 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Chatbot for Asylum-Seeking Migrants in Europe
Jul 12, 2024
We present ACME: A Chatbot for asylum-seeking Migrants in Europe. ACME relies on computational argumentation and aims to help migrants identify the highest level of protection they can apply for. This would contribute to a more sustainable migration by reducing the load on territorial commissions, Courts, and humanitarian organizations supporting asylum applicants. We describe the context, system architectures, technologies, and the case study used to run the demonstration.
Dynamic Few-Shot Learning for Knowledge Graph Question Answering
Jul 01, 2024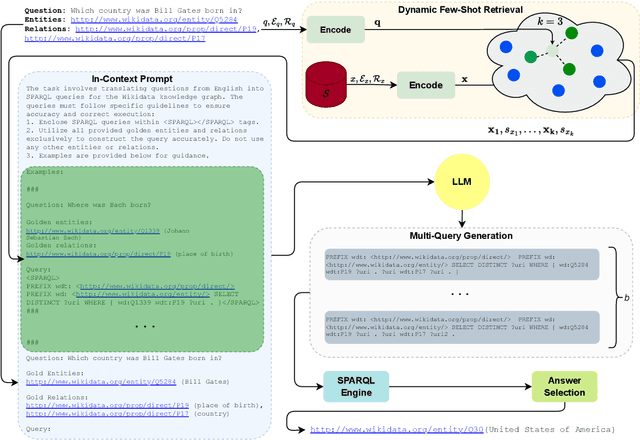


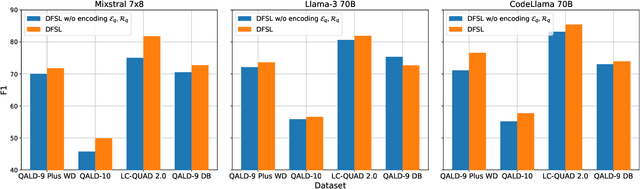
Large language models present opportunities for innovative Question Answering over Knowledge Graphs (KGQA). However, they are not inherently designed for query generation. To bridge this gap, solutions have been proposed that rely on fine-tuning or ad-hoc architectures, achieving good results but limited out-of-domain distribution generalization. In this study, we introduce a novel approach called Dynamic Few-Shot Learning (DFSL). DFSL integrates the efficiency of in-context learning and semantic similarity and provides a generally applicable solution for KGQA with state-of-the-art performance. We run an extensive evaluation across multiple benchmark datasets and architecture configurations.
Let Guidelines Guide You: A Prescriptive Guideline-Centered Data Annotation Methodology
Jun 20, 2024


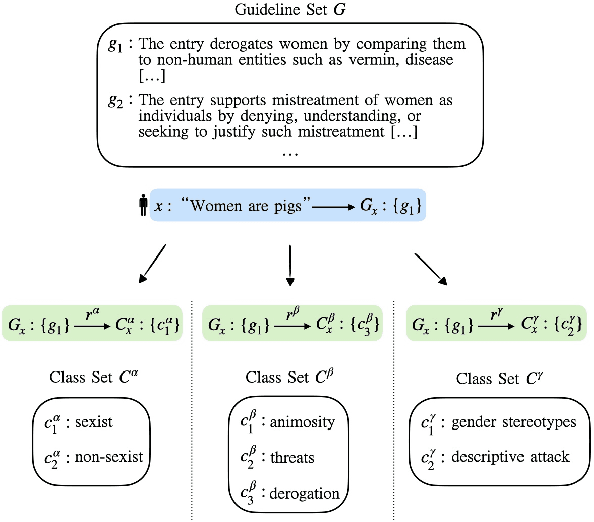
We introduce the Guideline-Centered annotation process, a novel data annotation methodology focused on reporting the annotation guidelines associated with each data sample. We identify three main limitations of the standard prescriptive annotation process and describe how the Guideline-Centered methodology overcomes them by reducing the loss of information in the annotation process and ensuring adherence to guidelines. Additionally, we discuss how the Guideline-Centered enables the reuse of annotated data across multiple tasks at the cost of a single human-annotation process.
Promoting Fairness and Diversity in Speech Datasets for Mental Health and Neurological Disorders Research
Jun 06, 2024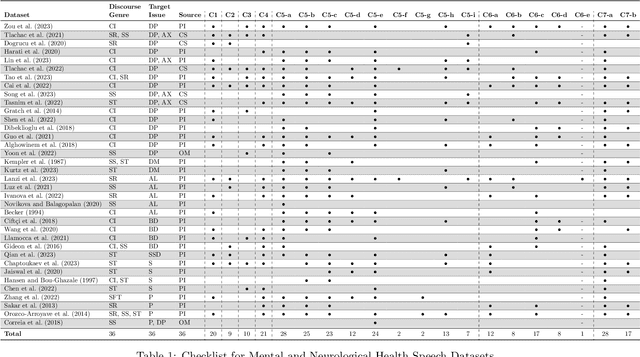
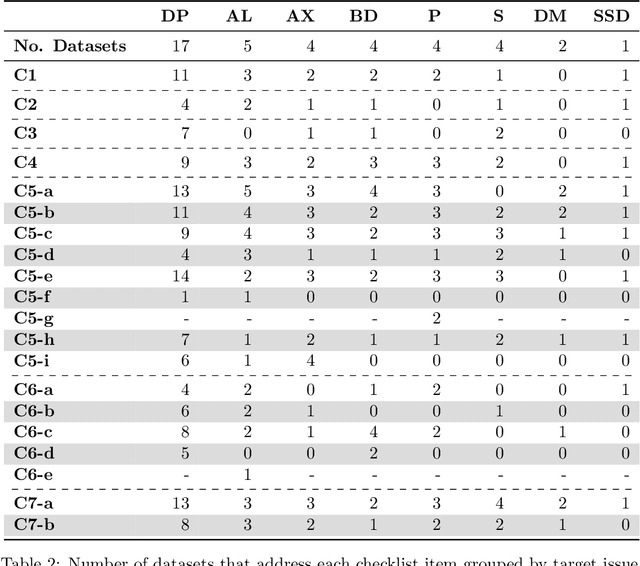
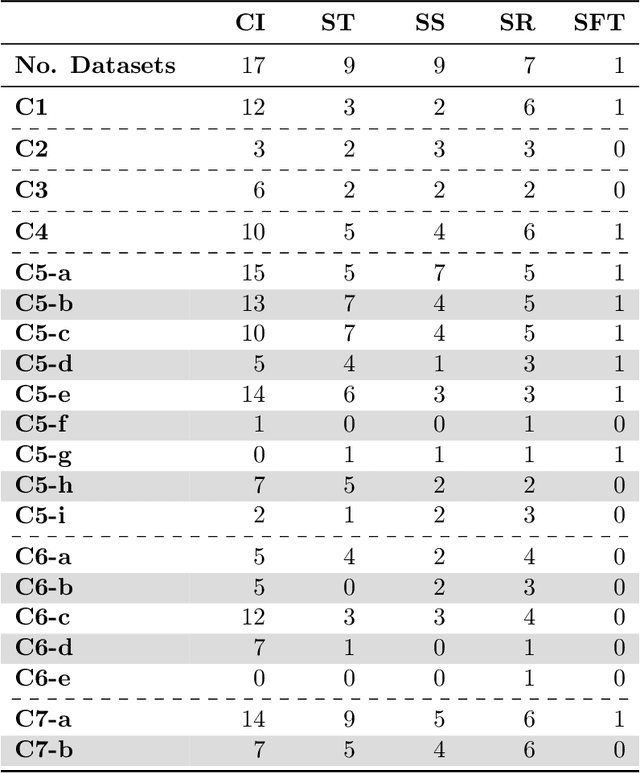
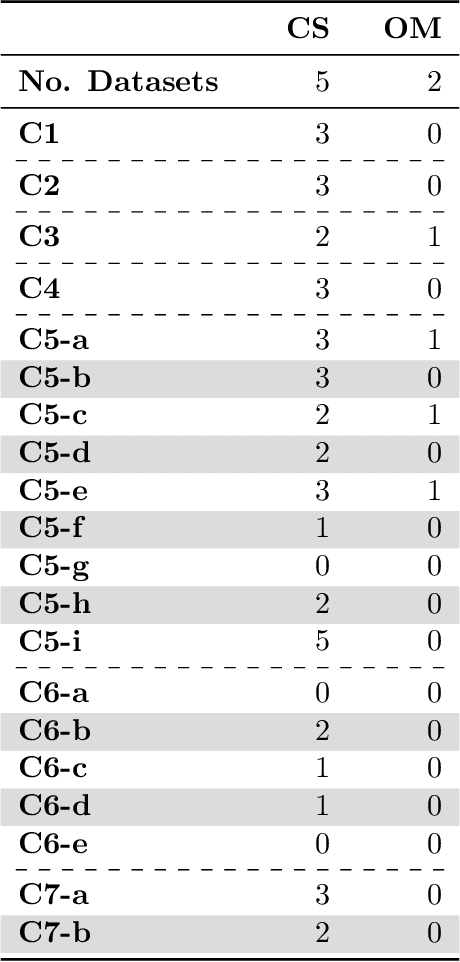
Current research in machine learning and artificial intelligence is largely centered on modeling and performance evaluation, less so on data collection. However, recent research demonstrated that limitations and biases in data may negatively impact trustworthiness and reliability. These aspects are particularly impactful on sensitive domains such as mental health and neurological disorders, where speech data are used to develop AI applications aimed at improving the health of patients and supporting healthcare providers. In this paper, we chart the landscape of available speech datasets for this domain, to highlight possible pitfalls and opportunities for improvement and promote fairness and diversity. We present a comprehensive list of desiderata for building speech datasets for mental health and neurological disorders and distill it into a checklist focused on ethical concerns to foster more responsible research.
TWOLAR: a TWO-step LLM-Augmented distillation method for passage Reranking
Mar 26, 2024In this paper, we present TWOLAR: a two-stage pipeline for passage reranking based on the distillation of knowledge from Large Language Models (LLM). TWOLAR introduces a new scoring strategy and a distillation process consisting in the creation of a novel and diverse training dataset. The dataset consists of 20K queries, each associated with a set of documents retrieved via four distinct retrieval methods to ensure diversity, and then reranked by exploiting the zero-shot reranking capabilities of an LLM. Our ablation studies demonstrate the contribution of each new component we introduced. Our experimental results show that TWOLAR significantly enhances the document reranking ability of the underlying model, matching and in some cases even outperforming state-of-the-art models with three orders of magnitude more parameters on the TREC-DL test sets and the zero-shot evaluation benchmark BEIR. To facilitate future work we release our data set, finetuned models, and code.
Fast Vocabulary Transfer for Language Model Compression
Feb 15, 2024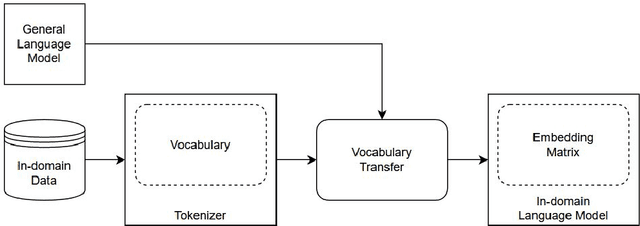
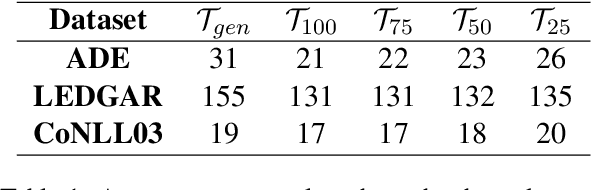

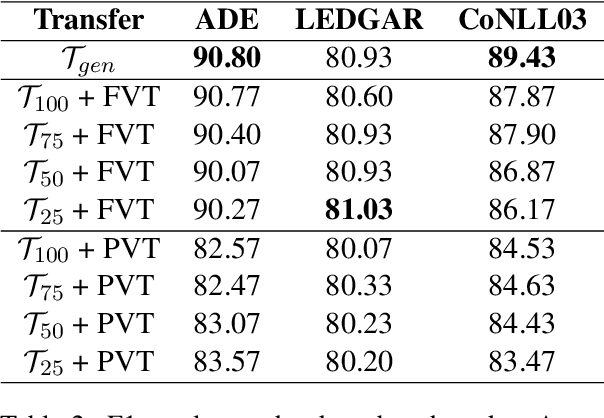
Real-world business applications require a trade-off between language model performance and size. We propose a new method for model compression that relies on vocabulary transfer. We evaluate the method on various vertical domains and downstream tasks. Our results indicate that vocabulary transfer can be effectively used in combination with other compression techniques, yielding a significant reduction in model size and inference time while marginally compromising on performance.
* The 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022)
MemBERT: Injecting Unstructured Knowledge into BERT
Sep 02, 2021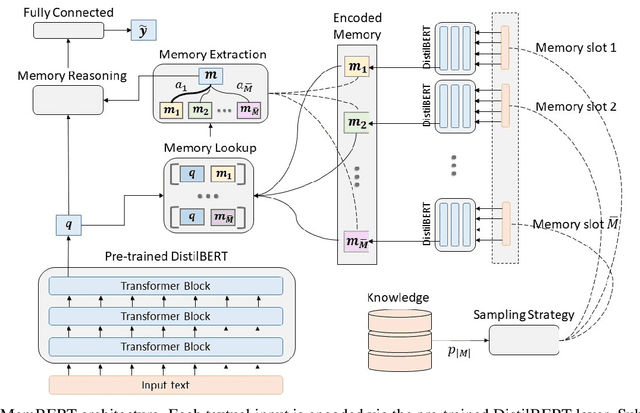
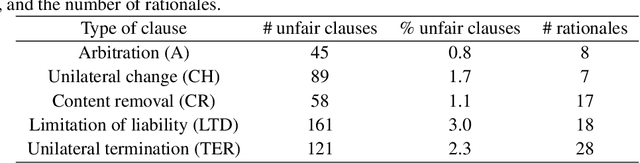
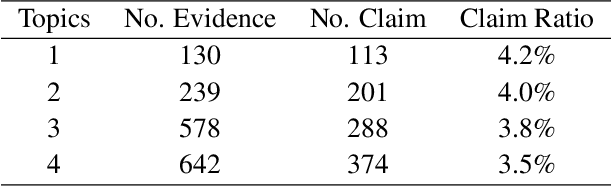
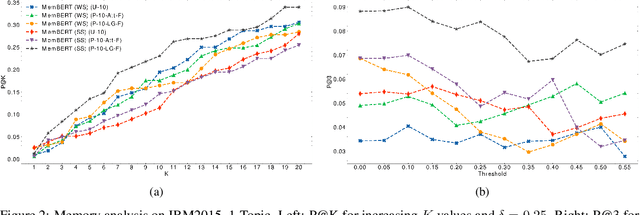
Transformers changed modern NLP in many ways. However, they can hardly exploit domain knowledge, and like other blackbox models, they lack interpretability. Unfortunately, structured knowledge injection, in the long run, risks to suffer from a knowledge acquisition bottleneck. We thus propose a memory enhancement of transformer models that makes use of unstructured domain knowledge expressed in plain natural language. An experimental evaluation conducted on two challenging NLP tasks demonstrates that our approach yields better performance and model interpretability than baseline transformer-based architectures.
Tree-Constrained Graph Neural Networks For Argument Mining
Sep 02, 2021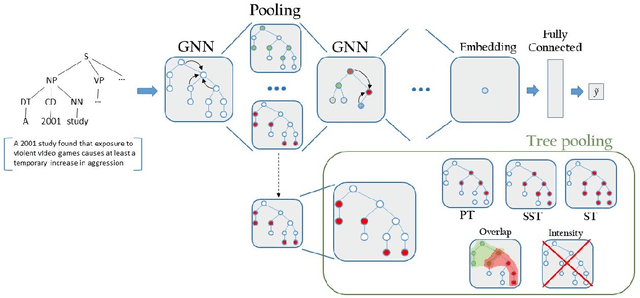

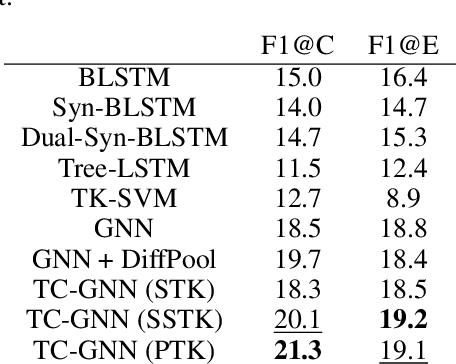

We propose a novel architecture for Graph Neural Networks that is inspired by the idea behind Tree Kernels of measuring similarity between trees by taking into account their common substructures, named fragments. By imposing a series of regularization constraints to the learning problem, we exploit a pooling mechanism that incorporates such notion of fragments within the node soft assignment function that produces the embeddings. We present an extensive experimental evaluation on a collection of sentence classification tasks conducted on several argument mining corpora, showing that the proposed approach performs well with respect to state-of-the-art techniques.
An Argumentative Dialogue System for COVID-19 Vaccine Information
Jul 26, 2021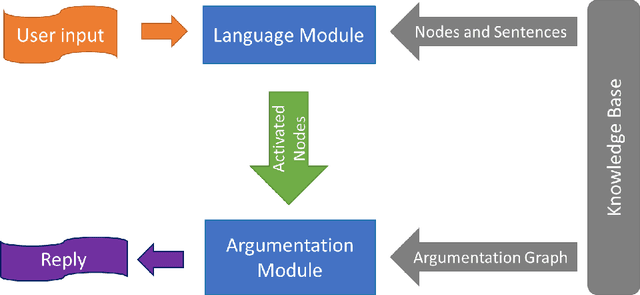
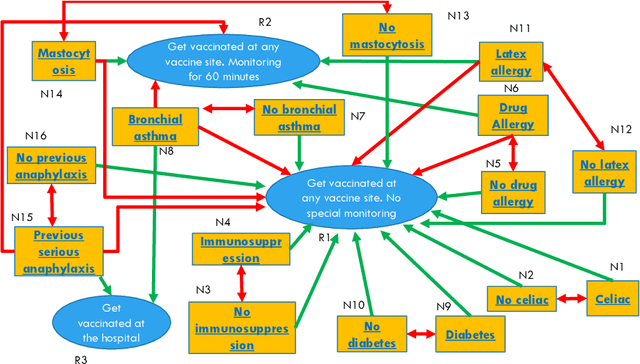
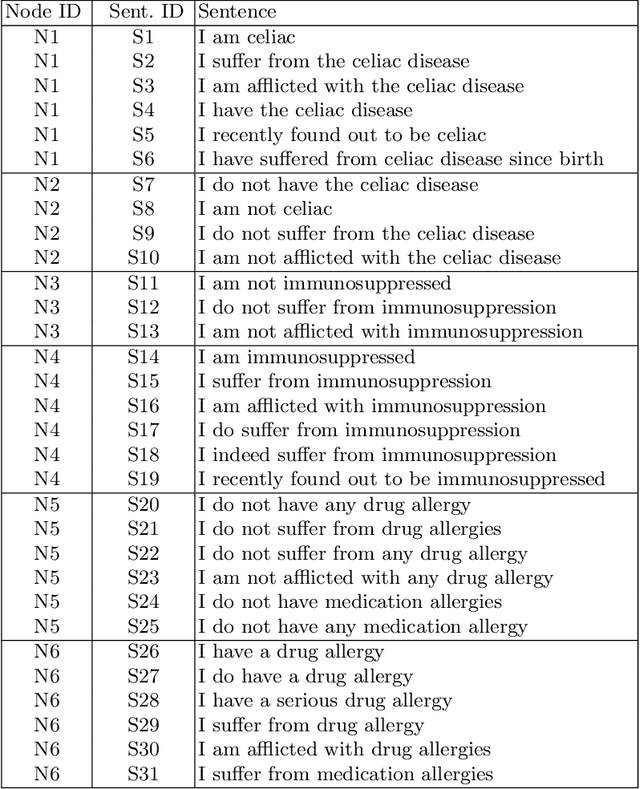
Dialogue systems are widely used in AI to support timely and interactive communication with users. We propose a general-purpose dialogue system architecture that leverages computational argumentation and state-of-the-art language technologies. We illustrate and evaluate the system using a COVID-19 vaccine information case study.
Multi-Task Attentive Residual Networks for Argument Mining
Feb 24, 2021



We explore the use of residual networks and neural attention for argument mining and in particular link prediction. The method we propose makes no assumptions on document or argument structure. We propose a residual architecture that exploits attention, multi-task learning, and makes use of ensemble. We evaluate it on a challenging data set consisting of user-generated comments, as well as on two other datasets consisting of scientific publications. On the user-generated content dataset, our model outperforms state-of-the-art methods that rely on domain knowledge. On the scientific literature datasets it achieves results comparable to those yielded by BERT-based approaches but with a much smaller model size.