 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Retrieval in RAG Systems for Large Legal Datasets
Oct 08, 2025



Retrieval-Augmented Generation (RAG) is a promising approach to mitigate hallucinations in Large Language Models (LLMs) for legal applications, but its reliability is critically dependent on the accuracy of the retrieval step. This is particularly challenging in the legal domain, where large databases of structurally similar documents often cause retrieval systems to fail. In this paper, we address this challenge by first identifying and quantifying a critical failure mode we term Document-Level Retrieval Mismatch (DRM), where the retriever selects information from entirely incorrect source documents. To mitigate DRM, we investigate a simple and computationally efficient technique which we refer to as Summary-Augmented Chunking (SAC). This method enhances each text chunk with a document-level synthetic summary, thereby injecting crucial global context that would otherwise be lost during a standard chunking process. Our experiments on a diverse set of legal information retrieval tasks show that SAC greatly reduces DRM and, consequently, also improves text-level retrieval precision and recall. Interestingly, we find that a generic summarization strategy outperforms an approach that incorporates legal expert domain knowledge to target specific legal elements. Our work provides evidence that this practical, scalable, and easily integrable technique enhances the reliability of RAG systems when applied to large-scale legal document datasets.
LTLZinc: a Benchmarking Framework for Continual Learning and Neuro-Symbolic Temporal Reasoning
Jul 23, 2025



Neuro-symbolic artificial intelligence aims to combine neural architectures with symbolic approaches that can represent knowledge in a human-interpretable formalism. Continual learning concerns with agents that expand their knowledge over time, improving their skills while avoiding to forget previously learned concepts. Most of the existing approaches for neuro-symbolic artificial intelligence are applied to static scenarios only, and the challenging setting where reasoning along the temporal dimension is necessary has been seldom explored. In this work we introduce LTLZinc, a benchmarking framework that can be used to generate datasets covering a variety of different problems, against which neuro-symbolic and continual learning methods can be evaluated along the temporal and constraint-driven dimensions. Our framework generates expressive temporal reasoning and continual learning tasks from a linear temporal logic specification over MiniZinc constraints, and arbitrary image classification datasets. Fine-grained annotations allow multiple neural and neuro-symbolic training settings on the same generated datasets. Experiments on six neuro-symbolic sequence classification and four class-continual learning tasks generated by LTLZinc, demonstrate the challenging nature of temporal learning and reasoning, and highlight limitations of current state-of-the-art methods. We release the LTLZinc generator and ten ready-to-use tasks to the neuro-symbolic and continual learning communities, in the hope of fostering research towards unified temporal learning and reasoning frameworks.
A Neuro-Symbolic Framework for Sequence Classification with Relational and Temporal Knowledge
May 08, 2025



One of the goals of neuro-symbolic artificial intelligence is to exploit background knowledge to improve the performance of learning tasks. However, most of the existing frameworks focus on the simplified scenario where knowledge does not change over time and does not cover the temporal dimension. In this work we consider the much more challenging problem of knowledge-driven sequence classification where different portions of knowledge must be employed at different timesteps, and temporal relations are available. Our experimental evaluation compares multi-stage neuro-symbolic and neural-only architectures, and it is conducted on a newly-introduced benchmarking framework. Results demonstrate the challenging nature of this novel setting, and also highlight under-explored shortcomings of neuro-symbolic methods, representing a precious reference for future research.
The KANDY Benchmark: Incremental Neuro-Symbolic Learning and Reasoning with Kandinsky Patterns
Feb 27, 2024



Artificial intelligence is continuously seeking novel challenges and benchmarks to effectively measure performance and to advance the state-of-the-art. In this paper we introduce KANDY, a benchmarking framework that can be used to generate a variety of learning and reasoning tasks inspired by Kandinsky patterns. By creating curricula of binary classification tasks with increasing complexity and with sparse supervisions, KANDY can be used to implement benchmarks for continual and semi-supervised learning, with a specific focus on symbol compositionality. Classification rules are also provided in the ground truth to enable analysis of interpretable solutions. Together with the benchmark generation pipeline, we release two curricula, an easier and a harder one, that we propose as new challenges for the research community. With a thorough experimental evaluation, we show how both state-of-the-art neural models and purely symbolic approaches struggle with solving most of the tasks, thus calling for the application of advanced neuro-symbolic methods trained over time.
Individual and Collective Autonomous Development
Oct 03, 2021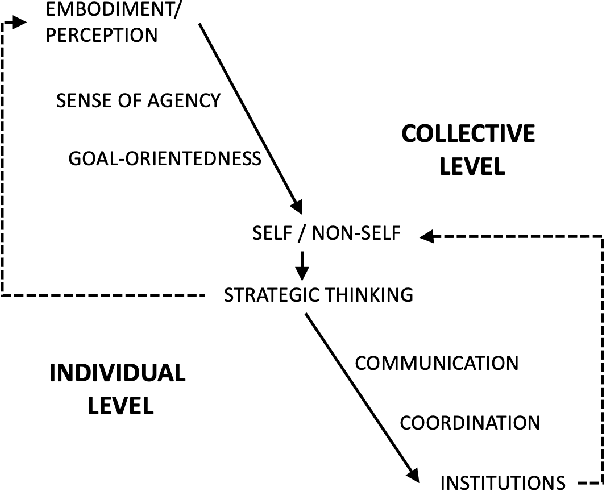
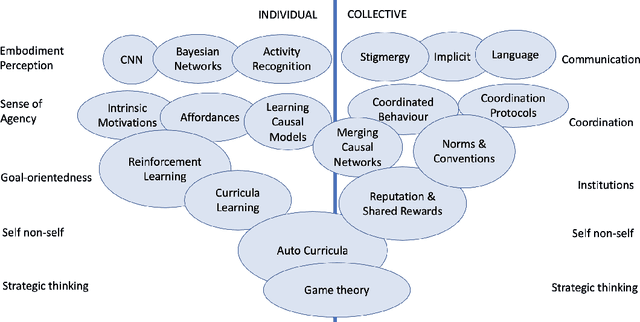
The increasing complexity and unpredictability of many ICT scenarios let us envision that future systems will have to dynamically learn how to act and adapt to face evolving situations with little or no a priori knowledge, both at the level of individual components and at the collective level. In other words, such systems should become able to autonomously develop models of themselves and of their environment. Autonomous development includes: learning models of own capabilities; learning how to act purposefully towards the achievement of specific goals; and learning how to act collectively, i.e., accounting for the presence of others. In this paper, we introduce the vision of autonomous development in ICT systems, by framing its key concepts and by illustrating suitable application domains. Then, we overview the many research areas that are contributing or can potentially contribute to the realization of the vision, and identify some key research challenges.
MemBERT: Injecting Unstructured Knowledge into BERT
Sep 02, 2021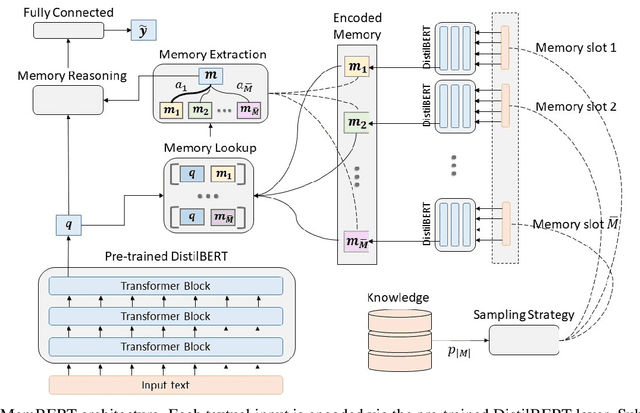
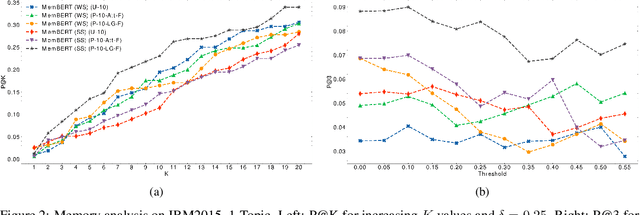
Transformers changed modern NLP in many ways. However, they can hardly exploit domain knowledge, and like other blackbox models, they lack interpretability. Unfortunately, structured knowledge injection, in the long run, risks to suffer from a knowledge acquisition bottleneck. We thus propose a memory enhancement of transformer models that makes use of unstructured domain knowledge expressed in plain natural language. An experimental evaluation conducted on two challenging NLP tasks demonstrates that our approach yields better performance and model interpretability than baseline transformer-based architectures.
Tree-Constrained Graph Neural Networks For Argument Mining
Sep 02, 2021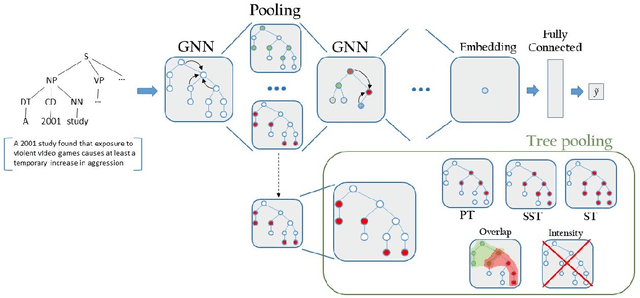

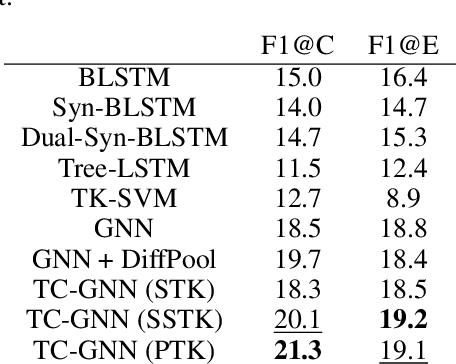

We propose a novel architecture for Graph Neural Networks that is inspired by the idea behind Tree Kernels of measuring similarity between trees by taking into account their common substructures, named fragments. By imposing a series of regularization constraints to the learning problem, we exploit a pooling mechanism that incorporates such notion of fragments within the node soft assignment function that produces the embeddings. We present an extensive experimental evaluation on a collection of sentence classification tasks conducted on several argument mining corpora, showing that the proposed approach performs well with respect to state-of-the-art techniques.
Multi-Task Attentive Residual Networks for Argument Mining
Feb 24, 2021



We explore the use of residual networks and neural attention for argument mining and in particular link prediction. The method we propose makes no assumptions on document or argument structure. We propose a residual architecture that exploits attention, multi-task learning, and makes use of ensemble. We evaluate it on a challenging data set consisting of user-generated comments, as well as on two other datasets consisting of scientific publications. On the user-generated content dataset, our model outperforms state-of-the-art methods that rely on domain knowledge. On the scientific literature datasets it achieves results comparable to those yielded by BERT-based approaches but with a much smaller model size.
Memory networks for consumer protection:unfairness exposed
Jul 24, 2020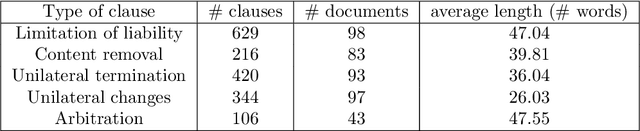
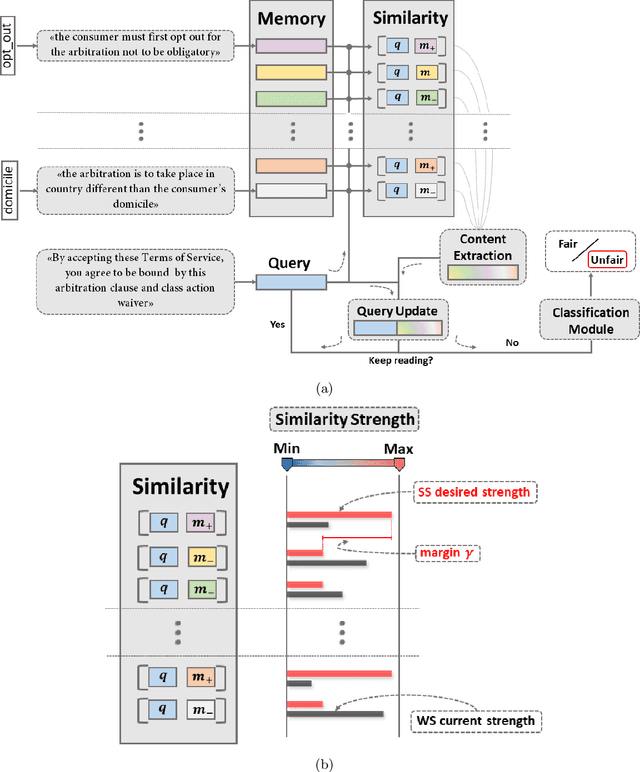
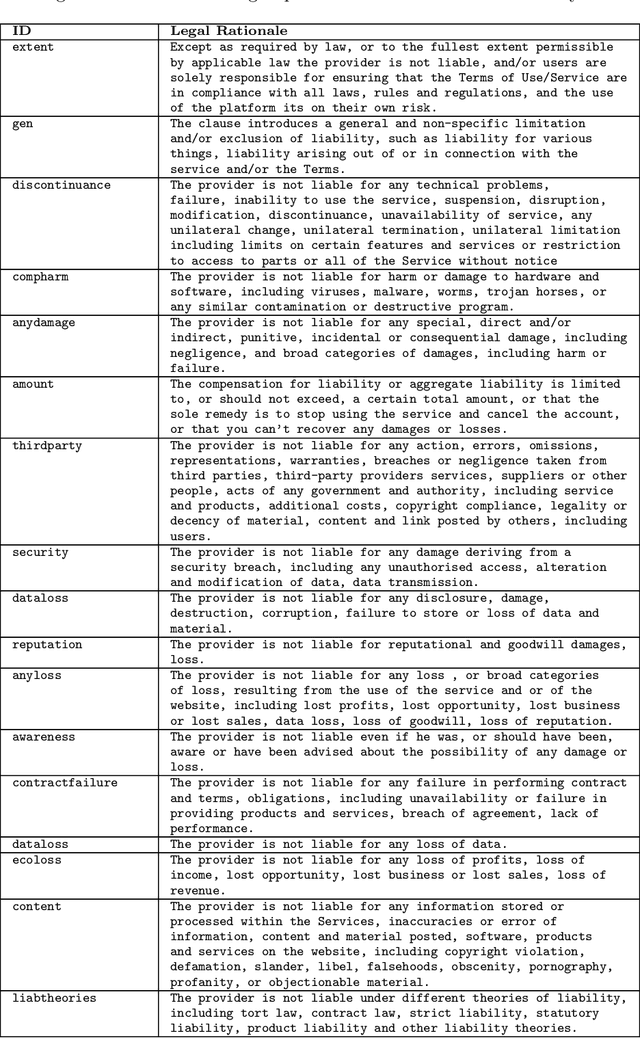
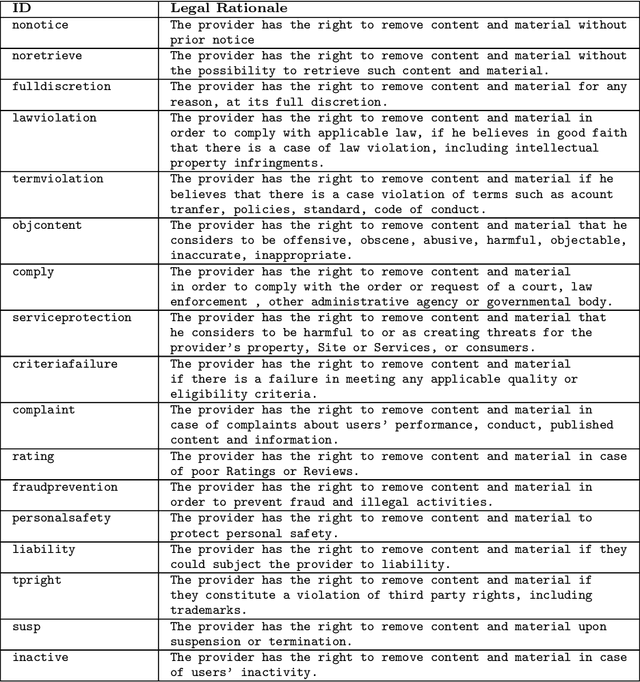
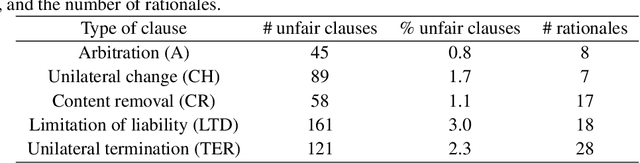
Recent work has demonstrated how data-driven AI methods can leverage consumer protection by supporting the automated analysis of legal documents. However, a shortcoming of data-driven approaches is poor explainability. We posit that in this domain useful explanations of classifier outcomes can be provided by resorting to legal rationales. We thus consider several configurations of memory-augmented neural networks where rationales are given a special role in the modeling of context knowledge. Our results show that rationales not only contribute to improve the classification accuracy, but are also able to offer meaningful, natural language explanations of otherwise opaque classifier outcomes.
Parallelizing Machine Learning as a Service for the End-User
May 29, 2020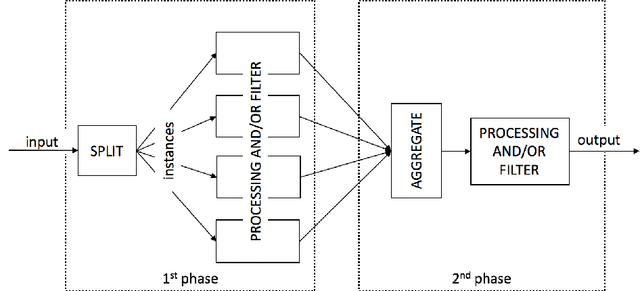

As ML applications are becoming ever more pervasive, fully-trained systems are made increasingly available to a wide public, allowing end-users to submit queries with their own data, and to efficiently retrieve results. With increasingly sophisticated such services, a new challenge is how to scale up to evergrowing user bases. In this paper, we present a distributed architecture that could be exploited to parallelize a typical ML system pipeline. We propose a case study consisting of a text mining service and discuss how the method can be generalized to many similar applications. We demonstrate the significance of the computational gain boosted by the distributed architecture by way of an extensive experimental evaluation.