 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexIO: Flexible Single- and Multi-Channel Speech Separation and Enhancement
Oct 24, 2025Speech separation and enhancement (SSE) has advanced remarkably and achieved promising results in controlled settings, such as a fixed number of speakers and a fixed array configuration. Towards a universal SSE system, single-channel systems have been extended to deal with a variable number of speakers (i.e., outputs). Meanwhile, multi-channel systems accommodating various array configurations (i.e., inputs) have been developed. However, these attempts have been pursued separately. In this paper, we propose a flexible input and output SSE system, named FlexIO. It performs conditional separation using prompt vectors, one per speaker as a condition, allowing separation of an arbitrary number of speakers. Multi-channel mixtures are processed together with the prompt vectors via an array-agnostic channel communication mechanism. Our experiments demonstrate that FlexIO successfully covers diverse conditions with one to five microphones and one to three speakers. We also confirm the robustness of FlexIO on CHiME-4 real data.
FasTUSS: Faster Task-Aware Unified Source Separation
Jul 15, 2025Time-Frequency (TF) dual-path models are currently among the best performing audio source separation network architectures, achieving state-of-the-art performance in speech enhancement, music source separation, and cinematic audio source separation. While they are characterized by a relatively low parameter count, they still require a considerable number of operations, implying a higher execution time. This problem is exacerbated by the trend towards bigger models trained on large amounts of data to solve more general tasks, such as the recently introduced task-aware unified source separation (TUSS) model. TUSS, which aims to solve audio source separation tasks using a single, conditional model, is built upon TF-Locoformer, a TF dual-path model combining convolution and attention layers. The task definition comes in the form of a sequence of prompts that specify the number and type of sources to be extracted. In this paper, we analyze the design choices of TUSS with the goal of optimizing its performance-complexity trade-off. We derive two more efficient models, FasTUSS-8.3G and FasTUSS-11.7G that reduce the original model's operations by 81\% and 73\% with minor performance drops of 1.2~dB and 0.4~dB averaged over all benchmarks, respectively. Additionally, we investigate the impact of prompt conditioning to derive a causal TUSS model.
A probabilistic framework for dynamic quantization
May 15, 2025
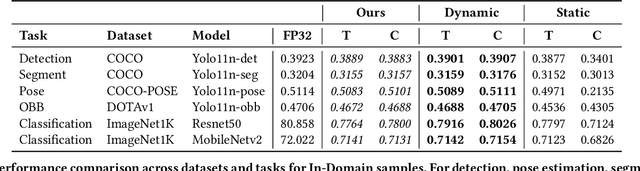

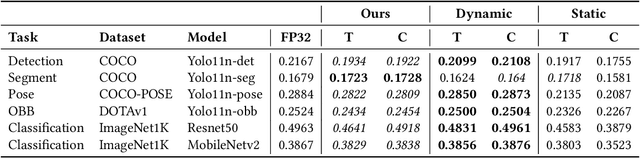
We propose a probabilistic framework for dynamic quantization of neural networks that allows for a computationally efficient input-adaptive rescaling of the quantization parameters. Our framework applies a probabilistic model to the network's pre-activations through a lightweight surrogate, enabling the adaptive adjustment of the quantization parameters on a per-input basis without significant memory overhead. We validate our approach on a set of popular computer vision tasks and models, observing only a negligible loss in performance. Our method strikes the best performance and computational overhead tradeoff compared to standard quantization strategies.
From Vision to Sound: Advancing Audio Anomaly Detection with Vision-Based Algorithms
Feb 25, 2025Recent advances in Visual Anomaly Detection (VAD) have introduced sophisticated algorithms leveraging embeddings generated by pre-trained feature extractors. Inspired by these developments, we investigate the adaptation of such algorithms to the audio domain to address the problem of Audio Anomaly Detection (AAD). Unlike most existing AAD methods, which primarily classify anomalous samples, our approach introduces fine-grained temporal-frequency localization of anomalies within the spectrogram, significantly improving explainability. This capability enables a more precise understanding of where and when anomalies occur, making the results more actionable for end users. We evaluate our approach on industrial and environmental benchmarks, demonstrating the effectiveness of VAD techniques in detecting anomalies in audio signals. Moreover, they improve explainability by enabling localized anomaly identification, making audio anomaly detection systems more interpretable and practical.
FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks
Feb 06, 2025



Large language models have revolutionized natural language processing through self-supervised pretraining on massive datasets. Inspired by this success, researchers have explored adapting these methods to speech by discretizing continuous audio into tokens using neural audio codecs. However, existing approaches face limitations, including high bitrates, the loss of either semantic or acoustic information, and the reliance on multi-codebook designs when trying to capture both, which increases architectural complexity for downstream tasks. To address these challenges, we introduce FocalCodec, an efficient low-bitrate codec based on focal modulation that utilizes a single binary codebook to compress speech between 0.16 and 0.65 kbps. FocalCodec delivers competitive performance in speech resynthesis and voice conversion at lower bitrates than the current state-of-the-art, while effectively handling multilingual speech and noisy environments. Evaluation on downstream tasks shows that FocalCodec successfully preserves sufficient semantic and acoustic information, while also being well-suited for generative modeling. Demo samples, code and checkpoints are available at https://lucadellalib.github.io/focalcodec-web/.
PaSTe: Improving the Efficiency of Visual Anomaly Detection at the Edge
Oct 15, 2024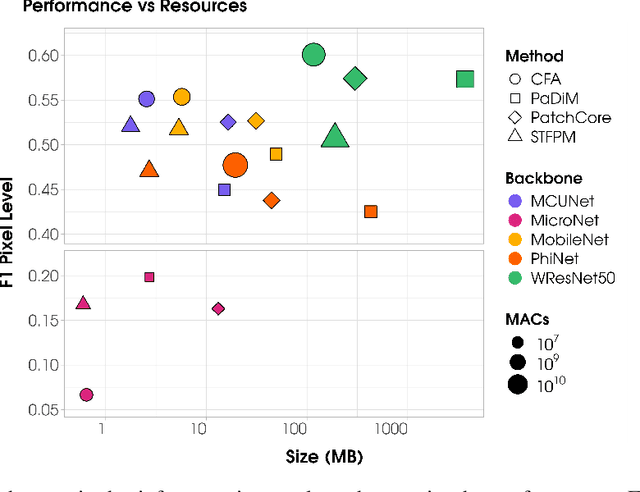
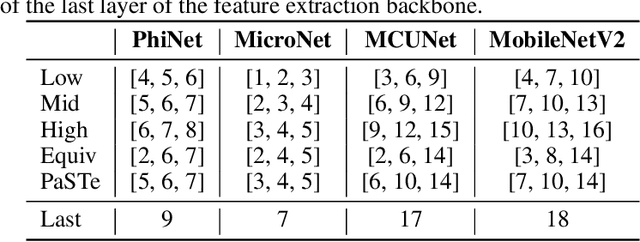
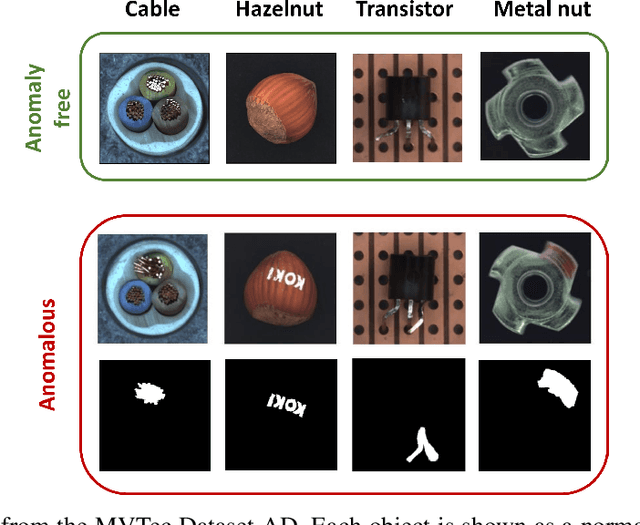
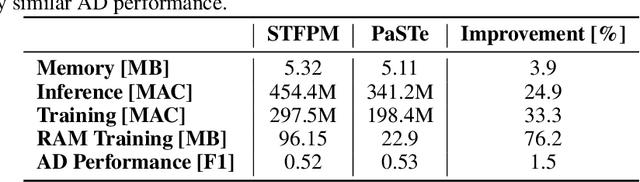
Visual Anomaly Detection (VAD) has gained significant research attention for its ability to identify anomalous images and pinpoint the specific areas responsible for the anomaly. A key advantage of VAD is its unsupervised nature, which eliminates the need for costly and time-consuming labeled data collection. However, despite its potential for real-world applications, the literature has given limited focus to resource-efficient VAD, particularly for deployment on edge devices. This work addresses this gap by leveraging lightweight neural networks to reduce memory and computation requirements, enabling VAD deployment on resource-constrained edge devices. We benchmark the major VAD algorithms within this framework and demonstrate the feasibility of edge-based VAD using the well-known MVTec dataset. Furthermore, we introduce a novel algorithm, Partially Shared Teacher-student (PaSTe), designed to address the high resource demands of the existing Student Teacher Feature Pyramid Matching (STFPM) approach. Our results show that PaSTe decreases the inference time by 25%, while reducing the training time by 33% and peak RAM usage during training by 76%. These improvements make the VAD process significantly more efficient, laying a solid foundation for real-world deployment on edge devices.
LMAC-TD: Producing Time Domain Explanations for Audio Classifiers
Sep 13, 2024



Neural networks are typically black-boxes that remain opaque with regards to their decision mechanisms. Several works in the literature have proposed post-hoc explanation methods to alleviate this issue. This paper proposes LMAC-TD, a post-hoc explanation method that trains a decoder to produce explanations directly in the time domain. This methodology builds upon the foundation of L-MAC, Listenable Maps for Audio Classifiers, a method that produces faithful and listenable explanations. We incorporate SepFormer, a popular transformer-based time-domain source separation architecture. We show through a user study that LMAC-TD significantly improves the audio quality of the produced explanations while not sacrificing from faithfulness.
Replay Consolidation with Label Propagation for Continual Object Detection
Sep 09, 2024


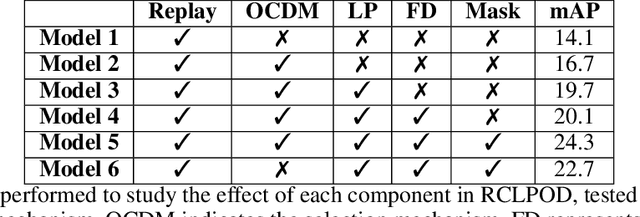
Object Detection is a highly relevant computer vision problem with many applications such as robotics and autonomous driving. Continual Learning~(CL) considers a setting where a model incrementally learns new information while retaining previously acquired knowledge. This is particularly challenging since Deep Learning models tend to catastrophically forget old knowledge while training on new data. In particular, Continual Learning for Object Detection~(CLOD) poses additional difficulties compared to CL for Classification. In CLOD, images from previous tasks may contain unknown classes that could reappear labeled in future tasks. These missing annotations cause task interference issues for replay-based approaches. As a result, most works in the literature have focused on distillation-based approaches. However, these approaches are effective only when there is a strong overlap of classes across tasks. To address the issues of current methodologies, we propose a novel technique to solve CLOD called Replay Consolidation with Label Propagation for Object Detection (RCLPOD). Based on the replay method, our solution avoids task interference issues by enhancing the buffer memory samples. Our method is evaluated against existing techniques in CLOD literature, demonstrating its superior performance on established benchmarks like VOC and COCO.
Latent Distillation for Continual Object Detection at the Edge
Sep 03, 2024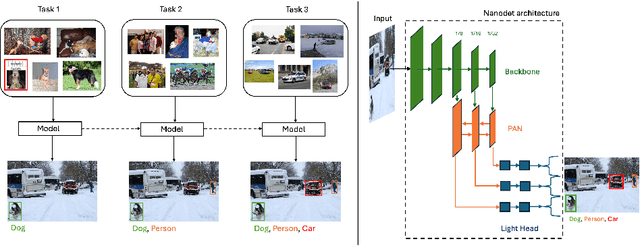
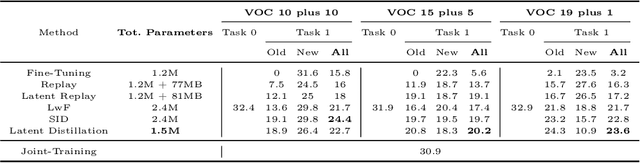
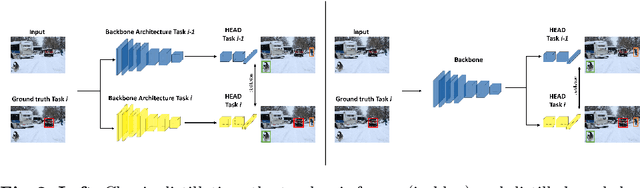
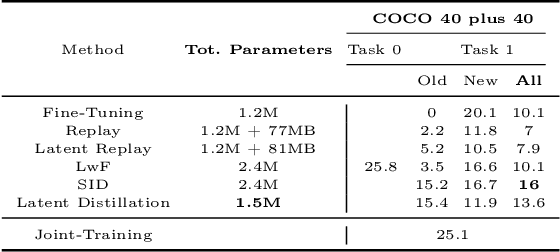
While numerous methods achieving remarkable performance exist in the Object Detection literature, addressing data distribution shifts remains challenging. Continual Learning (CL) offers solutions to this issue, enabling models to adapt to new data while maintaining performance on previous data. This is particularly pertinent for edge devices, common in dynamic environments like automotive and robotics. In this work, we address the memory and computation constraints of edge devices in the Continual Learning for Object Detection (CLOD) scenario. Specifically, (i) we investigate the suitability of an open-source, lightweight, and fast detector, namely NanoDet, for CLOD on edge devices, improving upon larger architectures used in the literature. Moreover, (ii) we propose a novel CL method, called Latent Distillation~(LD), that reduces the number of operations and the memory required by state-of-the-art CL approaches without significantly compromising detection performance. Our approach is validated using the well-known VOC and COCO benchmarks, reducing the distillation parameter overhead by 74\% and the Floating Points Operations~(FLOPs) by 56\% per model update compared to other distillation methods.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024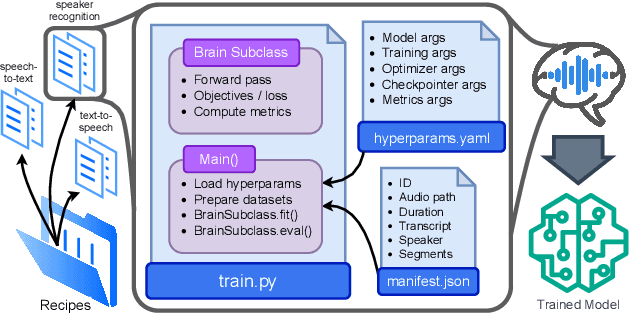

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks