 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
LMAC-TD: Producing Time Domain Explanations for Audio Classifiers
Sep 13, 2024



Neural networks are typically black-boxes that remain opaque with regards to their decision mechanisms. Several works in the literature have proposed post-hoc explanation methods to alleviate this issue. This paper proposes LMAC-TD, a post-hoc explanation method that trains a decoder to produce explanations directly in the time domain. This methodology builds upon the foundation of L-MAC, Listenable Maps for Audio Classifiers, a method that produces faithful and listenable explanations. We incorporate SepFormer, a popular transformer-based time-domain source separation architecture. We show through a user study that LMAC-TD significantly improves the audio quality of the produced explanations while not sacrificing from faithfulness.
Promoting Fairness and Diversity in Speech Datasets for Mental Health and Neurological Disorders Research
Jun 06, 2024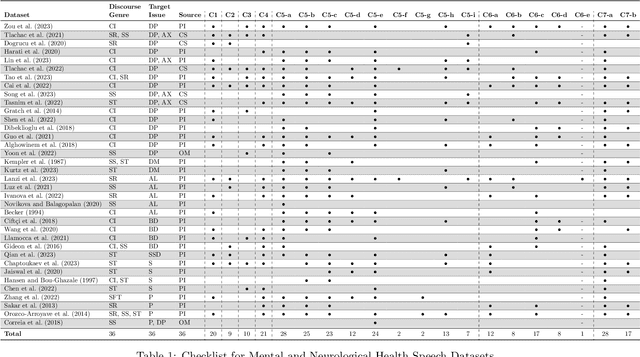
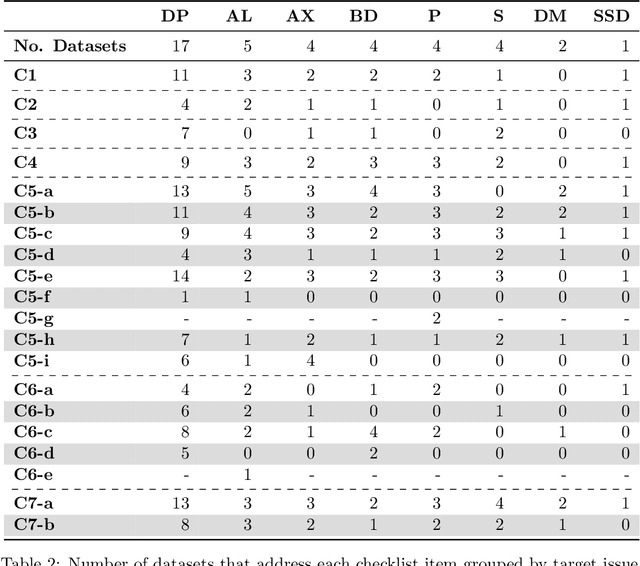
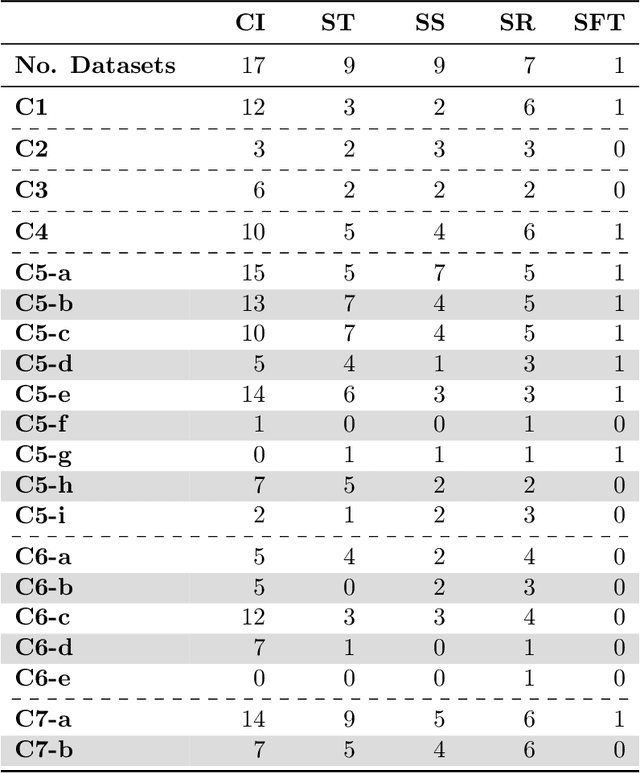
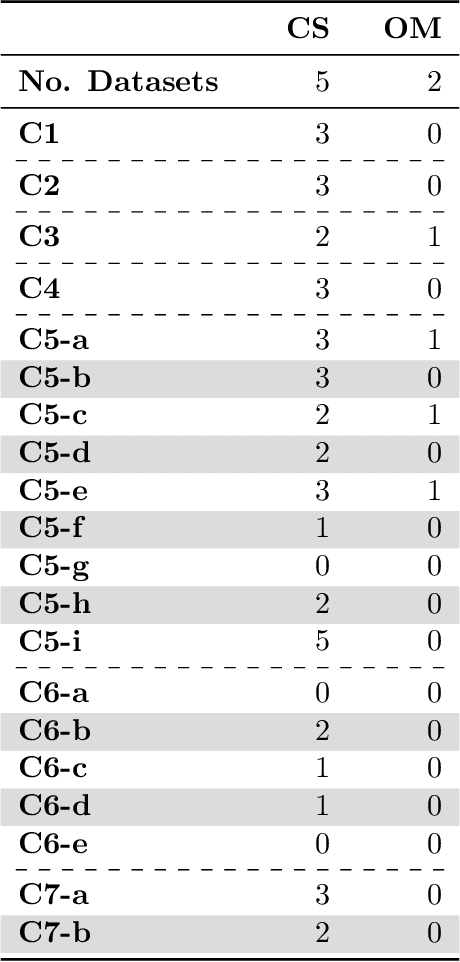
Current research in machine learning and artificial intelligence is largely centered on modeling and performance evaluation, less so on data collection. However, recent research demonstrated that limitations and biases in data may negatively impact trustworthiness and reliability. These aspects are particularly impactful on sensitive domains such as mental health and neurological disorders, where speech data are used to develop AI applications aimed at improving the health of patients and supporting healthcare providers. In this paper, we chart the landscape of available speech datasets for this domain, to highlight possible pitfalls and opportunities for improvement and promote fairness and diversity. We present a comprehensive list of desiderata for building speech datasets for mental health and neurological disorders and distill it into a checklist focused on ethical concerns to foster more responsible research.