 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Counterfactual Explanations using Tractable Probabilistic Models
May 16, 2022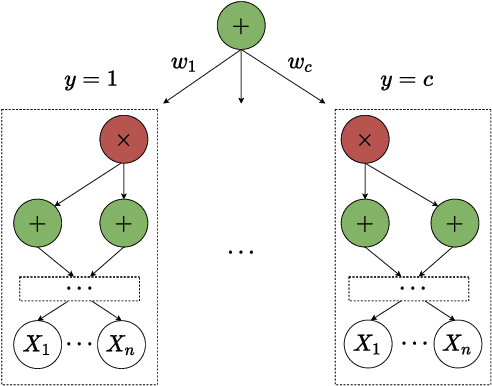

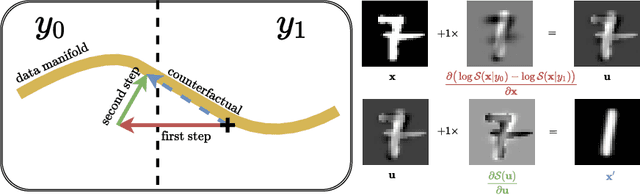
Counterfactual examples are an appealing class of post-hoc explanations for machine learning models. Given input $x$ of class $y_1$, its counterfactual is a contrastive example $x^\prime$ of another class $y_0$. Current approaches primarily solve this task by a complex optimization: define an objective function based on the loss of the counterfactual outcome $y_0$ with hard or soft constraints, then optimize this function as a black-box. This "deep learning" approach, however, is rather slow, sometimes tricky, and may result in unrealistic counterfactual examples. In this work, we propose a novel approach to deal with these problems using only two gradient computations based on tractable probabilistic models. First, we compute an unconstrained counterfactual $u$ of $x$ to induce the counterfactual outcome $y_0$. Then, we adapt $u$ to higher density regions, resulting in $x^{\prime}$. Empirical evidence demonstrates the dominant advantages of our approach.
Right for the Right Latent Factors: Debiasing Generative Models via Disentanglement
Feb 01, 2022

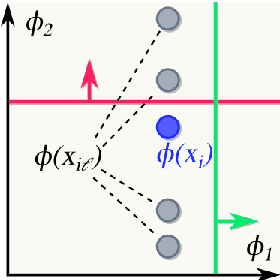
A key assumption of most statistical machine learning methods is that they have access to independent samples from the distribution of data they encounter at test time. As such, these methods often perform poorly in the face of biased data, which breaks this assumption. In particular, machine learning models have been shown to exhibit Clever-Hans-like behaviour, meaning that spurious correlations in the training set are inadvertently learnt. A number of works have been proposed to revise deep classifiers to learn the right correlations. However, generative models have been overlooked so far. We observe that generative models are also prone to Clever-Hans-like behaviour. To counteract this issue, we propose to debias generative models by disentangling their internal representations, which is achieved via human feedback. Our experiments show that this is effective at removing bias even when human feedback covers only a small fraction of the desired distribution. In addition, we achieve strong disentanglement results in a quantitative comparison with recent methods.
Right for the Wrong Scientific Reasons: Revising Deep Networks by Interacting with their Explanations
Jan 31, 2020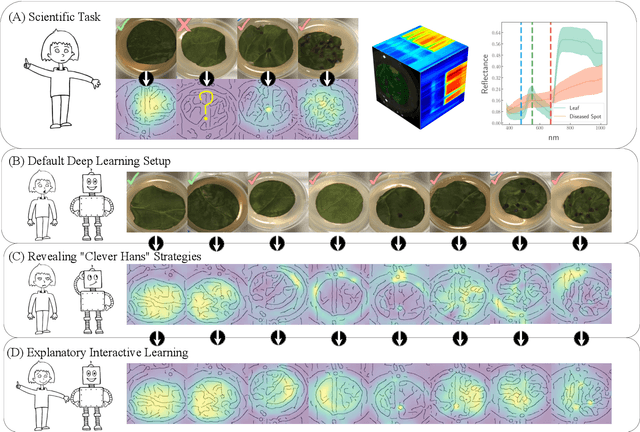

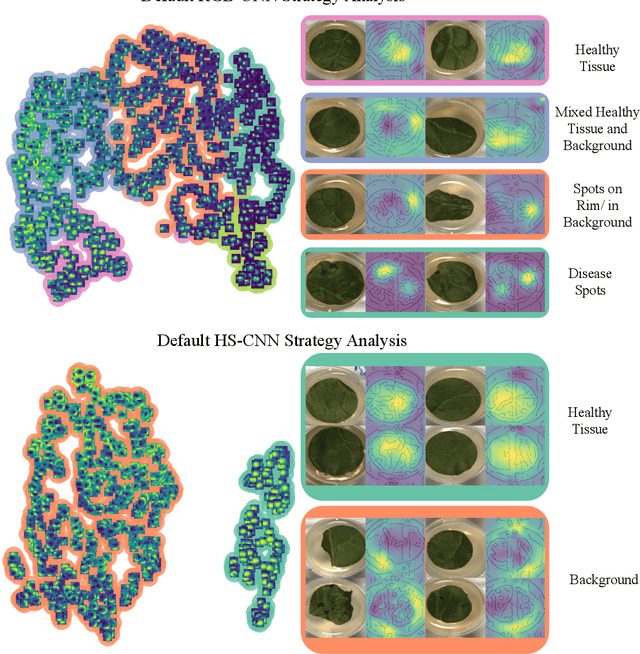
Deep neural networks have shown excellent performances in many real-world applications. Unfortunately, they may show "Clever Hans"-like behavior---making use of confounding factors within datasets---to achieve high performance. In this work we introduce the novel learning setting of "explanatory interactive learning" (XIL) and illustrate its benefits on a plant phenotyping research task. XIL adds the scientist into the training loop such that she interactively revises the original model via providing feedback on its explanations. Our experimental results demonstrate that XIL can help avoiding Clever Hans moments in machine learning and encourages (or discourages, if appropriate) trust into the underlying model.
Neural-Symbolic Argumentation Mining: an Argument in Favour of Deep Learning and Reasoning
May 31, 2019

Deep learning is bringing remarkable contributions to the field of argumentation mining, but the existing approaches still need to fill the gap towards performing advanced reasoning tasks. We illustrate how neural-symbolic and statistical relational learning could play a crucial role in the integration of symbolic and sub-symbolic methods to achieve this goal.
Conditional Sum-Product Networks: Imposing Structure on Deep Probabilistic Architectures
May 21, 2019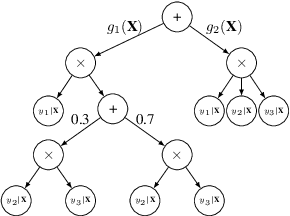
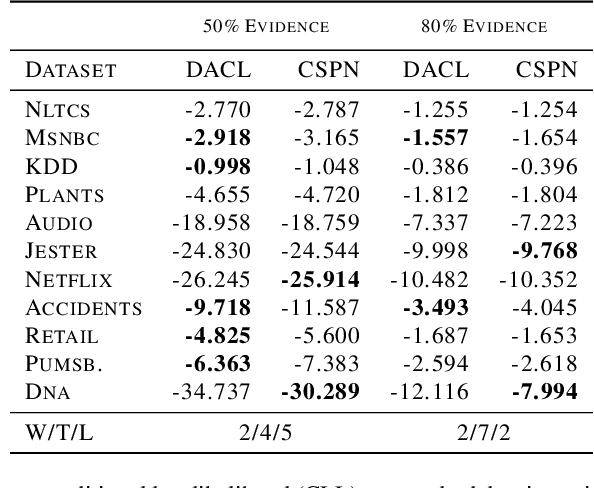
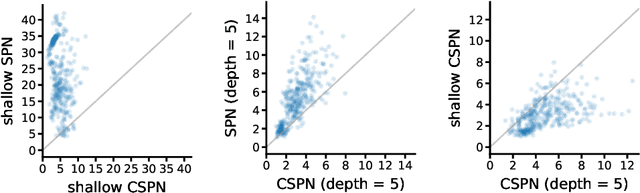

Bayesian networks are a central tool in machine learning and artificial intelligence, and make use of conditional independencies to impose structure on joint distributions. However, they are generally not as expressive as deep learning models and inference is hard and slow. In contrast, deep probabilistic models such as sum-product networks (SPNs) capture joint distributions in a tractable fashion, but use little interpretable structure. Here, we extend the notion of SPNs towards conditional distributions, which combine simple conditional models into high-dimensional ones. As shown in our experiments, the resulting conditional SPNs can be naturally used to impose structure on deep probabilistic models, allow for mixed data types, while maintaining fast and efficient inference.