertebral RadGS reconstruction module explores learning-based RadGS reconstruction method with a Counterfactual Attention Learning (CAL) mechanism, focusing on vertebral regions in noisy X-rays. Additionally, a patient-specific pre-training strategy progressively adapts the RadGS-Reg from simulated to real data while simultaneously learning vertebral shape prior knowledge. Experiments on in-house datasets demonstrate the state-of-the-art performance for both tasks, surpassing existing methods. The code is available at: https://github.com/shenao1995/RadGS_Reg.
A Survey on Computational Solutions for Reconstructing Complete Objects by Reassembling Their Fractured Parts
Oct 18, 2024Reconstructing a complete object from its parts is a fundamental problem in many scientific domains. The purpose of this article is to provide a systematic survey on this topic. The reassembly problem requires understanding the attributes of individual pieces and establishing matches between different pieces. Many approaches also model priors of the underlying complete object. Existing approaches are tightly connected problems of shape segmentation, shape matching, and learning shape priors. We provide existing algorithms in this context and emphasize their similarities and differences to general-purpose approaches. We also survey the trends from early non-deep learning approaches to more recent deep learning approaches. In addition to algorithms, this survey will also describe existing datasets, open-source software packages, and applications. To the best of our knowledge, this is the first comprehensive survey on this topic in computer graphics.
Beyond English-Centric LLMs: What Language Do Multilingual Language Models Think in?
Aug 20, 2024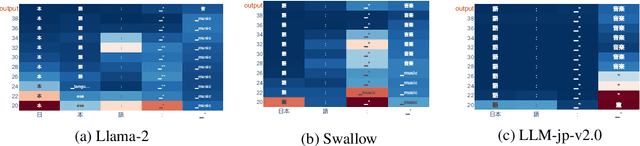

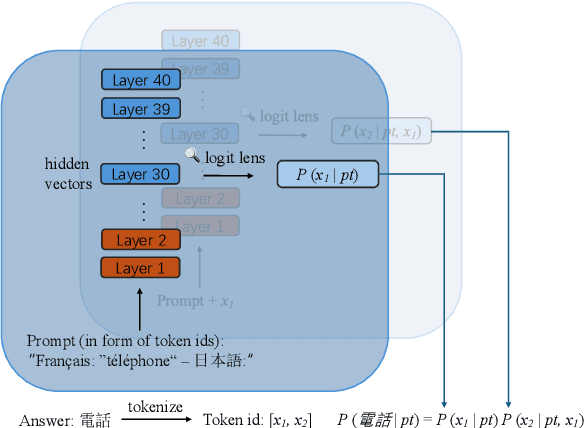
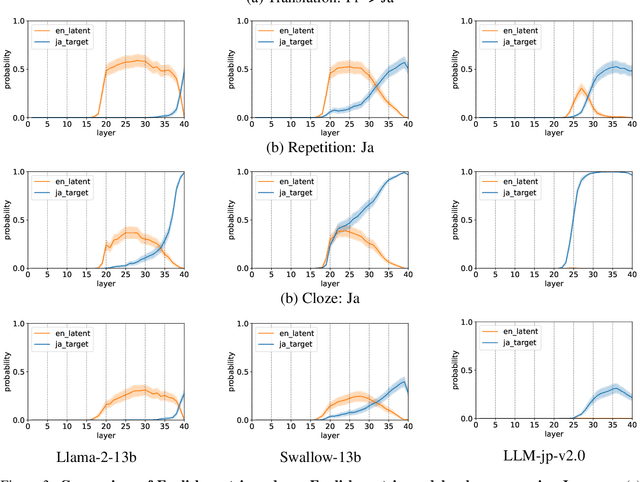
In this study, we investigate whether non-English-centric LLMs, despite their strong performance, `think' in their respective dominant language: more precisely, `think' refers to how the representations of intermediate layers, when un-embedded into the vocabulary space, exhibit higher probabilities for certain dominant languages during generation. We term such languages as internal $\textbf{latent languages}$. We examine the latent language of three typical categories of models for Japanese processing: Llama2, an English-centric model; Swallow, an English-centric model with continued pre-training in Japanese; and LLM-jp, a model pre-trained on balanced English and Japanese corpora. Our empirical findings reveal that, unlike Llama2 which relies exclusively on English as the internal latent language, Japanese-specific Swallow and LLM-jp employ both Japanese and English, exhibiting dual internal latent languages. For any given target language, the model preferentially activates the latent language most closely related to it. In addition, we explore how intermediate layers respond to questions involving cultural conflicts between latent internal and target output languages. We further explore how the language identity shifts across layers while keeping consistent semantic meaning reflected in the intermediate layer representations. This study deepens the understanding of non-English-centric large language models, highlighting the intricate dynamics of language representation within their intermediate layers.
TWOLAR: a TWO-step LLM-Augmented distillation method for passage Reranking
Mar 26, 2024In this paper, we present TWOLAR: a two-stage pipeline for passage reranking based on the distillation of knowledge from Large Language Models (LLM). TWOLAR introduces a new scoring strategy and a distillation process consisting in the creation of a novel and diverse training dataset. The dataset consists of 20K queries, each associated with a set of documents retrieved via four distinct retrieval methods to ensure diversity, and then reranked by exploiting the zero-shot reranking capabilities of an LLM. Our ablation studies demonstrate the contribution of each new component we introduced. Our experimental results show that TWOLAR significantly enhances the document reranking ability of the underlying model, matching and in some cases even outperforming state-of-the-art models with three orders of magnitude more parameters on the TREC-DL test sets and the zero-shot evaluation benchmark BEIR. To facilitate future work we release our data set, finetuned models, and code.
A Survey of Pre-trained Language Models for Processing Scientific Text
Jan 31, 2024The number of Language Models (LMs) dedicated to processing scientific text is on the rise. Keeping pace with the rapid growth of scientific LMs (SciLMs) has become a daunting task for researchers. To date, no comprehensive surveys on SciLMs have been undertaken, leaving this issue unaddressed. Given the constant stream of new SciLMs, appraising the state-of-the-art and how they compare to each other remain largely unknown. This work fills that gap and provides a comprehensive review of SciLMs, including an extensive analysis of their effectiveness across different domains, tasks and datasets, and a discussion on the challenges that lie ahead.
JVNV: A Corpus of Japanese Emotional Speech with Verbal Content and Nonverbal Expressions
Oct 09, 2023



We present the JVNV, a Japanese emotional speech corpus with verbal content and nonverbal vocalizations whose scripts are generated by a large-scale language model. Existing emotional speech corpora lack not only proper emotional scripts but also nonverbal vocalizations (NVs) that are essential expressions in spoken language to express emotions. We propose an automatic script generation method to produce emotional scripts by providing seed words with sentiment polarity and phrases of nonverbal vocalizations to ChatGPT using prompt engineering. We select 514 scripts with balanced phoneme coverage from the generated candidate scripts with the assistance of emotion confidence scores and language fluency scores. We demonstrate the effectiveness of JVNV by showing that JVNV has better phoneme coverage and emotion recognizability than previous Japanese emotional speech corpora. We then benchmark JVNV on emotional text-to-speech synthesis using discrete codes to represent NVs. We show that there still exists a gap between the performance of synthesizing read-aloud speech and emotional speech, and adding NVs in the speech makes the task even harder, which brings new challenges for this task and makes JVNV a valuable resource for relevant works in the future. To our best knowledge, JVNV is the first speech corpus that generates scripts automatically using large language models.
SuperDialseg: A Large-scale Dataset for Supervised Dialogue Segmentation
May 15, 2023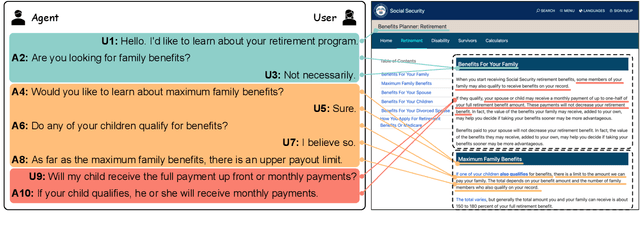
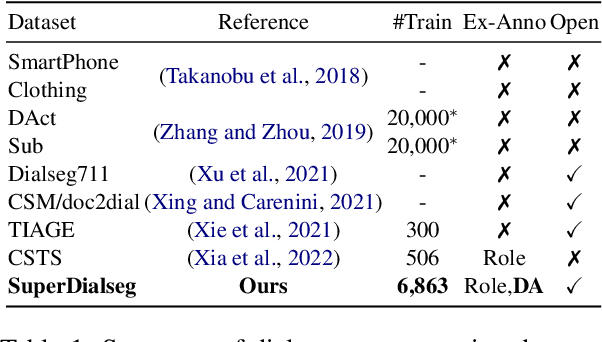
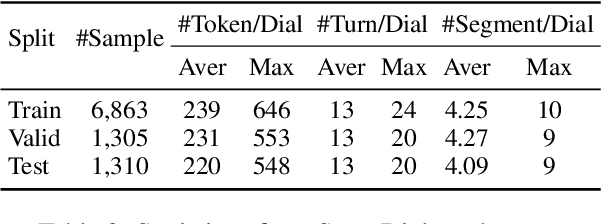
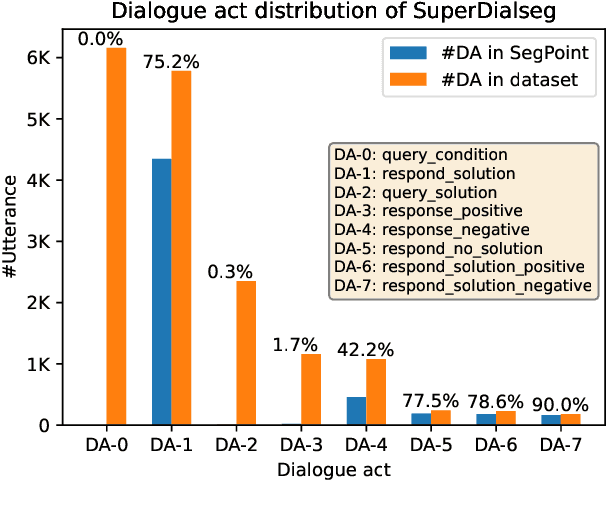
Dialogue segmentation is a crucial task for dialogue systems allowing a better understanding of conversational texts. Despite recent progress in unsupervised dialogue segmentation methods, their performances are limited by the lack of explicit supervised signals for training. Furthermore, the precise definition of segmentation points in conversations still remains as a challenging problem, increasing the difficulty of collecting manual annotations. In this paper, we provide a feasible definition of dialogue segmentation points with the help of document-grounded dialogues and release a large-scale supervised dataset called SuperDialseg, containing 9K dialogues based on two prevalent document-grounded dialogue corpora, and also inherit their useful dialogue-related annotations. Moreover, we propose two models to exploit the dialogue characteristics, achieving state-of-the-art performance on SuperDialseg and showing good generalization ability on the out-of-domain datasets. Additionally, we provide a benchmark including 20 models across four categories for the dialogue segmentation task with several proper evaluation metrics. Based on the analysis of the empirical studies, we also provide some insights for the task of dialogue segmentation. We believe our work is an important step forward in the field of dialogue segmentation.
Dial2vec: Self-Guided Contrastive Learning of Unsupervised Dialogue Embeddings
Oct 27, 2022



In this paper, we introduce the task of learning unsupervised dialogue embeddings. Trivial approaches such as combining pre-trained word or sentence embeddings and encoding through pre-trained language models (PLMs) have been shown to be feasible for this task. However, these approaches typically ignore the conversational interactions between interlocutors, resulting in poor performance. To address this issue, we proposed a self-guided contrastive learning approach named dial2vec. Dial2vec considers a dialogue as an information exchange process. It captures the conversational interaction patterns between interlocutors and leverages them to guide the learning of the embeddings corresponding to each interlocutor. The dialogue embedding is obtained by an aggregation of the embeddings from all interlocutors. To verify our approach, we establish a comprehensive benchmark consisting of six widely-used dialogue datasets. We consider three evaluation tasks: domain categorization, semantic relatedness, and dialogue retrieval. Dial2vec achieves on average 8.7, 9.0, and 13.8 points absolute improvements in terms of purity, Spearman's correlation, and mean average precision (MAP) over the strongest baseline on the three tasks respectively. Further analysis shows that dial2vec obtains informative and discriminative embeddings for both interlocutors under the guidance of the conversational interactions and achieves the best performance when aggregating them through the interlocutor-level pooling strategy. All codes and data are publicly available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/dial2vec.
ARAPReg: An As-Rigid-As Possible Regularization Loss for Learning Deformable Shape Generators
Aug 21, 2021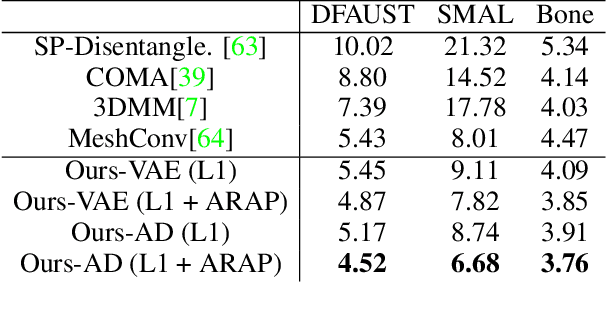
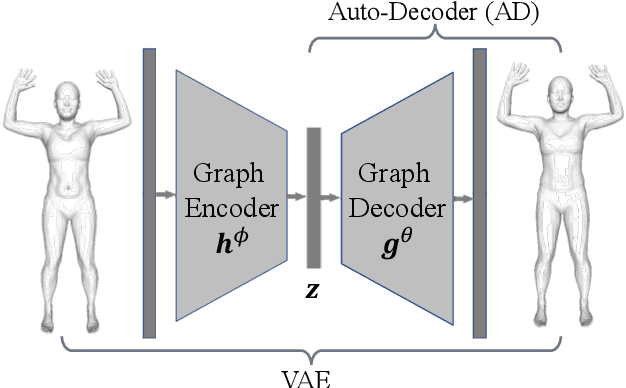

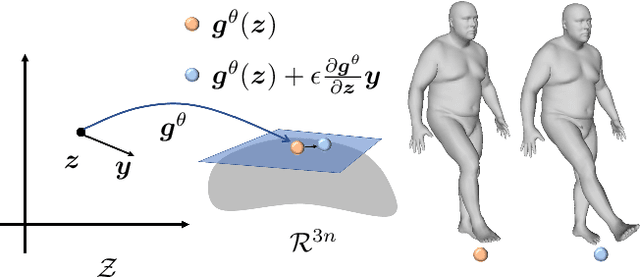
This paper introduces an unsupervised loss for training parametric deformation shape generators. The key idea is to enforce the preservation of local rigidity among the generated shapes. Our approach builds on an approximation of the as-rigid-as possible (or ARAP) deformation energy. We show how to develop the unsupervised loss via a spectral decomposition of the Hessian of the ARAP energy. Our loss nicely decouples pose and shape variations through a robust norm. The loss admits simple closed-form expressions. It is easy to train and can be plugged into any standard generation models, e.g., variational auto-encoder (VAE) and auto-decoder (AD). Experimental results show that our approach outperforms existing shape generation approaches considerably on public benchmark datasets of various shape categories such as human, animal and bone.