 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Chatbot for Asylum-Seeking Migrants in Europe
Jul 12, 2024
We present ACME: A Chatbot for asylum-seeking Migrants in Europe. ACME relies on computational argumentation and aims to help migrants identify the highest level of protection they can apply for. This would contribute to a more sustainable migration by reducing the load on territorial commissions, Courts, and humanitarian organizations supporting asylum applicants. We describe the context, system architectures, technologies, and the case study used to run the demonstration.
Promoting Fairness and Diversity in Speech Datasets for Mental Health and Neurological Disorders Research
Jun 06, 2024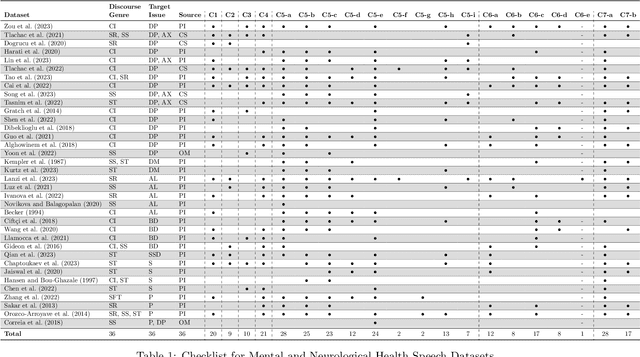
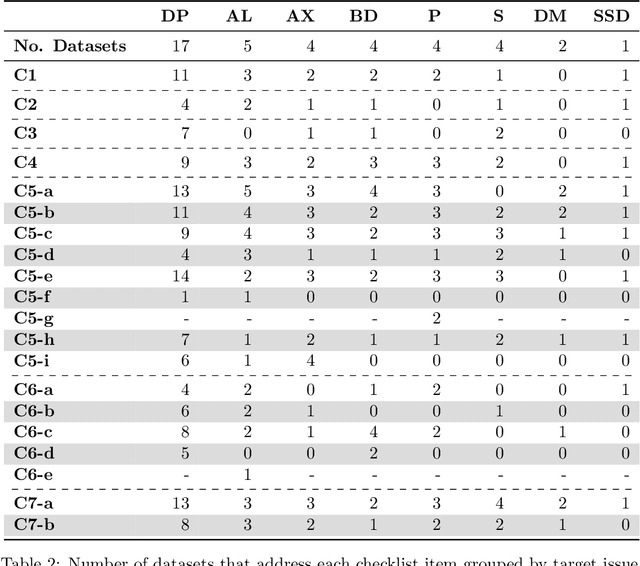
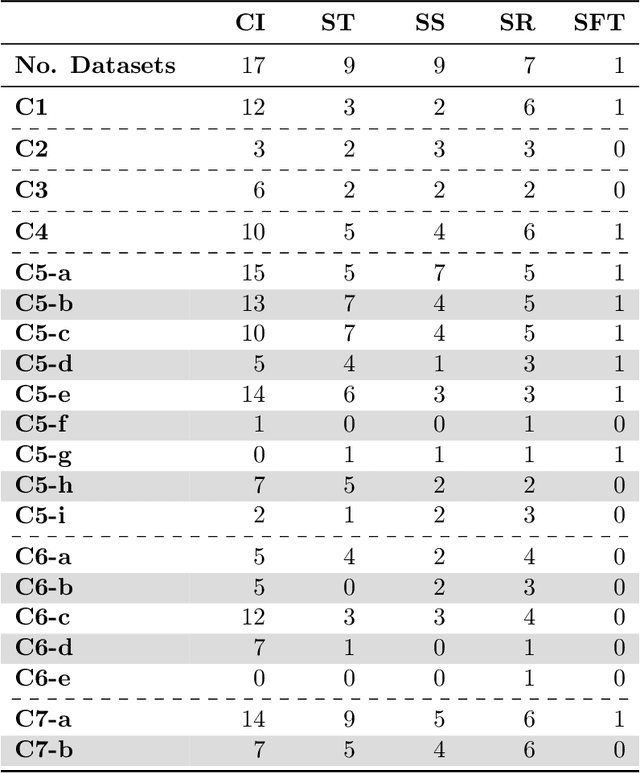
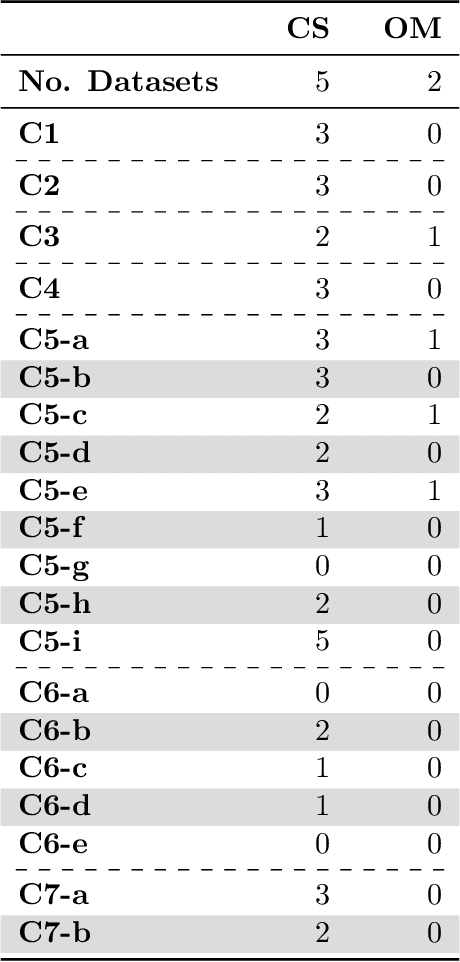
Current research in machine learning and artificial intelligence is largely centered on modeling and performance evaluation, less so on data collection. However, recent research demonstrated that limitations and biases in data may negatively impact trustworthiness and reliability. These aspects are particularly impactful on sensitive domains such as mental health and neurological disorders, where speech data are used to develop AI applications aimed at improving the health of patients and supporting healthcare providers. In this paper, we chart the landscape of available speech datasets for this domain, to highlight possible pitfalls and opportunities for improvement and promote fairness and diversity. We present a comprehensive list of desiderata for building speech datasets for mental health and neurological disorders and distill it into a checklist focused on ethical concerns to foster more responsible research.
A Corpus for Sentence-level Subjectivity Detection on English News Articles
May 29, 2023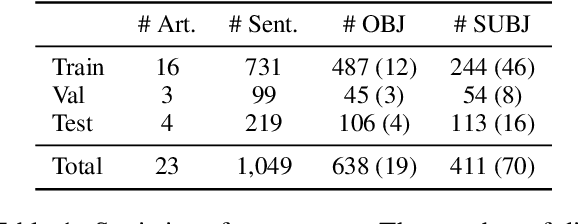

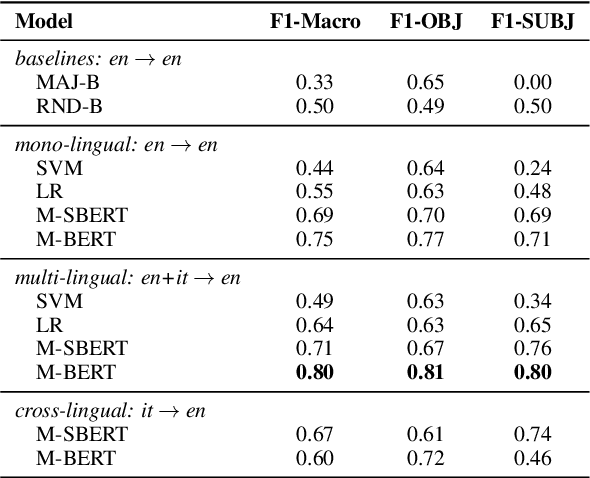
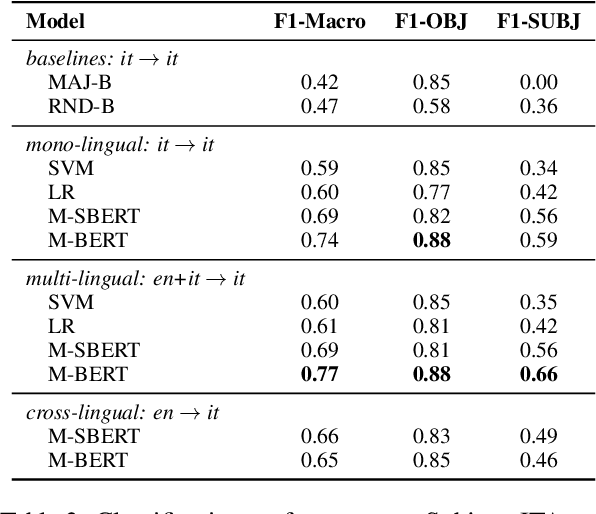
We present a novel corpus for subjectivity detection at the sentence level. We develop new annotation guidelines for the task, which are not limited to language-specific cues, and apply them to produce a new corpus in English. The corpus consists of 411 subjective and 638 objective sentences extracted from ongoing coverage of political affairs from online news outlets. This new resource paves the way for the development of models for subjectivity detection in English and across other languages, without relying on language-specific tools like lexicons or machine translation. We evaluate state-of-the-art multilingual transformer-based models on the task, both in mono- and cross-lingual settings, the latter with a similar existing corpus in Italian language. We observe that enriching our corpus with resources in other languages improves the results on the task.
LEXTREME: A Multi-Lingual and Multi-Task Benchmark for the Legal Domain
Jan 30, 2023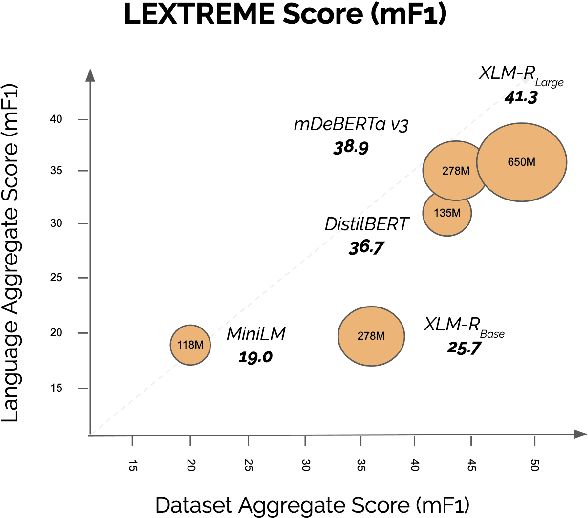
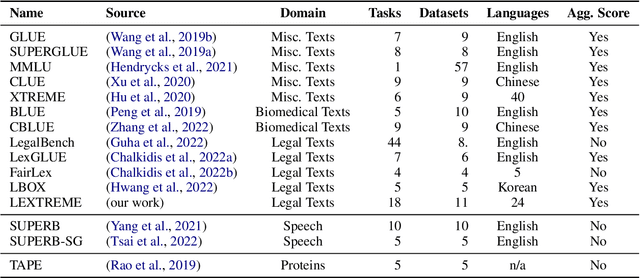
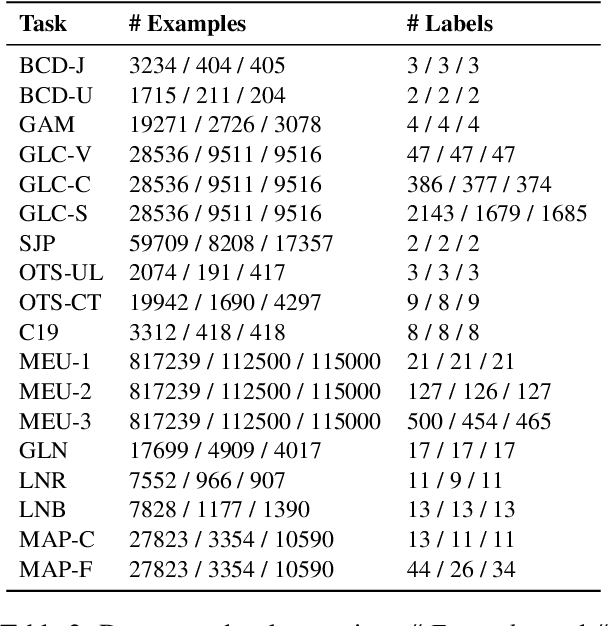
Lately, propelled by the phenomenal advances around the transformer architecture, the legal NLP field has enjoyed spectacular growth. To measure progress, well curated and challenging benchmarks are crucial. However, most benchmarks are English only and in legal NLP specifically there is no multilingual benchmark available yet. Additionally, many benchmarks are saturated, with the best models clearly outperforming the best humans and achieving near perfect scores. We survey the legal NLP literature and select 11 datasets covering 24 languages, creating LEXTREME. To provide a fair comparison, we propose two aggregate scores, one based on the datasets and one on the languages. The best baseline (XLM-R large) achieves both a dataset aggregate score a language aggregate score of 61.3. This indicates that LEXTREME is still very challenging and leaves ample room for improvement. To make it easy for researchers and practitioners to use, we release LEXTREME on huggingface together with all the code required to evaluate models and a public Weights and Biases project with all the runs.
An Argumentative Dialogue System for COVID-19 Vaccine Information
Jul 26, 2021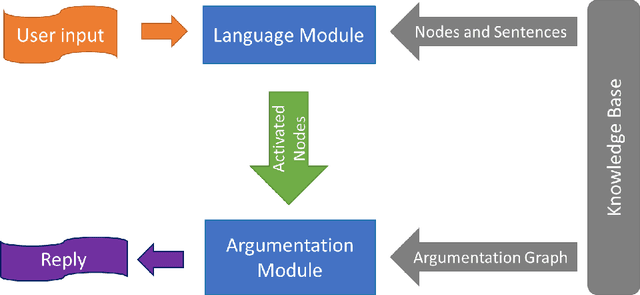
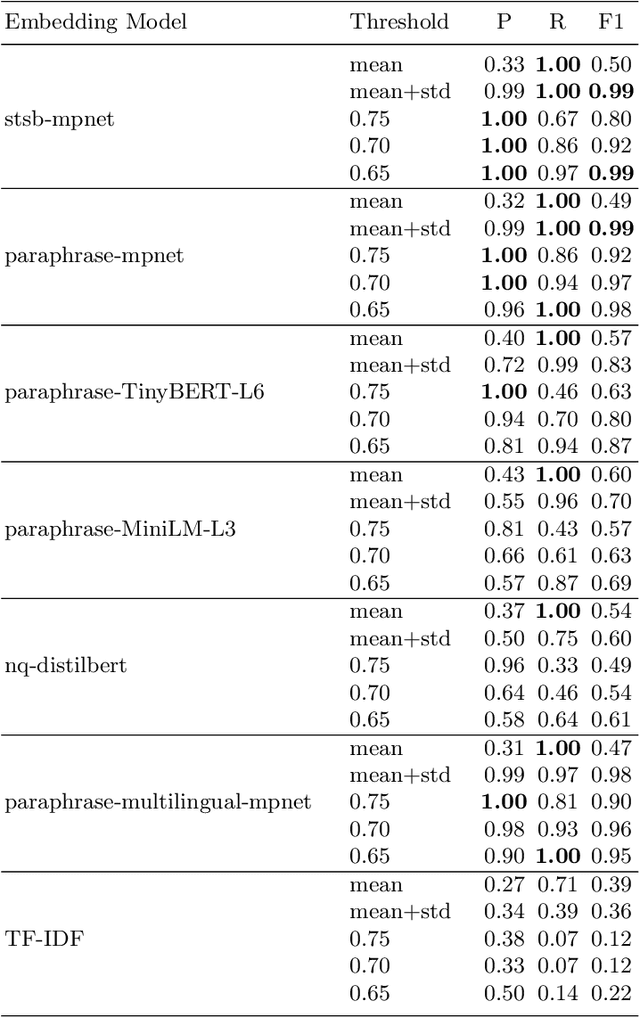
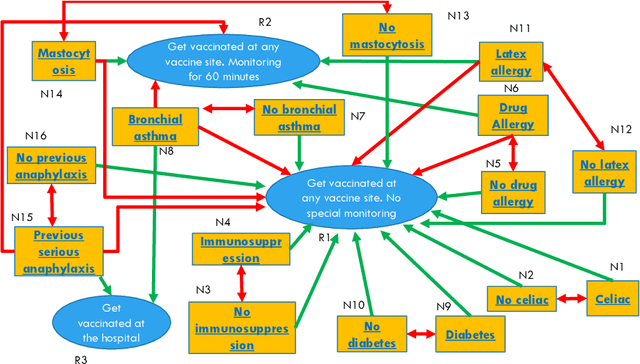
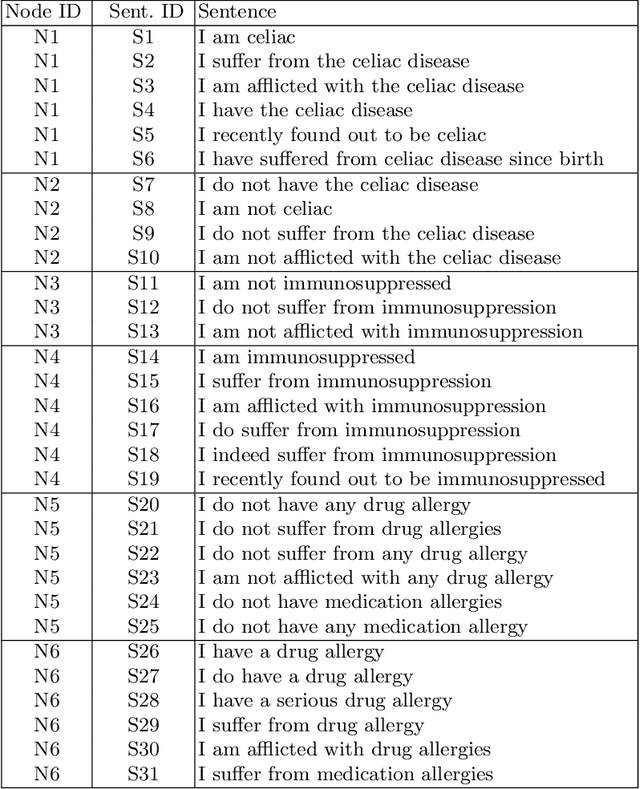
Dialogue systems are widely used in AI to support timely and interactive communication with users. We propose a general-purpose dialogue system architecture that leverages computational argumentation and state-of-the-art language technologies. We illustrate and evaluate the system using a COVID-19 vaccine information case study.
Multi-Task Attentive Residual Networks for Argument Mining
Feb 24, 2021



We explore the use of residual networks and neural attention for argument mining and in particular link prediction. The method we propose makes no assumptions on document or argument structure. We propose a residual architecture that exploits attention, multi-task learning, and makes use of ensemble. We evaluate it on a challenging data set consisting of user-generated comments, as well as on two other datasets consisting of scientific publications. On the user-generated content dataset, our model outperforms state-of-the-art methods that rely on domain knowledge. On the scientific literature datasets it achieves results comparable to those yielded by BERT-based approaches but with a much smaller model size.
Neural-Symbolic Argumentation Mining: an Argument in Favour of Deep Learning and Reasoning
May 31, 2019

Deep learning is bringing remarkable contributions to the field of argumentation mining, but the existing approaches still need to fill the gap towards performing advanced reasoning tasks. We illustrate how neural-symbolic and statistical relational learning could play a crucial role in the integration of symbolic and sub-symbolic methods to achieve this goal.
Attention, please! A Critical Review of Neural Attention Models in Natural Language Processing
Feb 04, 2019

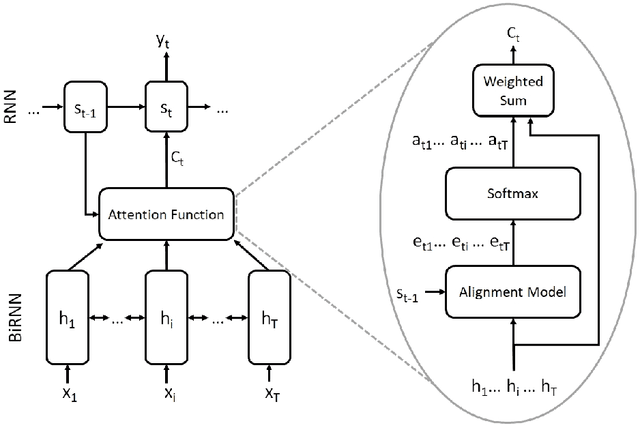
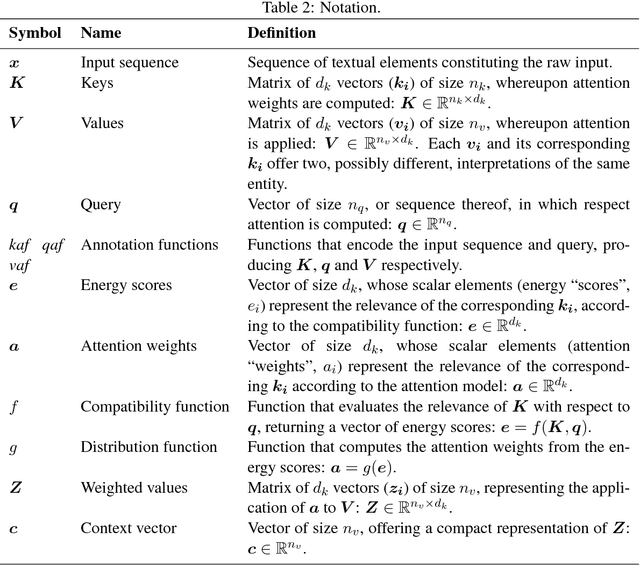
Attention is an increasingly popular mechanism used in a wide range of neural architectures. Because of the fast-paced advances in this domain, a systematic overview of attention is still missing. In this article, we define a unified model for attention architectures for natural language processing, with a focus on architectures designed to work with vector representation of the textual data. We discuss the dimensions along which proposals differ, the possible uses of attention, and chart the major research activities and open challenges in the area.