Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemBERT: Injecting Unstructured Knowledge into BERT
Paper and Code
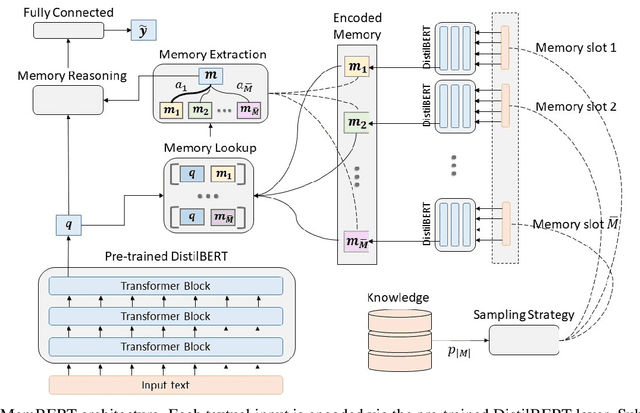
Transformers changed modern NLP in many ways. However, they can hardly exploit domain knowledge, and like other blackbox models, they lack interpretability. Unfortunately, structured knowledge injection, in the long run, risks to suffer from a knowledge acquisition bottleneck. We thus propose a memory enhancement of transformer models that makes use of unstructured domain knowledge expressed in plain natural language. An experimental evaluation conducted on two challenging NLP tasks demonstrates that our approach yields better performance and model interpretability than baseline transformer-based architectures.
View paper on